
Heim >Backend-Entwicklung >PHP-Tutorial >深入理解PHP之数组(遍历顺序) Laruence原创_php技巧
深入理解PHP之数组(遍历顺序) Laruence原创_php技巧

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-17 09:10:401192Durchsuche
经常会有人问我, PHP的数组, 如果用foreach来访问, 遍历的顺序是固定的么? 以什么顺序遍历呢?
比如:
复制代码 代码如下:
$arr['laruence'] = 'huixinchen';
$arr['yahoo'] = 2007;
$arr['baidu'] = 2008;
foreach ($arr as $key => $val) {
//结果是什么?
}
又比如:
复制代码 代码如下:
$arr[2] = 'huixinchen';
$arr[1] = 2007;
$arr[0] = 2008;
foreach ($arr as $key => $val) {
//现在结果又是什么?
}
要完全了解清楚这个问题, 我想首先应该要大家了解PHP数组的内部实现结构………
PHP的数组
在PHP中, 数组是用一种HASH结构(HashTable)来实现的, PHP使用了一些机制, 使得可以在O(1)的时间复杂度下实现数组的增删, 并同时支持线性遍历和随机访问.
之前的文章中也讨论过, PHP的HASH算法, 基于此, 我们做进一步的延伸.
认识HashTable之前, 首先让我们看看HashTable的结构定义, 我加了注释方便大家理解:
复制代码 代码如下:
typedef struct _hashtable {
uint nTableSize; /* 散列表大小, Hash值的区间 */
uint nTableMask; /* 等于nTableSize -1, 用于快速定位 */
uint nNumOfElements; /* HashTable中实际元素的个数 */
ulong nNextFreeElement; /* 下个空闲可用位置的数字索引 */
Bucket *pInternalPointer; /* 内部位置指针, 会被reset, current这些遍历函数使用 */
Bucket *pListHead; /* 头元素, 用于线性遍历 */
Bucket *pListTail; /* 尾元素, 用于线性遍历 */
Bucket **arBuckets; /* 实际的存储容器 */
dtor_func_t pDestructor;/* 元素的析构函数(指针) */
zend_bool persistent;
unsigned char nApplyCount; /* 循环遍历保护 */
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;
关于nApplyCount的意义, 我们可以通过一个例子来了解:
复制代码 代码如下:
$arr = array(1,2,3,4,5,);
$arr[] = &$arr;
var_export($arr); //Fatal error: Nesting level too deep - recursive dependency?
这个字段就是为了防治循环引用导致的无限循环而设立的.
查看上面的结构, 可以看出, 对于HashTable, 关键元素就是arBuckets了, 这个是实际存储的容器, 让我们来看看它的结构定义:
复制代码 代码如下:
typedef struct bucket {
ulong h; /* 数字索引/hash值 */
uint nKeyLength; /* 字符索引的长度 */
void *pData; /* 数据 */
void *pDataPtr; /* 数据指针 */
struct bucket *pListNext; /* 下一个元素, 用于线性遍历 */
struct bucket *pListLast; /* 上一个元素, 用于线性遍历 */
struct bucket *pNext; /* 处于同一个拉链中的下一个元素 */
struct bucket *pLast; /* 处于同一拉链中的上一个元素 */
char arKey[1]; /* 节省内存,方便初始化的技巧 */
} Bucket;
我们注意到, 最后一个元素, 这个是flexible array技巧, 可以节省内存,和方便初始化的一种做法, 有兴趣的朋友可以google flexible array.
h是元素的Hash值,对于数字索引的元素,h为直接索引值(通过nKeyLength=0来表示是数字索引).而对于字符串索引来说, 索引值保存在arKey中, 索引的长度保存在nKeyLength中.
在Bucket中,实际的数据是保存在pData指针指向的内存块中,通常这个内存块是系统另外分配的。但有一种情况例外,就是当Bucket保存 的数据是一个指针时,HashTable将不会另外请求系统分配空间来保存这个指针,而是直接将该指针保存到pDataPtr中,然后再将pData指向本结构成员的地址。这样可以提高效率,减少内存碎片。由此我们可以看到PHP HashTable设计的精妙之处。如果Bucket中的数据不是一个指针,pDataPtr为NULL(本段来自Altair的”Zend HashTable详解”)
结合上面的HashTable结构, 我们来说明下HashTable的总结构图:
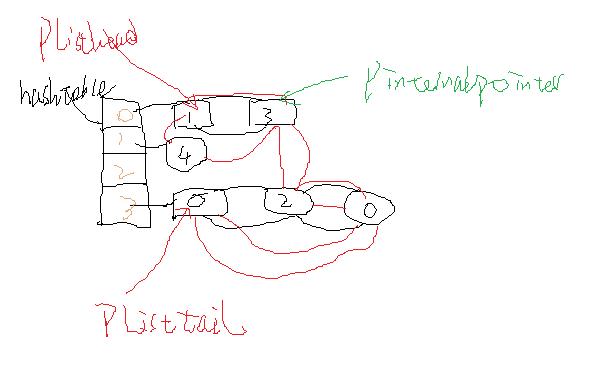
HashTable的pListhHead指向线性列表形式下的第一个元素, 上图中是元素1, pListTail指向的是最后一个元素0, 而对于每一个元素pListNext就是红色线条画出的线性结构的下一个元素, 而pListLast是上一个元素.
pInternalPointer指向当前的内部指针的位置, 在对数组进行顺序遍历的时候, 这个指针指明了当前的元素.
当在线性(顺序)遍历的时候, 就会从pListHead开始, 顺着Bucket中的pListNext/pListLast, 根据移动pInternalPointer, 来实现对所有元素的线性遍历.
比如, 对于foreach, 如果我们查看它生成的opcode序列, 我们可以发现, 在foreach之前, 会首先有个FE_RESET来重置数组的内部指针, 也就是pInternalPointer(关于foreach可以参看深入理解PHP原理之foreach), 然后通过每次FE_FETCH来递增pInternalPointer,从而实现顺序遍历.
类似的, 当我们使用, each/next系列函数来遍历的时候, 也是通过移动数组的内部指针而实现了顺序遍历, 这里有一个问题, 比如:
复制代码 代码如下:
$arr = array(1,2,3,4,5);
foreach ($arr as $v) {
//可以获取
}
while (list($key, $v) = each($arr)) {
//获取不到
}
?>
了解到我刚才介绍的知识, 那么这个问题也就很明朗了, 因为foreach会自动reset, 而while这块不会reset, 所以在foreach结束以后, pInternalPointer指向数组最末端, while语句块当然访问不到了, 解决的办法就是在each之前, 先reset数组的内部指针.
而在随机访问的时候, 就会通过hash值确定在hash数组中的头指针位置, 然后通过pNext/pLast来找到特点元素.
增加元素的时候, 元素会插在相同Hash元素链的头部和线性列表的尾部. 也就是说, 元素在线性遍历的时候是根据插入的先后顺序来遍历的, 这个特殊的设计使得在PHP中,当使用数字索引时, 元素的先后顺序是由添加的顺序决定的,而不是索引顺序.
也就是说, PHP中遍历数组的顺序, 是和元素的添加先后相关的, 那么, 现在我们就很清楚的知道, 文章开头的问题的输出是:
复制代码 代码如下:
huixinchen
2007
2008
所以, 如果你想在数字索引的数组中按照索引大小遍历, 那么你就应该使用for, 而不是foreach
复制代码 代码如下:
for($i=0,$l=count($arr); $i//这个时候,不能认为是顺序遍历(线性遍历)
}
原文:http://www.laruence.com/2009/08/23/1065.html
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:SESSION信息保存在哪个文件目录下以及能够用来保存什么类型的数据_php技巧Nächster Artikel:php 对输入信息的进行安全过滤的函数代码_php技巧
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)