
Heim >Backend-Entwicklung >Python-Tutorial >Beispiel für das Parsen einer XML-Datei in Python (Bild)
Beispiel für das Parsen einer XML-Datei in Python (Bild)

- PHPzOriginal
- 2017-04-23 16:44:513383Durchsuche
Verwenden Sie das Modul xml.etree.ElementTree wie folgt, um XML-Dateien zu analysieren. Das ElementTree-Modul stellt zwei Klassen bereit, um diesen Zweck zu erreichen:
ElementTree repräsentiert die gesamte XML-Datei (eine Baumstruktur)
Element stellt ein Element (Knoten) im Baum dar
Wir betreiben die folgende XML-Datei: migapp.xml

Wir können das ElementTree-Modul wie folgt importieren: import xml.etree.ElementTree as ET
Oder wir können nur den Parse-Parser importieren: from xml.etree.ElementTree import parse
Zuerst müssen Sie eine XML-Datei öffnen. Wenn es sich um eine Internetdatei handelt, verwenden Sie urlopen:
f = open( ' migapp.xml ' , ' rt ' , binding = ' utf -8 ' )
Dann analysieren Sie das XML.
1 XML-Datei analysieren
1.1 Stammelement analysieren
tree = ET.parse(f) root = tree.getroot() print('root.tag =', root.tag) print('root.attrib =', root.attrib)

1.2 Stammelement analysieren Söhne von
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict
1.3 Nachkommen der Wurzel nach Index auflösen
print(root[1][1].tag) print(root[1][1].text)

1.4 Alle angegebenen Elemente iterativ analysieren
for element in root.iter('environment'):
print(element.attrib)

1.5 Mehrere nützliche Methoden
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name'))
2 XML-Datei ändern
Angenommen, wir müssen jedem Textelement ein Attribut size="50" hinzufügen und seinen Text in „Benxin Tuzi“ ändern ein untergeordnetes Element date="2016/01/16"
for text in root.iter('text'):
text.set('size', '50')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')migapp.xml Teil in:
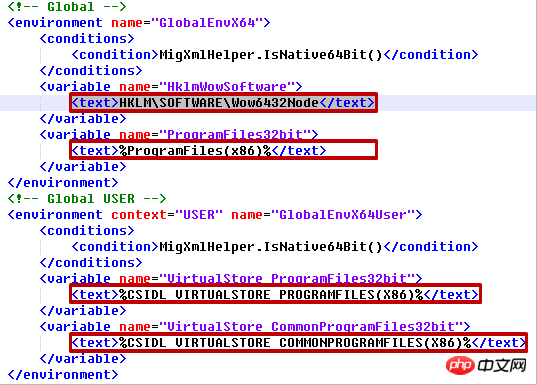
output.xml:
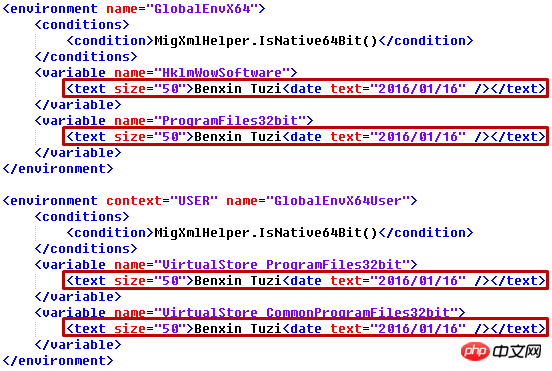
- Verwenden Sie nicht xml als Datei Name, andernfalls tritt der folgende Fehler auf:
Dies liegt daran, dass beim Importieren zunächst im aktuellen Pfad gesucht wird. Zu diesem Zeitpunkt wird festgestellt, dass das xml.py-Modul vorhanden ist und die von uns selbst geschriebene xml.py natürlich kein Paket ist
Hinweis: Wenn xml.py nach dem Löschen immer noch nicht erfolgreich interpretiert werden kann, liegt das daran, dass xml.pyc ebenfalls im aktuellen Pfad generiert wird und die Priorität dieser Datei höher als xml.py ist , sodass der Interpreter xml.pyc weiterhin Priorität einräumt, sodass die Datei auch gelöscht werden muss, um das Problem erfolgreich zu lösen. Fazit: Versuchen Sie, dass der Dateiname nicht mit dem Paketnamen oder Modulnamen identisch ist, auch wenn Sie das Modul oder Paket nicht im Skript verwenden, da sonst seltsame Fehler auftreten kann auftreten.
- Viele im ElementTree-Modul bereitgestellte Parsing-Funktionen müssen das gesamte XML-Dokument im Voraus in den Speicher einlesen, was für das Parsen großer XML-Dokumente nicht gut ist, insbesondere wenn wir mit dem Lesen beginnen XML im Netzwerk oder in der Pipeline, nicht blockierendes Parsen ist sehr wichtig. An diesem Punkt können wir die XMLPullParse-Klasse im ElementTree-Modul verwenden, um damit umzugehen. Natürlich können wir stattdessen auch iterparse() des ElementTree-Moduls wählen. Diese Methode muss beim Parsen nicht das gesamte große XML in den Speicher einlesen.
Das obige ist der detaillierte Inhalt vonBeispiel für das Parsen einer XML-Datei in Python (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!