
Heim >Datenbank >MySQL-Tutorial >Detaillierte Erklärung des Unterschieds zwischen Redis und Memcached
Detaillierte Erklärung des Unterschieds zwischen Redis und Memcached
- 巴扎黑Original
- 2017-04-08 10:37:041222Durchsuche
Salvatore Sanfilippo, der Autor von Redis, hat einmal diese beiden speicherbasierten Datenspeichersysteme verglichen:
Redis unterstützt serverseitige Datenoperationen: Im Vergleich zu Memcached verfügt Redis über mehr Datenstrukturen und unterstützt umfangreichere Datenoperationen. Normalerweise müssen Sie in Memcached die Daten an den Client übertragen, um ähnliche Änderungen vorzunehmen, und diese dann zurücksetzen. Dadurch erhöht sich die Anzahl der Netzwerk-IOs und das Datenvolumen erheblich. In Redis sind diese komplexen Vorgänge normalerweise genauso effizient wie normales GET/SET. Wenn Sie also den Cache benötigen, um komplexere Strukturen und Vorgänge zu unterstützen, ist Redis eine gute Wahl.
Vergleich der Speichernutzungseffizienz: Wenn eine einfache Schlüsselwertspeicherung verwendet wird, hat Memcached eine höhere Speicherauslastung. Wenn Redis eine Hash-Struktur für die Schlüsselwertspeicherung verwendet, ist die Speicherauslastung aufgrund der kombinierten Komprimierung höher.
Leistungsvergleich: Da Redis nur einen einzelnen Kern verwendet, während Memcached im Durchschnitt mehrere Kerne verwenden kann, weist Redis beim Speichern kleiner Daten auf jedem Kern eine höhere Leistung als Memcached auf. Bei Daten von mehr als 100.000 ist die Leistung von Memcached höher als die von Redis. Obwohl Redis kürzlich für die Leistung beim Speichern großer Datenmengen optimiert wurde, ist es Memcached immer noch etwas unterlegen.
Im Einzelnen, warum die obige Schlussfolgerung zustande kam, sind die folgenden gesammelten Informationen:
1. Unterstützt verschiedene Datentypen
Im Gegensatz zu Memcached, das nur Datensätze mit einfachen Schlüsselwertstrukturen unterstützt, unterstützt Redis viel umfangreichere Datentypen. Es gibt fünf am häufigsten verwendete Datentypen: String, Hash, List, Set und Sorted Set. Redis verwendet intern ein redisObject-Objekt, um alle Schlüssel und Werte darzustellen. Die Hauptinformationen von redisObject sind in der Abbildung dargestellt:

Typ stellt den spezifischen Datentyp eines Wertobjekts dar, und Codierung ist die Art und Weise, wie verschiedene Datentypen in Redis gespeichert werden. Beispiel: Typ=String stellt dar, dass der Wert als gewöhnlicher String gespeichert wird und die entsprechende Codierung unformatiert oder int sein kann. Wenn es int ist, bedeutet dies, dass die tatsächliche Zeichenfolge in Redis intern als numerische Klasse gespeichert und dargestellt wird. Voraussetzung ist natürlich, dass die Zeichenfolge selbst durch einen numerischen Wert dargestellt werden kann, z. B. „123“ „456“. solche Saiten. Nur wenn die virtuelle Speicherfunktion von Redis aktiviert ist, weist das VM-Feld tatsächlich Speicher zu. Diese Funktion ist standardmäßig deaktiviert.
1) Zeichenfolge
Häufig verwendete Befehle: set/get/decr/incr/mget usw.;
Anwendungsszenarien: String ist der am häufigsten verwendete Datentyp, und die gewöhnliche Schlüssel-/Wertspeicherung kann in diese Kategorie eingeordnet werden Implementierungsmethode: Die Zeichenfolge wird standardmäßig in Redis gespeichert und von redisObject referenziert. Bei Vorgängen wie incr, decr wird sie zur Berechnung in einen numerischen Wert konvertiert int.
2) Hash
Häufig verwendete Befehle: hget/hset/hgetall usw.
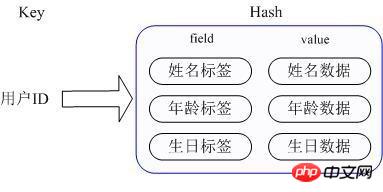
Anwendungsszenario: Wir möchten Benutzerinformationsobjektdaten speichern, zu denen Benutzer-ID, Benutzername, Alter und Geburtstag gehören. Über die Benutzer-ID hoffen wir, den Namen, das Alter oder den Geburtstag des Benutzers zu erhalten
- Implementierungsmethode: Der Hash von Redis speichert den Wert tatsächlich intern als HashMap und bietet eine Schnittstelle für den direkten Zugriff auf die Mitglieder dieser Map. Wie in der Abbildung gezeigt, ist der Schlüssel die Benutzer-ID und der Wert eine Karte. Der Schlüssel dieser Karte ist der Attributname des Mitglieds und der Wert ist der Attributwert. Auf diese Weise können Daten direkt über den Schlüssel ihrer internen Karte geändert und darauf zugegriffen werden (der Schlüssel der internen Karte wird in Redis als Feld bezeichnet), d. h. die entsprechenden Attributdaten können über Schlüssel (Benutzer-ID) + Feld manipuliert werden (Attributbezeichnung). Derzeit gibt es zwei Möglichkeiten, HashMap zu implementieren: Wenn es relativ wenige Mitglieder von HashMap gibt, verwendet Redis eine eindimensionale Array-ähnliche Methode, um es kompakt zu speichern, um Speicher zu sparen, anstatt die echte HashMap-Struktur zu verwenden , die Codierung des redisObject des entsprechenden Werts ist zipmap. Wenn die Anzahl der Mitglieder zunimmt, wird es automatisch in eine echte HashMap konvertiert und die Codierung ist ht.
3) Liste
Häufig verwendete Befehle: lpush/rpush/lpop/rpop/lrange usw.; Anwendungsszenarien: Es gibt viele Anwendungsszenarien für die Redis-Liste, und sie ist auch eine der wichtigsten Datenstrukturen von Redis. Beispielsweise können Twitters Follow-Liste, Fan-Liste usw. mithilfe der Redis-Listenstruktur implementiert werden 🎜>
-
4)Einstellen
Häufig verwendete Befehle: sadd/spop/smembers/sunion usw.;
-
Anwendungsszenarien: Die von Redis bereitgestellten externen Funktionen ähneln denen von list. Die Besonderheit besteht darin, dass set automatisch Duplikate entfernen muss nützliches Tool. Eine gute Auswahl, und Set bietet eine wichtige Schnittstelle, um festzustellen, ob sich ein Mitglied in einer Set-Sammlung befindet, die die Liste nicht bereitstellen kann
Implementierungsmethode: Die interne Implementierung von set ist eine HashMap, deren Wert immer null ist. Tatsächlich wird sie durch die Berechnung des Hash schnell sortiert. Aus diesem Grund kann set eine Möglichkeit bieten, festzustellen, ob sich ein Mitglied in der Menge befindet. - 5) Sortiertes Set
- Häufig verwendete Befehle: zadd/zrange/zrem/zcard usw.;
- Anwendungsszenarien: Das Verwendungsszenario des sortierten Satzes von Redis ähnelt dem des Satzes. Der Unterschied besteht darin, dass der Satz nicht automatisch sortiert wird, während der sortierte Satz Mitglieder sortieren kann, indem er einen zusätzlichen Prioritätsparameter (Score) durch den Benutzer bereitstellt und einfügt Reihenfolge. Das heißt, automatische Sortierung. Wenn Sie eine geordnete und nicht duplizierte Set-Liste benötigen, können Sie eine sortierte Set-Datenstruktur wählen. Beispielsweise kann die öffentliche Timeline von Twitter mit der Veröffentlichungszeit als Partitur gespeichert werden, sodass sie beim Abrufen automatisch nach Zeit sortiert wird.
- Implementierungsmethode: Der sortierte Redis-Satz verwendet intern HashMap und SkipList, um die Speicherung und Reihenfolge der Daten von Mitgliedern zu Bewertungen sicherzustellen, während die Sprungliste alle in HashMap gespeicherten Ergebnisse speichert Durch die Verwendung der Sprungtabellenstruktur kann eine relativ hohe Sucheffizienz erzielt werden, und die Implementierung ist relativ einfach.
- 2. Verschiedene Speicherverwaltungsmechanismen
- In Redis werden nicht alle Daten immer im Speicher gespeichert. Dies ist der größte Unterschied im Vergleich zu Memcached. Wenn der physische Speicher erschöpft ist, kann Redis einige Werte, die längere Zeit nicht verwendet wurden, auf die Festplatte übertragen. Redis speichert nur alle Schlüsselinformationen zwischen, wenn Redis feststellt, dass die Speichernutzung einen bestimmten Schwellenwert überschreitet. Redis berechnet, welche Schlüssel dem erforderlichen Wert entsprechen Scheibe. Anschließend werden die diesen Schlüsseln entsprechenden Werte auf der Festplatte gespeichert und im Speicher gelöscht. Mit dieser Funktion kann Redis Daten verwalten, die die Speichergröße seiner Maschine selbst überschreiten. Natürlich muss der Speicher der Maschine selbst alle Schlüssel aufnehmen können, schließlich werden diese Daten nicht ausgetauscht. Wenn Redis gleichzeitig die Daten im Speicher auf die Festplatte auslagert, teilen sich der Haupt-Thread, der den Dienst bereitstellt, und der Unter-Thread, der den Auslagerungsvorgang ausführt, diesen Teil des Speichers, sodass die Daten vorhanden sein müssen Ausgetauscht wird aktualisiert. Redis blockiert den Vorgang, bis der Sub-Thread geändert wird. Änderungen können erst nach Abschluss des Auslagerungsvorgangs vorgenommen werden. Wenn sich beim Lesen von Daten aus Redis der dem Leseschlüssel entsprechende Wert nicht im Speicher befindet, muss Redis die entsprechenden Daten aus der Auslagerungsdatei laden und sie dann an den Anforderer zurückgeben. Hier liegt ein I/O-Thread-Pool-Problem vor. Standardmäßig blockiert Redis, das heißt, es reagiert erst, wenn alle Auslagerungsdateien geladen sind. Diese Strategie eignet sich besser, wenn die Anzahl der Clients gering ist und Batch-Vorgänge ausgeführt werden. Wenn Redis jedoch in einer großen Website-Anwendung angewendet wird, kann dies offensichtlich nicht der Situation einer großen Parallelität gerecht werden. Redis führt uns also aus, um die Größe des E/A-Thread-Pools festzulegen und gleichzeitige Vorgänge für Leseanforderungen auszuführen, die entsprechende Daten aus der Auslagerungsdatei laden müssen, um die Blockierungszeit zu reduzieren.
Memcached verwendet standardmäßig den Slab Allocation-Mechanismus zur Speicherverwaltung. Die Hauptidee besteht darin, den zugewiesenen Speicher entsprechend der vorgegebenen Größe in Blöcke mit bestimmten Längen zu unterteilen, um Schlüsselwertdatensätze mit entsprechenden Längen zu speichern und das Problem der Speicherfragmentierung vollständig zu lösen. Der Slab Allocation-Mechanismus dient nur zum Speichern externer Daten. Dies bedeutet, dass alle Schlüsselwertdaten im Slab Allocation-System gespeichert werden, während andere Speicheranforderungen für Memcached über gewöhnliches Malloc/Free beantragt werden, da die Anzahl dieser Anforderungen und Die Häufigkeit bestimmt, dass sie die Leistung des gesamten Systems nicht beeinträchtigen. Das Prinzip der Slab Allocation ist recht einfach. Wie in der Abbildung gezeigt, beantragt es zunächst einen großen Speicherblock vom Betriebssystem, unterteilt ihn in Blöcke unterschiedlicher Größe und unterteilt Blöcke derselben Größe in Gruppen von Slab-Klassen. Unter diesen ist Chunk die kleinste Einheit, die zum Speichern von Schlüsselwertdaten verwendet wird. Die Größe jeder Slab-Klasse kann durch Angabe des Wachstumsfaktors beim Start von Memcached gesteuert werden. Nehmen Sie an, dass der Wert des Wachstumsfaktors in der Abbildung 1,25 beträgt. Wenn die Größe der ersten Gruppe von Chunks 88 Byte beträgt, beträgt die Größe der zweiten Gruppe von Chunks 112 Byte und so weiter.
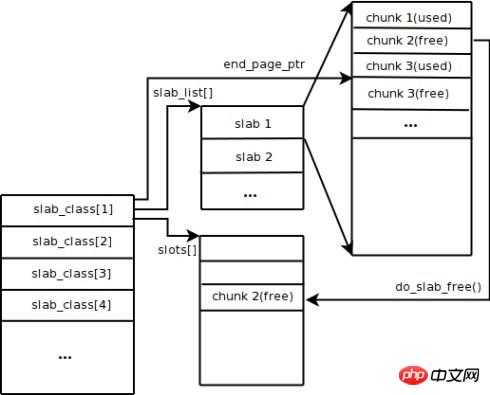
Wenn Memcached die vom Client gesendeten Daten empfängt, wählt es zunächst die am besten geeignete Slab-Klasse basierend auf der Größe der empfangenen Daten aus und fragt dann die von Memcached gespeicherte Liste der freien Blöcke in der Slab-Klasse ab, um eine Slab-Klasse zu finden, die dies kann zur Speicherung der Daten verwendet werden. Wenn ein Datenbankeintrag abläuft oder verworfen wird, kann der vom Datensatz belegte Chunk recycelt und erneut zur Liste der freien Einträge hinzugefügt werden. Aus dem obigen Prozess können wir ersehen, dass das Speicherverwaltungssystem von Memcached hocheffizient ist und keine Speicherfragmentierung verursacht, sein größter Nachteil jedoch darin besteht, dass es zu einer Platzverschwendung führt. Da jedem Chunk eine bestimmte Länge an Speicherplatz zugewiesen ist, können Daten variabler Länge diesen Speicherplatz nicht vollständig nutzen. Wie in der Abbildung dargestellt, werden 100 Byte Daten in einem 128-Byte-Block zwischengespeichert und die restlichen 28 Byte werden verschwendet.

Die Speicherverwaltung von Redis wird hauptsächlich über die beiden Dateien Detaillierte Erklärung des Unterschieds zwischen Redis und Memcached.h und Detaillierte Erklärung des Unterschieds zwischen Redis und Memcached.c im Quellcode implementiert. Um die Speicherverwaltung zu erleichtern, speichert Redis die Größe dieses Speichers im Kopf des Speicherblocks, nachdem ein Teil des Speichers zugewiesen wurde. Wie in der Abbildung gezeigt, ist real_ptr der Zeiger, den Redis nach dem Aufruf von malloc zurückgibt. Redis speichert die Größe des Speicherblocks im Header. Die von size belegte Speichergröße ist die Länge des Typs size_t und gibt dann ret_ptr zurück. Wenn Speicher freigegeben werden muss, wird ret_ptr an den Speichermanager übergeben. Über ret_ptr kann das Programm einfach den Wert von real_ptr berechnen und dann real_ptr an free übergeben, um den Speicher freizugeben.

Redis zeichnet alle Speicherzuweisungen auf, indem es ein Array definiert. Die Länge dieses Arrays beträgt ZMALLOC_MAX_ALLOC_STAT. Jedes Element des Arrays stellt die Anzahl der vom aktuellen Programm zugewiesenen Speicherblöcke dar, und die Größe des Speicherblocks ist der Index des Elements. Im Quellcode lautet dieses Array Detaillierte Erklärung des Unterschieds zwischen Redis und Memcached_allocations. Detaillierte Erklärung des Unterschieds zwischen Redis und Memcached_allocations[16] stellt die Anzahl der zugewiesenen Speicherblöcke mit einer Länge von 16 Bytes dar. In Detaillierte Erklärung des Unterschieds zwischen Redis und Memcached.c gibt es eine statische Variable used_memory, um die Gesamtgröße des aktuell zugewiesenen Speichers aufzuzeichnen. Daher verwendet Redis im Allgemeinen das gepackte Mallc/Free, was viel einfacher ist als die Speicherverwaltungsmethode von Memcached.
3. Unterstützung der Datenpersistenz
Obwohl Redis ein speicherbasiertes Speichersystem ist, unterstützt es selbst die Persistenz von Speicherdaten und bietet zwei Hauptpersistenzstrategien: RDB-Snapshots und AOF-Protokolle. Memcached unterstützt keine Datenpersistenzvorgänge.
1) RDB-Snapshot
Redis unterstützt einen Persistenzmechanismus, der einen Snapshot der aktuellen Daten in einer Datendatei, also einem RDB-Snapshot, speichert. Doch wie erzeugt eine kontinuierlich schreibende Datenbank Snapshots? Redis verwendet den Copy-on-Write-Mechanismus des fork-Befehls. Beim Generieren eines Snapshots wird der aktuelle Prozess in einen untergeordneten Prozess gespalten, und dann werden alle Daten im untergeordneten Prozess zirkuliert und die Daten werden in eine RDB-Datei geschrieben. Wir können den Zeitpunkt der RDB-Snapshot-Generierung über den Speicherbefehl von Redis konfigurieren. Beispielsweise können wir den Snapshot so konfigurieren, dass er nach 10 Minuten generiert wird, oder wir können ihn so konfigurieren, dass nach 1.000 Schreibvorgängen ein Snapshot generiert wird, oder wir können mehrere Regeln zusammen implementieren. Die Definition dieser Regeln befindet sich in der Redis-Konfigurationsdatei. Sie können die Regeln auch festlegen, während Redis über den Redis-Befehl CONFIG SET ausgeführt wird, ohne Redis neu zu starten.
Die RDB-Datei von Redis wird nicht beschädigt, da der Schreibvorgang in einem neuen Prozess ausgeführt wird. Wenn eine neue RDB-Datei generiert wird, schreibt der von Redis generierte Unterprozess die Daten zunächst in eine temporäre Datei und verwendet sie dann atomar Der Systemaufruf benennt die temporäre Datei in eine RDB-Datei um, sodass die Redis RDB-Datei immer verfügbar ist, wenn zu irgendeinem Zeitpunkt ein Fehler auftritt. Gleichzeitig ist die RDB-Datei von Redis auch Teil der internen Implementierung der Redis-Master-Slave-Synchronisation. RDB hat seine Mängel, das heißt, sobald ein Problem mit der Datenbank auftritt, sind die in unserer RDB-Datei gespeicherten Daten nicht ganz neu. Alle Daten von der letzten RDB-Dateigenerierung bis zum Herunterfahren von Redis gehen verloren. In manchen Betrieben ist dies tolerierbar.
2) AOF-Protokoll
Der vollständige Name des AOF-Protokolls lautet „Nur Append-Datei“, bei der es sich um eine durch Anhängen geschriebene Protokolldatei handelt. Im Gegensatz zum Binlog allgemeiner Datenbanken handelt es sich bei AOF-Dateien um identifizierbaren Klartext, und ihr Inhalt besteht aus Redis-Standardbefehlen nacheinander. Nur Befehle, die eine Änderung der Daten bewirken, werden an die AOF-Datei angehängt. Jeder Befehl zum Ändern von Daten generiert ein Protokoll und die AOF-Datei wird immer größer, sodass Redis eine weitere Funktion namens AOF-Rewrite bereitstellt. Seine Funktion besteht darin, eine AOF-Datei neu zu generieren. In der neuen AOF-Datei gibt es nur eine Operation für einen Datensatz, im Gegensatz zu einer alten Datei, in der möglicherweise mehrere Operationen für denselben Wert aufgezeichnet werden. Der Generierungsprozess ähnelt RDB. Außerdem wird ein Prozess gegabelt, die Daten werden direkt durchlaufen und eine neue temporäre AOF-Datei geschrieben. Während des Schreibvorgangs einer neuen Datei werden alle Schreibvorgangsprotokolle weiterhin in die ursprüngliche alte AOF-Datei geschrieben und auch im Speicherpuffer aufgezeichnet. Wenn der Redundanzvorgang abgeschlossen ist, werden alle Protokolle im Puffer auf einmal in die temporäre Datei geschrieben. Rufen Sie dann den Befehl zum atomaren Umbenennen auf, um die alte AOF-Datei durch die neue AOF-Datei zu ersetzen.
AOF ist ein Dateischreibvorgang. Sein Zweck besteht darin, das Vorgangsprotokoll auf die Festplatte zu schreiben, sodass auch der oben erwähnte Schreibvorgang auftritt. Verwenden Sie nach dem Aufruf von write auf AOF in Redis die Option appendfsync, um die Zeit zu steuern, die zum Aufrufen von fsync zum Schreiben auf die Festplatte benötigt wird. Die Sicherheitsstärke der folgenden drei Einstellungen von appendfsync wird allmählich stärker.
appendfsync no Wenn appendfsync auf no gesetzt ist, ruft Redis fsync nicht aktiv auf, um den AOF-Protokollinhalt mit der Festplatte zu synchronisieren, sodass dies alles vollständig vom Debuggen des Betriebssystems abhängt. Bei den meisten Linux-Betriebssystemen wird fsync alle 30 Sekunden ausgeführt, um die Daten im Puffer auf die Festplatte zu schreiben.
appendfsync everysec Wenn appendfsync auf everysec eingestellt ist, führt Redis standardmäßig jede Sekunde einen fsync-Aufruf durch, um die Daten im Puffer auf die Festplatte zu schreiben. Aber wenn dieser fsync-Aufruf länger als 1 Sekunde dauert. Redis wird die Strategie übernehmen, fsync zu verzögern und eine weitere Sekunde zu warten. Das heißt, fsync wird nach zwei Sekunden ausgeführt, unabhängig davon, wie lange die Ausführung dauert. Da der Dateideskriptor zu diesem Zeitpunkt während fsync blockiert wird, wird der aktuelle Schreibvorgang blockiert. Die Schlussfolgerung ist also, dass Redis in den meisten Fällen fsync jede Sekunde durchführt. Im schlimmsten Fall findet alle zwei Sekunden ein fsync-Vorgang statt. Dieser Vorgang wird in den meisten Datenbanksystemen als Gruppenfestschreibung bezeichnet. Er kombiniert die Daten mehrerer Schreibvorgänge und schreibt das Protokoll auf einmal auf die Festplatte.
appednfsync immer Wenn appendfsync auf immer eingestellt ist, wird fsync bei jedem Schreibvorgang einmal aufgerufen. Da fsync zu diesem Zeitpunkt jedes Mal ausgeführt wird, wird dies natürlich auch beeinträchtigt.
Für allgemeine Geschäftsanforderungen wird die Verwendung von RDB für die Persistenz empfohlen. Der Grund dafür ist, dass der Overhead von RDB viel geringer ist als der von AOF-Protokollen. Für Anwendungen, die keinen Datenverlust tolerieren, wird die Verwendung von AOF-Protokollen empfohlen.
4. Unterschiede im Clustermanagement
Memcached ist ein Datenpufferungssystem mit vollem Speicher. Obwohl Redis die Datenpersistenz unterstützt, ist der volle Speicher der Kern seiner hohen Leistung. Da es sich um ein speicherbasiertes Speichersystem handelt, ist die Größe des physischen Speichers der Maschine die maximale Datenmenge, die das System aufnehmen kann. Wenn die zu verarbeitende Datenmenge die physische Speichergröße einer einzelnen Maschine übersteigt, muss ein verteilter Cluster erstellt werden, um die Speicherkapazitäten zu erweitern.
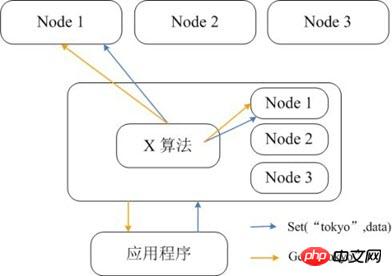
Memcached selbst unterstützt keine Verteilung, daher kann der verteilte Speicher von Memcached nur über verteilte Algorithmen wie konsistentes Hashing auf dem Client implementiert werden. Die folgende Abbildung zeigt die verteilte Speicherimplementierungsarchitektur von Memcached. Bevor der Client Daten an den Memcached-Cluster sendet, wird zunächst der Zielknoten der Daten über den integrierten verteilten Algorithmus berechnet und dann werden die Daten zur Speicherung direkt an den Knoten gesendet. Wenn der Client jedoch Daten abfragt, muss er auch den Knoten berechnen, auf dem sich die Abfragedaten befinden, und dann direkt eine Abfrageanforderung an den Knoten senden, um die Daten abzurufen.
Im Vergleich zu Memcached, das den Client nur zum Implementieren verteilten Speichers verwenden kann, bevorzugt Redis den Aufbau verteilten Speichers auf der Serverseite. Die neueste Version von Redis unterstützt bereits verteilte Speicherfunktionen. Redis Cluster ist eine erweiterte Version von Redis, die die Verteilung implementiert und einzelne Fehlerpunkte zulässt. Es verfügt über keinen zentralen Knoten und ist linear skalierbar. Die folgende Abbildung zeigt die verteilte Speicherarchitektur des Redis-Clusters, in der Knoten über das Binärprotokoll miteinander kommunizieren und zwischen Knoten und Clients über das ASCII-Protokoll kommunizieren. In Bezug auf die Datenplatzierungsstrategie unterteilt Redis Cluster das gesamte Schlüsselwertfeld in 4096 Hash-Slots, und jeder Knoten kann einen oder mehrere Hash-Slots speichern. Das heißt, die maximale Anzahl von Knoten, die derzeit von Redis Cluster unterstützt werden, beträgt 4096. Der von Redis Cluster verwendete verteilte Algorithmus ist ebenfalls sehr einfach: crc16(key) % HASH_SLOTS_NUMBER.
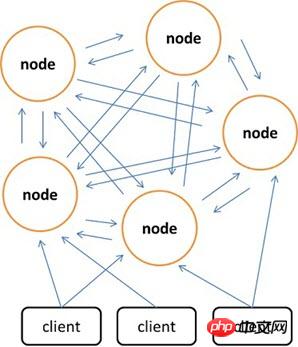
Um die Datenverfügbarkeit bei Single Point of Failure sicherzustellen, führt Redis Cluster einen Master-Knoten und einen Slave-Knoten ein. Im Redis-Cluster verfügt jeder Master-Knoten aus Redundanzgründen über zwei entsprechende Slave-Knoten. Auf diese Weise führt die Ausfallzeit zweier beliebiger Knoten im gesamten Cluster nicht zu einer Nichtverfügbarkeit der Daten. Wenn der Master-Knoten beendet wird, wählt der Cluster automatisch einen Slave-Knoten aus, der zum neuen Master-Knoten wird.
Das obige ist der detaillierte Inhalt vonDetaillierte Erklärung des Unterschieds zwischen Redis und Memcached. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!