
Heim >Web-Frontend >HTML-Tutorial >Parsen des DOM in HTML
Parsen des DOM in HTML

- 怪我咯Original
- 2017-04-07 10:13:062571Durchsuche
[Einführung] DOM ist etwas, mit dem sich alle Front-End-Entwickler täglich beschäftigen, aber mit dem Aufkommen von Bibliotheken wie jQuery wurden die DOM-Operationen stark vereinfacht, was dazu führte, dass jeder langsam sein ursprüngliches Erscheinungsbild „vergessen“ hat. Wenn Sie jedoch tiefgehendes Front-End-Wissen erlernen möchten, ist das Verständnis von DOM unerlässlich. Daher ist dieser Artikel bestrebt, das relevante Wissen über DOM systematisch zu erläutern. Wenn es Auslassungen oder Fehler gibt, weisen Sie diese bitte darauf hin und diskutieren Sie diese gemeinsam .
DOM ist etwas, mit dem sich alle Front-End-Entwickler täglich beschäftigen, aber mit dem Aufkommen von Bibliotheken wie jQuery wurden die DOM-Operationen stark vereinfacht, was dazu führte, dass jeder langsam sein ursprüngliches Erscheinungsbild „vergessen“ hat. Wenn Sie jedoch tiefgreifende Front-End-Kenntnisse erlernen möchten, ist ein Verständnis von DOM unabdingbar. In diesem Artikel wird daher versucht, das relevante Wissen über DOM systematisch zu erläutern. Wenn es Auslassungen oder Fehler gibt, weisen Sie diese bitte darauf hin und diskutieren Sie diese gemeinsam ^.
1. Was ist DOM?
DOM (Document Object Model) ist eine API für HTML- und XML-Dokumente, die über DOM geändert werden können.
Diese Aussage ist sehr offiziell, aber immer noch nicht jeder versteht sie.
Zum Beispiel: Wir haben ein Stück HTML. Wie greifen wir also auf den ersten Knoten in der zweiten Ebene zu und wie verschieben wir den letzten Knoten auf den ersten Knoten?
DOM definiert den Standard für die Durchführung ähnlicher Vorgänge. Verwenden Sie beispielsweise getElementById, um auf Knoten zuzugreifen, und insertBefore, um Knoten einzufügen.
Wenn der Browser HTML lädt, generiert er den entsprechenden DOM-Baum.
Kurz gesagt kann DOM als Implementierungsstandard für den Zugriff auf oder den Betrieb verschiedener HTML-Tags verstanden werden.
Für ein HTML ist der Dokumentknoten Document (unsichtbar) sein Wurzelknoten, und das entsprechende Objekt ist das Dokumentobjekt ( Streng genommen ist es ist eine Unterklasse des HTMLDocument-Objekts, wie unten bei der separaten Einführung des Dokumenttyps erläutert wird.
Mit anderen Worten, es gibt einen Dokumentknoten Document und dann hat er untergeordnete Knoten. Über document.getElementsByTagName("html") können Sie beispielsweise den Element-HTML-Code abrufen Typelementknoten.
Jedes HTML-Tag kann durch einen entsprechenden Knoten dargestellt werden, zum Beispiel:
HTML-Elemente werden durch Elementknoten dargestellt, Kommentare werden durch dargestellt Kommentarknoten, Dokumenttypen werden durch Dokumenttypknoten usw. dargestellt.
Es sind insgesamt 12 Knotentypen definiert, und diese Typen erben alle vom Knotentyp.
Lassen Sie uns also zunächst über den Knotentyp sprechen, da die Methoden dieses Typs von allen Knoten geerbt werden.
2. Knotentyp (Basisklasse, alle Knoten erben ihre Methoden)
Knoten ist der Basistyp aller Knoten, alle Knoten erben davon, also haben alle Knoten einige gängige Methoden und Eigenschaften.
Lass uns zuerst über die Attribute des Knotentyps sprechen
Das erste ist das NodeType-Attribut, das verwendet wird, um den Knotentyp anzugeben, zum Beispiel:
document.nodeType; // 返回 9 ,其中document对象为文档节点Document的实例
Hier stellt 9 den DOCUMENT_NODE-Knoten dar. Sie können die dem Knoten entsprechende Nummer über Node.DOCUMENT_NODE
document.nodeType === Node.DOCUMENT_NODE; // true
Was durch den Aufruf von childNodes zurückgegeben wird, ist ein NodeList-Objekt, das einem Array sehr ähnlich ist, aber es gibt eines, das am kritischsten ist Punkt,
es ist Es wird dynamisch abgefragt, was bedeutet, dass bei jedem Aufruf die DOM-Struktur abgefragt wird. Sie müssen daher bei der Verwendung vorsichtig sein und auf die Leistung achten.
Um auf childNodes zuzugreifen, können Sie die Array-Tabelle unten oder die Item-Methode verwenden Dann verfügt jeder Knoten auch über verschiedene Attribute, die es ihm ermöglichen, aufeinander zuzugreifen. Die folgende Abbildung fasst dies zusammen na ja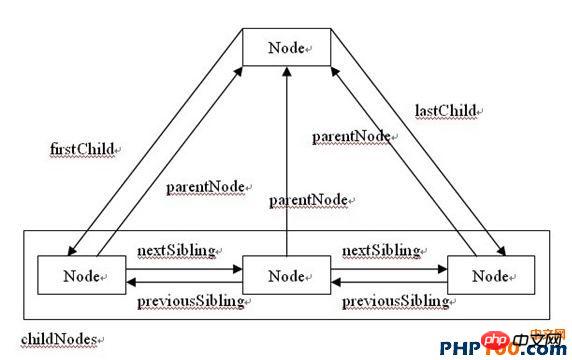
Weitere nützliche Methoden und Attribute:
Gibt „true“ zurück, wenn es untergeordnete Knoten enthält, was einfacher ist als die Abfrage der Länge von untergeordneten Knoten. 2.ownerDocument gibt die Referenz des Dokumentknotens zurück (der auch das Dokumentobjekt in HTML ist)
Lassen Sie es uns noch einmal vorstellen. Häufig verwendete Methoden des Knotentyps
appendChild()-Methode können einen Knoten am Ende der childNodes des Knotens hinzufügen. Es ist erwähnenswert, dass, wenn dieser Knoten bereits im Dokument vorhanden ist, Der ursprüngliche Knoten wird gelöscht. Es fühlt sich an, als würde man den Knotenverschieben. Die Methode insertBefore() akzeptiert zwei Parameter, einer ist der eingefügte Knoten und der andere ist der Referenzknoten. Wenn der zweite Parameter null ist, haben insertBefore und appendChild den gleichen Effekt. Andernfalls wird der Knoten vor dem Referenzknoten eingefügt.
Hier ist zu beachten, dass der eingefügte Knoten kein vorhandener Knoten sein kann, wenn der zweite Parameter nicht null ist.replaceChild()方法可以替换节点,接受两个参数,需要插入的节点和需要替换的节点。返回被替换掉的节点。 removeChild()移除节点。这里有个常见需求,比如我有一个节点 #waste-node ,那么如何移除它呢? 这里先暂停一下,不知道大家注意到没有,以上的几个方法都是操作某个节点的子节点,也就是说,操作前必须找到父节点(通过parentNode来找) 接下来说下复制节点的方法: cloneNode();复制节点,接受一个参数 true或者false。如果true就是复制那个节点和它的子节点。如果是false,就是复制节点本身(复制出来的节点就会没有任何子元素)。这个方法返回复制的节点,如果需要操作它,那么需要借助前面讲的4个方法来把这个节点放入到html中去。 至此,Node类型的常见属性和方法都介绍完了。结合开头讲的,所有节点类型都继承自Node类型,所以这些方法是所有节点都有的。 最开始讲DOM是什么的时候提到了Document类型。其实关于这个类型最重要的是它的一个子类HTMLDocument有一个实例对象document。而这个document对象是我们最常用的一个对象了。 document对象又挂载在window对象上,所以在浏览器就可以直接访问document了。 老规矩,先讲讲document对象的属性,等会讲讲它的方法。 document对象上的一些属性 document.childNodes 继承自上面讲的Node类型,可以返回文档的直接子节点(通常包括文档声明和html节点) document.documentElement 可以直接拿到html节点的引用(等价于document.getElementsByTagName(“html”)[0])。 document.body body节点的引用 document.title 页面的title,可以修改,会改变浏览器标签上的名字 document.URL 页面的url document.referrer 取得referrer,也就是打开这个页面的那个页面的地址,做来源统计时候比较有用 document.domain 取得域名,可以设置,但是通常只能设置为不包含子域名的情况,在一些子域名跨域情况下有效。 接下来介绍两个熟悉的方法 getElementById 和 getElementsByTagName getElementById,传入id,得到元素节点。里面的参数区分大小写(IE8-不区分)。注意:如果有多个id相同的元素,则返回第一个。IE7-里面表单元素的name也会被当做id来使用。 getElementsByTagName 根据标签取得元素,得到的是HTMLCollection类型。如果传入的是 “*” ,则可以取得全部元素。 还有一个是只有HTMLDocument类型(也就是document对象)才有的方法 getElementsByName 顾名思义,根据name返回元素。 document对象还有一些集合,例如document.forms 可以返回所有的form表单。类型也是HTMLCollection。 说到HTMLCollection,就再说说它 HTMLCollection就是一个包含一个或多个元素的集合,和上面讲的NodeList还挺像的。HTMLCollection这个类型有两个方法,一个是通过下标(或者.item())得到具体元素,还有就是通过['name'](或者.namedItem())获得具体元素。 最后,关于document对象还有一套重要的方法,那便是 write() writeln() open() close() open和close分别是打开和关闭网页的输出流,在页面加载过程中,就相当于open状态。这两个方法一般不会去用它。 然后重要的方法就是write和writeln,它们都是向页面写入东西,区别就是后者会多加入一个换行符。 注意的是:在页面加载的过程中,可以使用这两个方法向页面添加内容。如果页面已经加载完了,再调用write,会重写整个页面。 还有一点,如果要动态写入脚本 例如 3f1c4e4b6b16bbbd69b2ee476dc4f83axxx2cacc6d41bbb37262a98f745aa00fbf0这样的 ,那么要注意把2cacc6d41bbb37262a98f745aa00fbf0分开来拼装下,否则会被误以为是脚本结束的标志,导致这个结束符匹配到上面一个开始符。可以这样写”de5bee1f3ad3a6217020d3ed8824abb5”; 接下来讲讲最重要也是最常见的一个类型,Element类型。 我们日常所操作的都是Element类型(实质是HTMLElement,这里为了方便理解,就简单这么说),比如 返回的就是Element类型。我们日常所说的“DOM对象”,通常也就是指Element类型的对象。 然后说说这个类型的常见属性: 首先最开始说的Node类型上的那些属性方法它都有,这个就不再重复了,主要说说它自己独有的。 首先是tagName,这个和继承自Node类型的nodeName一样。都是返回标签名,通常是大写,结果取决于浏览器。所以在做比较 的时候最好是调用下类似toLowerCase()这种方法再做比较。 说说上面提到过的HTMLElement类型 HTMLElement类型继承自Element类型,也是HTML元素的实际类型,我们在浏览器里用的元素都是这个类型。 这个类型都具有一些标准属性,比如: id 元素的唯一标识 title 通常是鼠标移上去时候会显示的信息 className 类名 等等,这几个属性是可读写的,也就是说你改变他们会得到相应的效果。 除了属性外,还有几个重要的方法 首先说说操作节点属性的方法 getAttribute 、setAttribute 、removeAttribute这3个方法。 这些是操作属性最常用的方法了,怎么用就不说了,很简单,顾名思义。 还有一个attributes属性,保存了元素的全部属性。 这里停下来,出个问题,ele.className 和 ele.getAttribute(“class”)返回的结果是不是同一个东西? 解答这个问题,我要说一个重要知识点,一个元素的属性结构是这么来的,比如一个inpnt元素 那么这个元素的属性被包含在 input.attributes里面,比如你在html元素上看到的class、id或者你自己定义的data-test这种属性。 然后 getAttribute 、setAttribute 、removeAttribute这3个方法可以认为是快捷的取attributes集合的方法。而直接input.id或者input.className都是直接挂在input下的属性,和attributes是同级的。所以返回的东西也许看过去一样,实际是不一样的,不信你可以试试input.checked这input.getAttribute(“checked”)试试。 关于这个知识点,详细的说可以再写一篇文章,在我的博客 从is(“:checked”)说起 中有谈到过,大家可以看看这篇文章和文章后的讨论,便可以知道是怎么一回事。 总得来说,这3个方法通常用了处理自定义的属性,而不是id、class等这种“公认特性”。 接下来说说创建元素 document.createElement()可以创建一个元素,比如: 一般之后可以为元素设置属性,两种方法,一种是直接node.property还可以node.setAttribute(“propertyName”,”value”)。等 但是做完这些之后,这个元素还是没有在页面中,所以你还得通过最上面讲的类似appendChild这些方法把元素添加到页面里面。 在IE中,还可以直接穿整个HTML字符串进去,来创建元素,比如 最后,元素节点也支持HTMLDocument类型的那些查找方法,比如getElementsByTagName。不过它只会找自己后代的节点。所以可以这么写代码 这个类型很特殊,也是第三常见类型(第一第二分别就是Document和Element)。 这个节点简单来说就是一段字符串。 有个很重要的特征就是,它没有子元素(不过这个仔细想想也知道= =) 访问text节点的文本内容,可以通过nodeValue或者data属性。 下面简单说说它提供的一些方法 还有insertDate、replaceData、splitText等方法,就不一一说了,用的机会很少,可以用的时候再查阅。 然后它还有一个lenght属性,返回字符长度的。 这里说一个常见的坑。比如下面这个html结构 这里,ul的第一个子节点(firstChild)是什么呢?第一眼看过去,肯定认为是li了,但是实际上,你会发现不是li,而是一个文本节点! 这是因为浏览器认为ul和第一个li之间有空白字符,所以就有文本节点了。 这里一个常见的问题就是遍历ul的childNodes的时候,遍历的元素一定要判断下nodeType是不是等于1(等于1就代表是元素节点),这样才能跳过这个坑。否则你也可以删除所有的空格和换行符。 创建文本节点的方法是document.createTextNode 然后接下来和操作Element类型一样,就是再插入到元素中,浏览器就可以看到了。 这些不常用的一句话带过把 Comment是注释节点 DocumentType就是doctype节点,通过docment.doctype来访问 DocumentFragment这个节点是一个文档片段,偶尔会用到。 比如一种常见的用法是,在一个ul中插入3个li。 如果你循环插入3次,那么浏览器就要渲染3次,对性能有蛮大的影响。 所以大家一般这么做 先 然后循环把li,用appendChild插入到fragment里面 最后在一次把fragment插入到ul里面。这样就会很快。 进过上面讲的这么多节点类型,想必大家对DOM节点已经有了很深的了解,下面讲一讲DOM扩展的一些东西。 浏览器为了方便开发者,扩展了一些DOM功能。 因为是浏览器自己扩展的,所以使用前兼容性问题一定要注意 判断“标准模式”和“混杂模式”通过 document.compatMode和新的document.documentMode 上面不是说了一个文本节点作为第一子元素的坑吗,所以浏览器又实现了一个children属性,这个属性只包含元素节点。 为了方便判断A节点是不是B节点的子节点,引入了contains方法,比如 这个方法有兼容性问题,使用前可以谷歌解决方法。 针对访问元素,又提供了4个方法innerText/innerHTML/outerTEXT/outerHTML。 通过这些方法,可以读和写元素。 其中,*TEXT是返回文本内容 *HTML是返回html文本。 而outer*则是代表是否包含元素本身。 实际使用来看,在读内容的时候 inner*和outer*没有区别。 在把内容写入元素的时候,就是是否包含元素本身的区别。 重要的是,这几个方法有性能问题,比如在IE中,通过inner*删除的节点,其绑定的事件依然在内存中,就很容易消耗大量内存。 还有一个技巧是,插入大量的html代码,用innerHTML是非常快的,建议使用。var wasteNode = document.getElementById("waste-node");
wasteNode.parentNode.removeClhid(wasteNode); // 先拿到父节点,再调用removeClild删除自己
三、Document类型
四、Element类型
document.getElementById("test")<input id="test" checked="checked">
document.createElement("p");document.createElement("<p>test</p>");document.getElementById("test").getElementsByTagName("p"); // 找到id为test元素下的所有p节点五、Text类型
appendData(); // 在text末尾加内容
deleteData(offset, count); // 从offset指定的位置开始删除count个字符
<ul>
<li></li>
<li></li>
</ul>
六、其他的一些类型 Comment、DocumentType和DocumentFragment
var fragment = document.createDocumentFragment();
七、DOM扩展
B.contains(A); // true就代表是,false就代表不是
Das obige ist der detaillierte Inhalt vonParsen des DOM in HTML. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!