
Heim >Java >javaLernprogramm >Detaillierte Erläuterung, wie LinkedHashMap die Reihenfolge der Elementiteration sicherstellt
Detaillierte Erläuterung, wie LinkedHashMap die Reihenfolge der Elementiteration sicherstellt

- Y2JOriginal
- 2017-05-12 09:38:186490Durchsuche
In diesem Artikel werden hauptsächlich die relevanten Kenntnisse von LinkedHashMap in Java vorgestellt, die einen guten Referenzwert haben. Werfen wir einen Blick mit dem Editor unten
Erste Einführung in LinkedHashMap
In den meisten Fällen kann Map HashMap grundsätzlich verwenden, solange es keine Probleme mit der Thread-Sicherheit gibt. Aber es gibt ein Problem mit HashMap, das heißt, die Reihenfolge, in der HashMap iteriert wird , ist nicht die Reihenfolge, in der HashMap platziert wird , was ungeordnet ist. Dieser Mangel von HashMap verursacht häufig Probleme, da wir in einigen Szenarien eine geordnete Karte erwarten.
LinkedHashMap feiert zu diesem Zeitpunkt sein Debüt, obwohl es den Zeit- und Platzaufwand erhöht, Durch die Verwaltung einer doppelt verknüpften Liste, die für alle Einträge ausgeführt wird, garantiert LinkedHashMap die Reihenfolge der Elementiteration.
Die Antworten auf die vier Anliegen auf LinkedHashMap
| 关 注 点 | 结 论 |
| LinkedHashMap是否允许空 | Key和Value都允许空 |
| LinkedHashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否线程安全 | 非线程安全 |
Grundstruktur von LinkedHashMap
Über LinkedHashMap möchte ich zwei Punkte erwähnen:
1. LinkedHashMap kann als HashMap+Linked betrachtet werden Liste, das heißt, es verwendet nicht nur HashMap zum Betreiben der Datenstruktur, sondern auch LinkedList, um die Reihenfolge der eingefügten Elemente beizubehalten
2. Die grundlegende Implementierungsidee von LinkedHashMap ist----polymorph. Man kann sagen, dass das Verständnis des Polymorphismus und das anschließende Verständnis des LinkedHashMap-Prinzips mit halbem Aufwand das Doppelte des Ergebnisses erzielen. Umgekehrt kann das Erlernen des LinkedHashMap-Prinzips auch das Verständnis des Polymorphismus fördern und vertiefen.
Warum können wir das sagen? Schauen Sie sich zunächst die Definition von LinkedHashMap an:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
}Sehen Sie, LinkedHashMap ist eine Unterklasse von HashMap, daher wird LinkedHashMap natürlich erben Alle nicht privaten Methoden in HashMap. Werfen wir einen Blick auf die Methoden in LinkedHashMap:
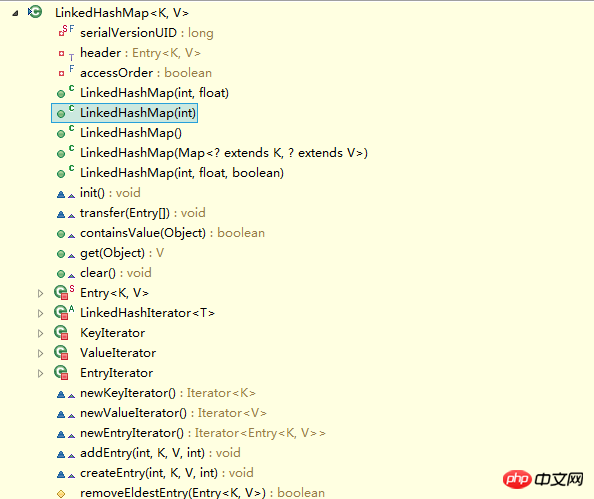
Wir sehen, dass es in LinkedHashMap keine Methoden zum Betreiben von Datenstrukturen gibt, was bedeutet, dass LinkedHashMap auf Datenstrukturen (z. B Die Methode zum Bearbeiten von Daten ist genau die gleiche wie bei HashMap, es gibt jedoch einige Unterschiede im Detail.
Der Unterschied zwischen LinkedHashMap und HashMap liegt in ihrer grundlegenden Datenstruktur. Schauen Sie sich die grundlegende Datenstruktur von LinkedHashMap an:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}Listen Sie einige der Einträge in Entry auf Attribute :
K-Taste
V-Wert
Eintragb56561a2c0bc639cf0044c0859afb88f weiter
-
int hash
Eintragb56561a2c0bc639cf0044c0859afb88f vor
Eintragb56561a2c0bc639cf0044c0859afb88f nach
next wird verwendet, um die Reihenfolge der verbundenen Einträge an der angegebenen Tabellenposition von HashMap beizubehalten. before und After werden verwendet, um die Reihenfolge der Eintragseinfügung beizubehalten.
Lassen Sie uns ein Diagramm verwenden, um es darzustellen und die Attribute aufzulisten: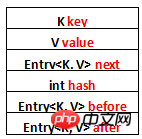
LinkedHashMap initialisieren
Angenommen, es gibt so einen Code:public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}Zuerst kommt in Zeile 3 ~ Zeile 4 eine neue LinkedHashMap heraus, sehen Sie, was gemacht wird: public LinkedHashMap() {
super();
accessOrder = false;
} public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
} void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}/** * The head of the doubly linked list. */ private transient Entry<K,V> header;Der erste Polymorphismus erscheint hier: die init()-Methode. Obwohl die init()-Methode in HashMap definiert ist, überschreibt LinkedHashMap die init-Methode 2, also ist es so tatsächlich aufgerufen Die Init-Methode ist die von LinkedHashMap überschriebene Init-Methode. Angenommen, die Adresse des Headers ist 0x00000000, dann sieht es nach der Initialisierung tatsächlich so aus: LinkedHashMap fügt Elemente hinzu
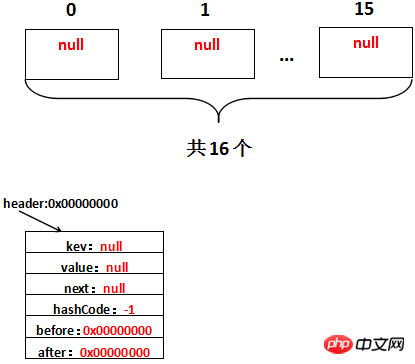
Da LinkedHashMap selbst die Einfügereihenfolge beibehält, kann LinkedHashMap zum
Cachingverwendet werden, Zeilen 5 bis 7 werden zur Unterstützung des FIFO-Algorithmus verwendet, sodass wir uns vorerst keine Sorgen darüber machen müssen. Schauen Sie sich die Methode createEntry an:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}void addEntry(int hash, K key, V value, int bucketIndex) {
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
Der Code in den Zeilen 2–4 unterscheidet sich nicht von HashMap , Das neu hinzugefügte Element wird in Tabelle [i] platziert. Der Unterschied besteht darin, dass LinkedHashMap auch die addBefore-Operation ausführt. Die Bedeutung dieser vier Codezeilen besteht darin, eine doppelt verknüpfte Liste zwischen dem neuen Eintrag und der ursprünglichen verknüpften Liste zu generieren. Wenn Sie mit dem Quellcode von LinkedList vertraut sind, sollte es nicht schwer sein, ihn zu verstehen. Beachten Sie, dass „existingEntry“ den Header darstellt:
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000
2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此时是0x00000000,因此新增的Entry的before=0x00000000
3、before.after=this,新增的Entry的before此时为0x00000000即header,header的after=this,即header的after=0x00000001
4、after.before=this,新增的Entry的after此时为0x00000000即header,header的before=this,即header的before=0x00000001
这样,header与新增的Entry的一个双向链表就形成了。再看,新增了字符串222之后是什么样的,假设新增的Entry的地址为0x00000002,生成到table[2]上,用图表示是这样的:

就不细解释了,只要before、after清除地知道代表的是哪个Entry的就不会有什么问题。
总得来看,再说明一遍,LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。
利用LinkedHashMap实现LRU算法缓存
前面讲了LinkedHashMap添加元素,删除、修改元素就不说了,比较简单,和HashMap+LinkedList的删除、修改元素大同小异,下面讲一个新的内容。
LinkedHashMap可以用来作缓存,比方说LRUCache,看一下这个类的代码,很简单,就十几行而已:
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}顾名思义,LRUCache就是基于LRU算法的Cache(缓存),这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以实现LRU算法的缓存基于两点:
1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致
2、LinkedList提供了一个boolean值可以让用户指定是否实现LRU
那么,首先我们了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。
我们看一下LinkedList带boolean型参数的构造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}就是这个accessOrder,它表示:
(1)false,所有的Entry按照插入的顺序排列
(2)true,所有的Entry按照访问的顺序排列
第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。
"访问",这个词有两层意思:
1、根据Key拿到Value,也就是get方法
2、修改Key对应的Value,也就是put方法
首先看一下get方法,它在LinkedHashMap中被重写:
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}然后是put方法,沿用父类HashMap的:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}修改数据也就是第6行~第14行的代码。看到两端代码都有一个共同点:都调用了recordAccess方法,且这个方法是Entry中的方法,也就是说每次的recordAccess操作的都是某一个固定的Entry。
recordAccess,顾名思义,记录访问,也就是说你这次访问了双向链表,我就把你记录下来,怎么记录?把你访问的Entry移到尾部去。这个方法在HashMap中是一个空方法,就是用来给子类记录访问用的,看一下LinkedHashMap中的实现:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}private void remove() {
before.after = after;
after.before = before;
}private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}看到每次recordAccess的时候做了两件事情:
1、把待移动的Entry的前后Entry相连
2、把待移动的Entry移动到尾部
当然,这一切都是基于accessOrder=true的情况下。最后用一张图表示一下整个recordAccess的过程吧:

代码演示LinkedHashMap按照访问顺序排序的效果
最后代码演示一下LinkedList按照访问顺序排序的效果,验证一下上一部分LinkedHashMap的LRU功能:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>(16, 0.75f, true);
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
linkedHashMap.put("333", "333");
linkedHashMap.put("444", "444");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.get("111");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.put("222", "2222");
loopLinkedHashMap(linkedHashMap);
}
public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
Set<Map.Entry<String, String>> set = inkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = set.iterator();
while (iterator.hasNext())
{
System.out.print(iterator.next() + "\t");
}
System.out.println();
}注意这里的构造方法要用三个参数那个且最后的要传入true,这样才表示按照访问顺序排序。看一下代码运行结果:
111=111 222=222 333=333 444=444 222=222 333=333 444=444 111=111 333=333 444=444 111=111 222=2222
代码运行结果证明了两点:
1、LinkedList是有序的
2、每次访问一个元素(get或put),被访问的元素都被提到最后面去了
【相关推荐】
1. Java免费视频教程
2. 全面解析Java注解
3. Java教程手册
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung, wie LinkedHashMap die Reihenfolge der Elementiteration sicherstellt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- ## So erstellen Sie Rich-Word-Dokumente in Java: OpenOffice UNO im Vergleich zu anderen Optionen?
- Implizites vs. explizites Warten in Selenium: Wann sollten Sie sich für explizites Warten entscheiden?
- Wie können Java-Assertions die Codequalität verbessern und Fehler verhindern?
- Beeinflusst die Deklaration von Strings als „final' in Java „=='-Vergleiche?
- Wann und warum sollten Sie den „instanceof'-Operator von Java verwenden?