
Heim >Backend-Entwicklung >Python-Tutorial >Beispiel für einen automatischen IP-Proxy in der Python-Crawling-Technologie
Beispiel für einen automatischen IP-Proxy in der Python-Crawling-Technologie

- Y2JOriginal
- 2017-04-21 15:22:592314Durchsuche
Vor kurzem habe ich vor, weiche Prüfungsfragen für die Prüfung zu crawlen. Beim Crawlen sind einige Probleme aufgetreten. Der folgende Artikel stellt hauptsächlich die Verwendung von Python zum Crawlen weicher Prüfungsfragen und die relevanten Informationen des automatischen IP-Proxys vor. Der Artikel stellt es ausführlich vor. Freunde, die es brauchen, können unten einen Blick darauf werfen.
Vorwort
Zur besseren Prüfung und Vorbereitung gibt es seit Kurzem eine Prüfung auf Software-Professional-Ebene, im Folgenden als Soft-Prüfung bezeichnet Für die Prüfung habe ich vor, www.Soft-Testfragen auf rkpass.cn zu besorgen.
Lassen Sie mich zunächst die Geschichte (keng) erzählen, wie ich die weichen Prüfungsfragen gecrawlt habe. Jetzt kann ich automatisch alle Fragen in einem bestimmten Modul erfassen, wie unten gezeigt:
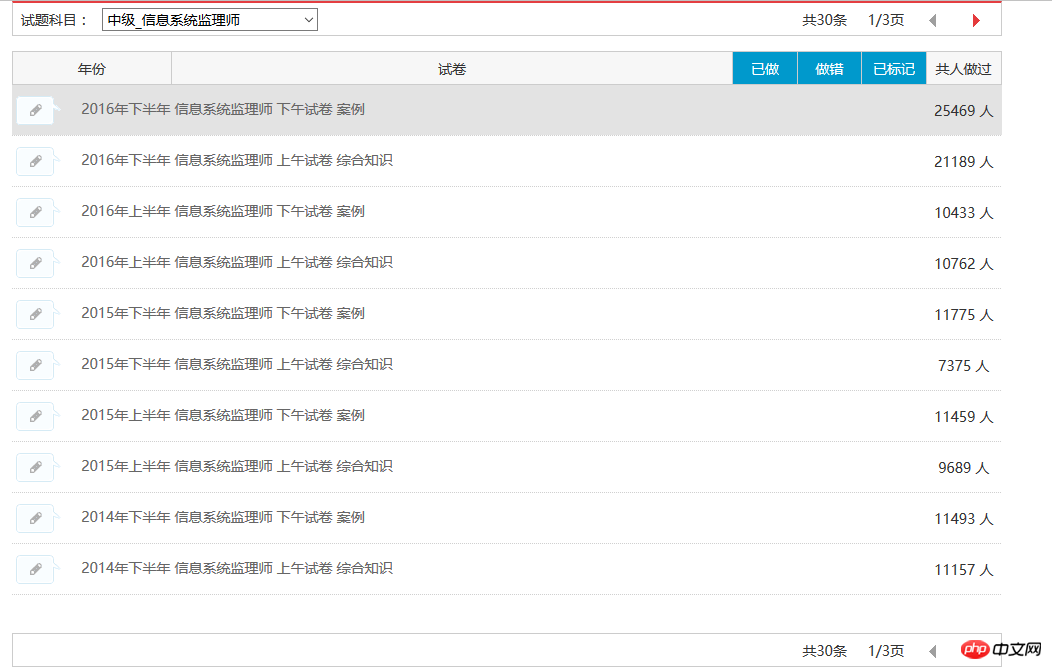
Derzeit kann ich alle 30 Testfragendatensätze des Informationssystem-Supervisors erfassen ist wie unten dargestellt:
Das erfasste Inhaltsbild:

Es können zwar einige Informationen erfasst werden, jedoch die Qualität Der Code ist nicht hoch. Da das Ziel klar ist und die Parameter klar sind, habe ich gestern keine Ausnahmebehandlung durchgeführt Ich habe nachts lange Zeit das Loch zugeschüttet.
Zurück zum Thema, ich schreibe heute diesen Blog, weil ich auf eine neue Falle gestoßen bin. Aus dem Titel des Artikels können wir schließen, dass es zu viele Anfragen gegeben haben muss, sodass die IP durch den Anti-Crawler-Mechanismus der Website blockiert wurde.
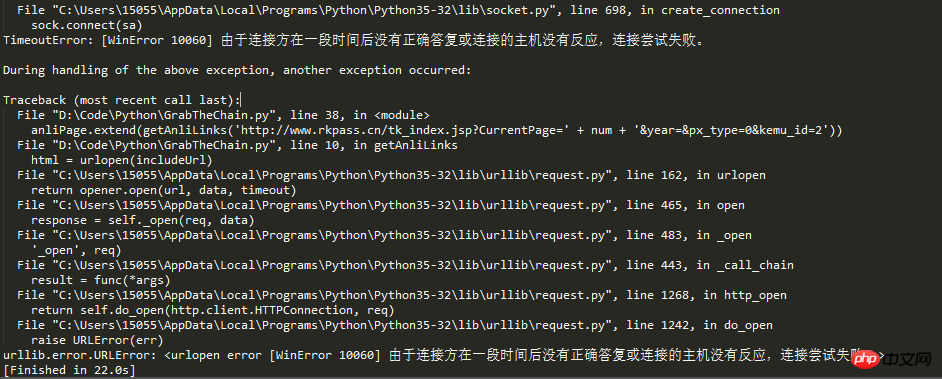
Ein lebender Mensch kann nicht an Urin sterben. Die Taten unserer revolutionären Vorfahren sagen uns, dass wir als Nachfolger des Sozialismus nicht den Schwierigkeiten nachgeben, Straßen über Berge öffnen und bauen können Brücken über Flüsse: Um das IP-Problem zu lösen, entstand die Idee eines IP-Proxys.
Wenn während der Erfassung von Informationen durch Webcrawler die Crawling-Häufigkeit den festgelegten Schwellenwert der Website überschreitet, wird der Zugriff gesperrt. Normalerweise identifiziert der Anti-Crawler-Mechanismus der Website Crawler anhand der IP.
Daher müssen Crawler-Entwickler normalerweise zwei Methoden anwenden, um dieses Problem zu lösen:
1 Verlangsamen Sie die Crawling-Geschwindigkeit und reduzieren Sie sie der Druck auf die Zielwebsite. Dadurch wird jedoch die Crawling-Menge pro Zeiteinheit reduziert.
2. Die zweite Methode besteht darin, den Anti-Crawler-Mechanismus zu durchbrechen und das Hochfrequenz-Crawling fortzusetzen, indem Proxy-IP und andere Mittel festgelegt werden. Dies erfordert jedoch mehrere stabile Proxy-IPs.
Da gibt es nicht viel zu sagen, gehen wir direkt zum Code:
# IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)Screenshot der Laufergebnisse:
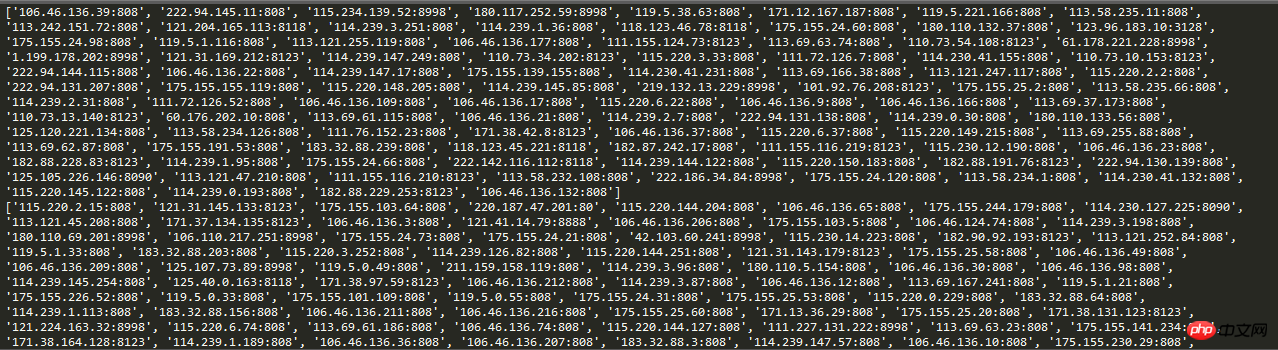
Hier Wenn der Crawler eine Anfrage stellt, kann durch Festlegen der Anforderungs-IP auf automatische IP das einfache Blockieren und die feste IP im Anti-Crawler-Mechanismus effektiv vermieden werden.
---------------- ------ -------------------------------------------- ------ ---------------------------------------
Für die Stabilität der Website sollte jeder die Geschwindigkeit des Crawlers unter Kontrolle halten, schließlich ist es auch für Webmaster nicht einfach. Der Test in diesem Artikel erfasste nur 17 Seiten mit IPs.
Zusammenfassung
Das obige ist der detaillierte Inhalt vonBeispiel für einen automatischen IP-Proxy in der Python-Crawling-Technologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!