
Heim >Datenbank >MySQL-Tutorial >Lösen Sie das SQL-Optimierungsproblem von CBO (ausführliche Erklärung mit Bildern und Texten)
Lösen Sie das SQL-Optimierungsproblem von CBO (ausführliche Erklärung mit Bildern und Texten)

- 怪我咯Original
- 2017-04-05 11:26:336426Durchsuche
Überblick über diese Weitergabe:
Was sind die Fallstricke des CBO-Optimierers?
CBO-Optimierer Lösungen für Fallstricke
Stärken Sie die SQL-Prüfung, um Leistungsprobleme bereits im Anfangsstadium zu verhindern
FAQ vor Ort teilen
Der CBO-Optimierer (Cost Based Optimizer) wird derzeit häufig in Oracle verwendet. Er verwendet statistische Informationen, Abfragekonvertierung usw., um die Kosten verschiedener möglicher Zugriffspfade zu berechnen und schließlich eine Vielzahl alternativer Ausführungspläne zu generieren wählt den Ausführungsplan mit den niedrigsten Kosten als optimalen Ausführungsplan. Im Vergleich zum RBO (Rule Based Optimizer) der „alten“ Ära entspricht es offensichtlich besser der tatsächlichen Situation der Datenbank und kann sich an mehr Anwendungsszenarien anpassen. Aufgrund seiner hohen Komplexität gibt es jedoch viele praktische Probleme und Fehler, die CBO im täglichen Optimierungsprozess nicht gelöst hat, egal wie Sie statistische Informationen sammeln , vielleicht haben Sie CBO betrogen.
In diesem Sharing werden hauptsächlich häufig auftretende tägliche Optimierungsprobleme als Einführung verwendet, um die Lösungen für die Fallstricke von CBO zu erkunden.
1. Was sind die Fallstricke des CBO-Optimierers?
Werfen wir zunächst einen Blick auf die Komponenten des CBO-Optimierers:
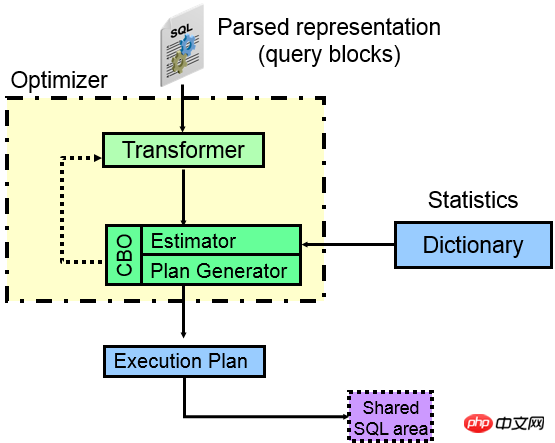
Aus dem Bild oben können Sie ersehen, dass beim Eingeben einer SQL-Anweisung in ORACLE die verschiedenen Teile nach dem Parsen tatsächlich getrennt werden und jeder getrennte Teil unabhängig voneinander zu einem Abfrageblock (Abfrageblock) wird zu einem Abfrageblock wird und eine externe Abfrage zu einem Abfrageblock wird, muss der ORACLE-Optimierer dann tun, welcher Zugriffspfad innerhalb jedes Abfrageblocks besser ist (nehmen Sie Index , vollständige Tabelle, Partition?), und die zweite ist, was zwischen den einzelnen Abfrageblöcken getan werden sollte. Welche JOIN-Methode und JOIN-Reihenfolge werden verwendet, um schließlich zu berechnen, welcher Ausführungsplan besser ist.
Der Kern des Optimierers ist der Abfragekonverter, der Kostenschätzer und der Ausführungsplangenerator.
Transformer (Abfragetransformator):
Wie aus der Abbildung ersichtlich ist, ist das erste Kerngerät des Optimierers der Abfragetransformator. Die Hauptfunktion des Abfragetransformators besteht darin, verschiedene Abfragen zu untersuchen Blöcke Die Beziehung zwischen SQL und SQL ist syntaktisch und sogar semantisch äquivalent. Das umgeschriebene SQL kann vom Kerngerätkostenschätzer und Ausführungsplangenerator einfacher verarbeitet werden, wodurch statistische Informationen zur Generierung des optimalen Ausführungsplans verwendet werden.
Der Abfragekonverter verfügt im Optimierer über zwei Möglichkeiten: heuristische Abfragekonvertierung (regelbasiert) und COST-basierte Abfragekonvertierung. Heuristische Abfragekonvertierungen sind im Allgemeinen relativ einfache Anweisungen, und kostenbasierte Anweisungen sind im Allgemeinen komplexer. Das heißt, ORACLE, das regelbasierten Abfragen entspricht, führt unter allen Umständen eine Abfragekonvertierung durch, und ORACLE, das die Anforderungen nicht erfüllt, kann dies in Betracht ziehen Kostenbasierte Abfragekonvertierung. Die heuristische Abfragekonvertierung hat eine lange Geschichte und weist im Allgemeinen weniger Probleme auf als die kostenbasierte Abfragekonvertierung, da sie eng mit dem CBO-Optimierer zusammenhängt und in 10G eingeführt wurde Daher treten im täglichen Optimierungsprozess häufig verschiedene schwierige SQL-Anweisungen auf, da die Abfragekonvertierung fehlschlägt und Oracle die ursprüngliche SQL nicht in eine besser strukturierte SQL konvertieren kann optimiert werden). (Prozessorverarbeitung) stehen offensichtlich viel weniger Ausführungspfade zur Auswahl. Wenn die Unterabfrage beispielsweise nicht UNNEST sein kann, ist das oft der Beginn einer Katastrophe. Tatsächlich besteht die Hauptaufgabe von Oracle bei der Abfragekonvertierung darin, verschiedene Abfragen in JOIN-Methoden umzuwandeln, sodass verschiedene effiziente JOIN-Methoden wie HASH JOIN verwendet werden können.
Es gibt mehr als 30 Methoden zur Abfragetransformation. Nachfolgend sind einige gängige Heuristiken und COST-basierte Abfragetransformationen aufgeführt.
Heuristische Abfragetransformation (eine Reihe von REGELN):
Viele heuristische Abfragetransformationen existieren bereits im RBO-Fall. Übliche sind:
Simple View Merge (einfache Ansichtszusammenführung), SU (Subquery Unnest Subquery Expansion), OJPPD (Old Style Join Predicate Push-Down, Old Join Predicate Push Method), FPD (Filter Push) -Down Filterprädikat-Push), OR-Erweiterung (OR-Erweiterung), OBYE (Order by Elimination), JE (Join Elimination Connection Elimination oder Table Elimination in the Connection), Transitive Predicate (Prädikatübertragung) und andere Technologien.
COST-basierte Abfragekonvertierung (berechnet durch COST):
COST-basierte Abfragekonvertierung für komplexe Anweisungen, häufige Beispiele sind:
CVM (Complex View Merging) Zusammenführen von Ansichten ), JPPD (Join Predicate Push-Down), DP (Distinct Placement), GBP (Group by Placement) und andere Technologien.
Durch eine Reihe von Abfragekonvertierungstechnologien wird das ursprüngliche SQL in SQL konvertiert, das für den Optimierer leichter zu verstehen und zu analysieren ist, sodass mehr Prädikate, Verbindungsbedingungen usw. verwendet werden können, um den Zweck zu erreichen den besten Plan erhalten. Um den Konvertierungsprozess abzufragen, erhalten Sie detaillierte Informationen unter 10053. Ob die Abfragekonvertierung erfolgreich sein kann, hängt von der Version, Optimierungseinschränkungen, impliziten Parametern, Patches usw. ab.
Suchen Sie einfach nach der Abfragekonvertierung auf MOS, und es werden eine Reihe von Fehlern angezeigt:
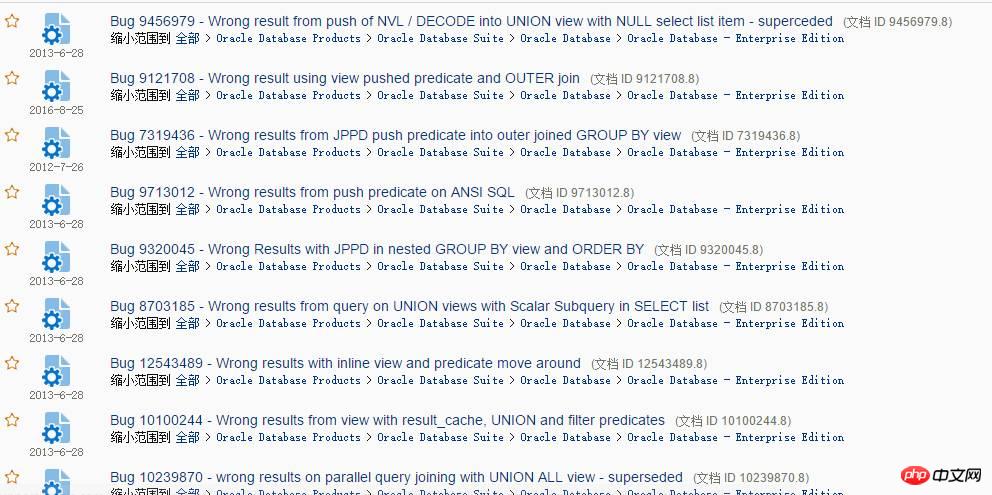
Es stellte sich heraus, dass es sich um ein falsches Ergebnis handelte, was kein Leistungsproblem darstellt, sondern ein ernstes Problem mit der Datenkorrektheit Es gibt viele solcher Fehler, aber ich glaube, dass Sie in tatsächlichen Anwendungen auf weniger stoßen. Wenn Sie eines Tages feststellen, dass das Ergebnis einer SQL-Abfrage falsch sein könnte, müssen Sie es mutig in Frage stellen. Im Allgemeinen ist das Hinterfragen eine sehr korrekte Denkweise. Diese Art von Problem mit falschen Ergebnissen kann während des Datenbank-Hauptversions-Upgrades auftreten. Es gibt zwei Haupttypen von Problemen:
-
Das ursprüngliche Ergebnis war korrekt, aber jetzt ist das Ergebnis falsch. --Auf einen neuen Versionsfehler gestoßen
Jetzt ist das Ergebnis korrekt, aber das ursprüngliche Ergebnis war falsch. --Die neue Version behebt den Fehler der alten Version
Die erste Situation ist normal, die zweite Situation kann auch vorkommen. Ich habe einen Kunden gesehen, der fragte, ob das Ergebnis nach dem Upgrade falsch sei. , und nach der Überprüfung stellte sich heraus, dass der Ausführungsplan der alten Version falsch war und der Ausführungsplan der neuen Version korrekt war, das heißt, er war viele Jahre lang falsch gewesen, ohne entdeckt zu werden Es stellte sich heraus, dass es richtig war, aber sie hielten es für falsch.
Wenn Sie auf falsche Ergebnisse stoßen, kann es sein, dass sie viele Jahre lang tief vergraben bleiben, wenn es sich nicht um eine nicht zum Kerngeschäft gehörende Funktion handelt.
Schätzer(Schätzer):
Natürlich verwendet der Schätzer statistische Informationen (Tabelle, Index, Spalte, Partition usw.), um die entsprechende Ausführungsplanoperation abzuschätzen Selektivität, wodurch die Kardinalität der entsprechenden Operation berechnet, die KOSTEN der entsprechenden Operation generiert und schließlich die KOSTEN des gesamten Plans berechnet werden. Für einen Schätzer ist die Genauigkeit seines Schätzmodells und die Genauigkeit der Speicherung statistischer Informationen sehr wichtig. Je wissenschaftlicher das geschätzte Modell ist, desto mehr statistische Informationen können die tatsächliche Datenverteilung widerspiegeln und mehr abdecken Wenn Sie spezielle Daten eingeben, sind die generierten KOSTEN genauer.
Dies ist jedoch unmöglich. Es gibt viele Probleme im Schätzermodell und in den statistischen Informationen. Wenn beispielsweise die Selektivität fürZeichenfolge berechnet wird, konvertiert ORACLE die Zeichenfolge intern. , nachdem Sie den RAW-Typ in eine Zahl umgewandelt und dann 15 Ziffern von links gerundet haben, können die Zeichenfolgen sehr unterschiedlich sein. Da die Zahl nach der Konvertierung 15 Ziffern überschreitet, können die Ergebnisse nach der internen Konvertierung ähnlich sein. Dies führt letztendlich zu einer ungenau berechneten Selektivität. Plan Generator (
Plan Generator):Plan Generator analysiert verschiedene Zugriffspfade, JOIN-Methoden und JOIN-Sequenzen, um verschiedene Ausführungspläne zu erstellen. Wenn also ein Problem mit diesem Teil vorliegt, weist der entsprechende Teil möglicherweise unzureichende Algorithmen oder Einschränkungen auf. Wenn es beispielsweise viele JOIN-Tabellen gibt, dann nimmt die Auswahl an verschiedenen Zugriffssequenzen in einem geometrischen Verlauf zu. Innerhalb von ORACLE gibt es Grenzen, was bedeutet, dass es unmöglich ist, sie alle zu berechnen.
Zum Beispiel ist der HASH JOIN-Algorithmus im Allgemeinen der bevorzugte Algorithmus für die Verarbeitung großer Datenmengen. Allerdings weist HASH JOIN von Natur aus eine Einschränkung auf: Sobald eine HASH-Kollision auftritt, wird die Effizienz zwangsläufig stark reduziert.
Der CBO-Optimierer hat viele Einschränkungen. Weitere Informationen finden Sie unter MOS: Einschränkungen des Oracle Cost Based Optimizer (Dokument-ID 212809.1).
2. Lösungen für die Fallstricke des CBO-Optimierers
In diesem Abschnitt werden hauptsächlich Fälle häufiger Probleme mit dem CBO-Optimierer behandelt, da der Optimierer derzeit weit verbreitet ist , beinhaltet immer das CBO-Problem.
1 FILTER-Leistungskillerproblem
Der FILTER-Vorgang ist ein häufiger Vorgang im Ausführungsplan. Es gibt zwei Situationen für diesen Vorgang:
- Nur eine Untergeordneter Knoten, dann handelt es sich um einen einfachen Filtervorgang.
- Wenn mehrere untergeordnete Knoten vorhanden sind, handelt es sich um eine ähnliche Operation wie bei NESTED LOOPS. Der einzige Unterschied zu NESTED LOOPS besteht darin, dass FILTER intern eine HASH-Tabelle erstellt wird nicht noch einmal ausgeführt
- Schleife
zur Suche, sondern zur Verbesserung der Effizienz vorhandene Ergebnisse verwenden. Sobald es jedoch weniger wiederholte Übereinstimmungen und mehr Schleifen gibt, beeinträchtigt die FILTER-Operation die Leistung erheblich und Ihr SQL kann möglicherweise mehrere Tage lang nicht ausgeführt werden.
Werfen wir einen Blick auf die FILTER-Operation unter verschiedenen Umständen:
Einzelner untergeordneter Knoten:
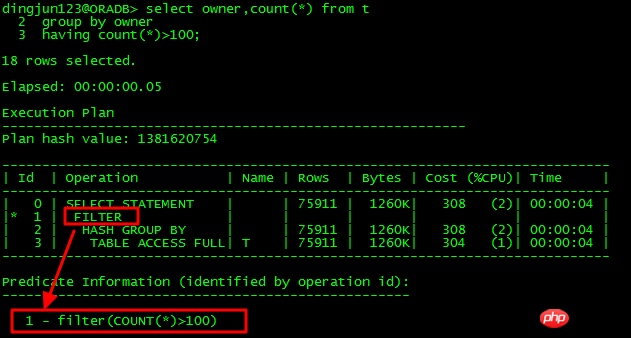 Offensichtlich die ID Die FILTER-Operation von =1 hat nur eine untergeordnete Knoten-ID=2. In diesem Fall ist die FILTER-Operation eine einfache Filteroperation.
Offensichtlich die ID Die FILTER-Operation von =1 hat nur eine untergeordnete Knoten-ID=2. In diesem Fall ist die FILTER-Operation eine einfache Filteroperation.
Mehrere untergeordnete Knoten:
FILTER Mehrere untergeordnete Knoten sind häufig Leistungskiller. Sie treten hauptsächlich auf, wenn Unterabfragen nicht in UNNEST-Abfragen konvertiert werden können , komplexe Unterabfragen usw.
(1) FILTER in NOT IN-Unterabfrage
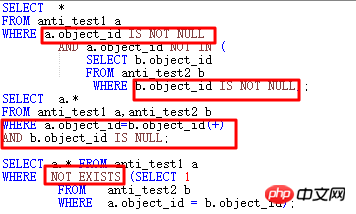
Schauen wir uns zunächst die NOT IN-Situation an:
Wenn die Unterabfrage object_id für die obige NOT IN-Unterabfrage NULL hat, hat die gesamte Abfrage vor 11g keine Ergebnisse, wenn die Haupttabelle und die Untertabelle die object_id haben nicht gleichzeitig NOT NULL-Einschränkungen aufweist oder keine der IS NOT NULL-Einschränkungen hinzugefügt wird, verwendet ORACLE FILTER. 11g verfügt über eine neue ANTI NA (NULL AWARE)-Optimierung, die Unterabfragen aufheben kann, um die Effizienz zu verbessern.
Für die Unterabfrage, die nicht UNNESTed ist, verwenden Sie FILTER und haben mindestens 2 untergeordnete Knoten. Ein weiteres Merkmal des Ausführungsplans ist, dass der Prädikatteil Folgendes enthält: B1, so etwas wie das Binden einer -Variable , die interne Operation ähnelt der NESTED LOOPS-Operation.
11g hat NULL AWARE speziell für NOT IN-Probleme optimiert, wie unten gezeigt:
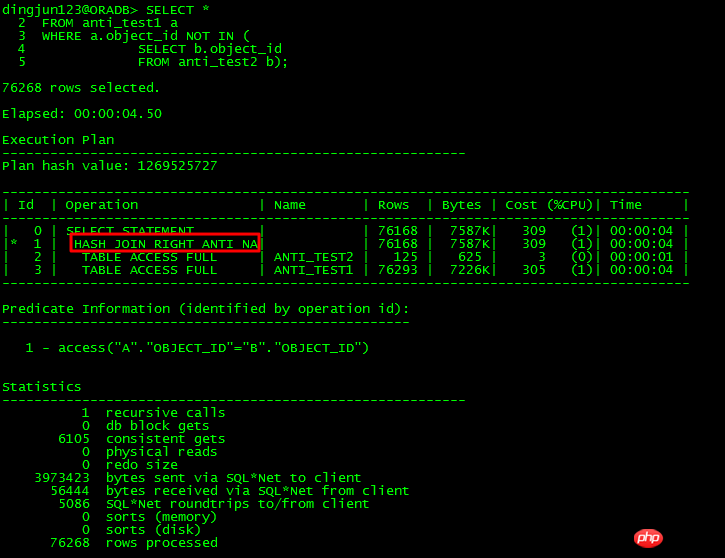
Die NULL AWARE-Operation wird verwendet, um NOT IN-Unterabfragen zu verarbeiten, die nicht UNNESTED sein können Es kann in die JOIN-Form konvertiert werden, wodurch die Effizienz erheblich verbessert wird. Was sollten Sie tun, wenn Sie auf NOT IN stoßen und vor 11g nicht aufheben können?
Legen Sie die Übereinstimmungsbedingung des NOT IN-Teils fest. In diesem Beispiel sind sowohl ANTI_TEST1.object_id als auch ANTI_TEST2.object_id auf NOT NULL-Einschränkungen festgelegt.
Wenn Sie die NOT NULL-Einschränkung nicht ändern, müssen Sie beiden Objekt-IDs IS NOT NULL-Bedingungen hinzufügen.
wird in NOT EXISTS geändert.
wurde in die ANTI JOIN-Form geändert.
Mit den oben genannten vier Methoden kann in den meisten Fällen der Zweck erreicht werden, dass der Optimierer JOIN verwendet.
Die oben genannten Ausführungspläne sind die gleichen, wie unten gezeigt:
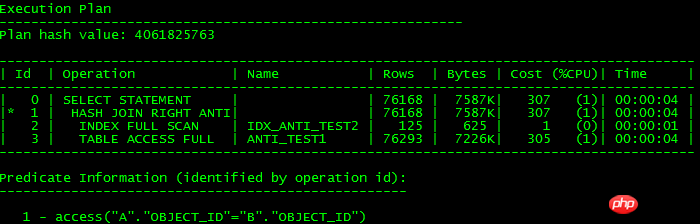
Um es ganz klar auszudrücken: Unnest-Unterabfrage ist Wenn es in die JOIN-Form konvertiert werden kann, können Sie die effiziente JOIN-Funktion verwenden, um die Betriebseffizienz zu verbessern. Wenn die Konvertierung nicht möglich ist, kann dies die Effizienz beeinträchtigen Beachten Sie, dass es immer noch einen kleinen Unterschied gibt. Es gibt keinen INDEX-VOLLSTÄNDIGEN SCAN-Scan, da es für ORACLE keine Bedingung gibt, zu wissen, dass die Objekt-ID möglicherweise NULL ist und daher nicht zum Index gehen kann.
OK, lassen Sie uns nun über einen Fall sprechen, der während des Datenbank-Upgrade-Prozesses aufgetreten ist. Der Hintergrund ist, dass das folgende SQL nach dem Upgrade von 11.2.0.2 auf 11.2.0.4 Leistungsprobleme aufweist:
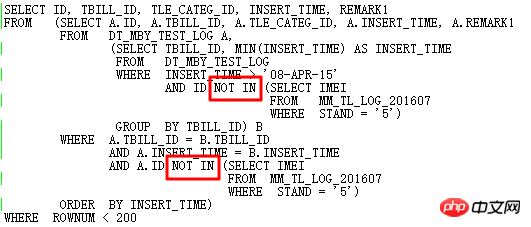
Der Ausführungsplan ist wie folgt:
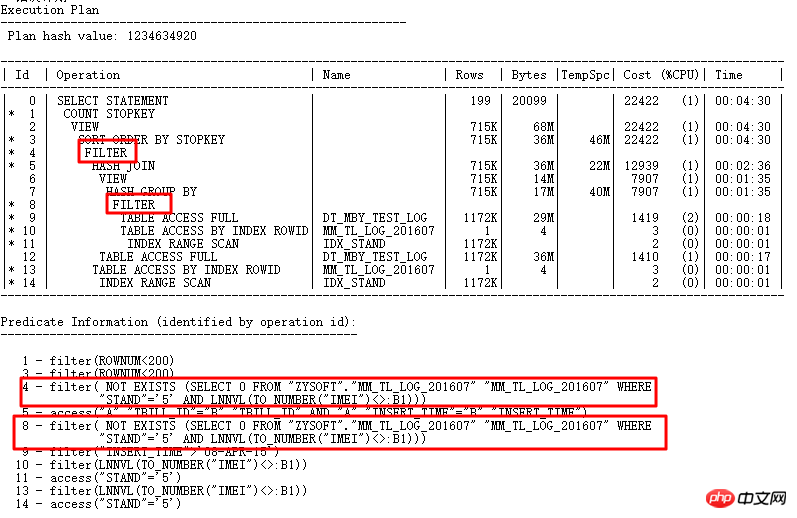
Die beiden FILTER mit ID=4 und ID=8 haben hier offensichtlich beide 2 untergeordnete Knoten NOT IN-Unterabfrage kann nicht UNNEST werden. Wie oben erwähnt, kann NOT IN in 11g ORACLE CBO in NULL AWARE ANTI JOIN konvertiert werden, und zwar unter 11.2.0.2, jedoch nicht unter 11.2.0.4. Wie schädlich sind die beiden FILTER-Operationen? Sie können es sehen, indem Sie den tatsächlichen Ausführungsplan abfragen:
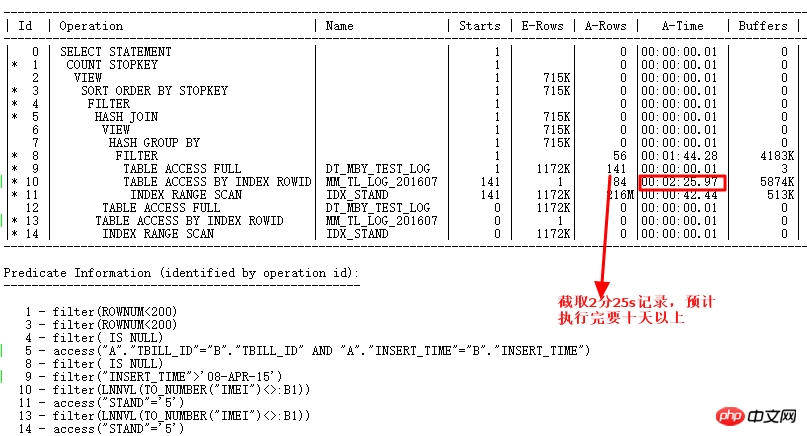
Verwenden Sie ALTER SESSION SET STATISTICS_LEVEL=ALL; Sekunden zum Anzeigen In der tatsächlichen Situation dauert die Zeile CARD=141 mit der ID=9 2 Minuten und 25 Sekunden. Die tatsächlichen Schritte sind: 27w Zeilen
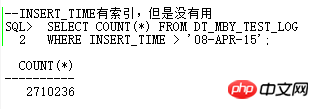
, was dieses SQL bedeutet Muss länger als 10 Tage laufen. Ja, es ist einfach zu gruselig.
Die Analyse dieses Problems lautet wie folgt:
Fragen Sie ab, ob die impliziten Parameter im Zusammenhang mit NULL AWARE ANTI JOIN gültig sind
Sind die gesammelten statistischen Informationen gültig?
Ob es sich um einen neuen Versionsfehler oder eine Parameteränderung während des Upgrades handelt? erste Situation:
 Für die zweite Situation:
Für die zweite Situation:
Das Sammeln statistischer Informationen wird als ungültig befunden.
Zum jetzigen Zeitpunkt können wir unsere Hoffnung nur auf die dritte Situation setzen: Möglicherweise handelt es sich um einen FEHLER oder andere während des Upgrade-Prozesses geänderte Parameter, die sich auf die Unfähigkeit auswirken, NULL AWARE ANTI JOIN zu verwenden. Es gibt so viele ORACLE-FEHLER und -Parameter. Wie können wir also schnell herausfinden, welcher FEHLER oder Parameter die Ursache des Problems ist? Hier möchte ich Ihnen ein Artefakt namens SQLT vorstellen, dessen vollständiger Name (SQLTXPLAIN) ist. Es handelt sich um ein von der internen Leistungsabteilung von ORACLE entwickeltes Tool, das auf MOS heruntergeladen werden kann und über sehr leistungsstarke Funktionen verfügt.
Zurück zum Thema, jetzt müssen wir herausfinden, ob das Problem durch einen BUG der neuen Version oder einen geänderten Parameter verursacht wird. Dann müssen wir die erweiterte Methode von SQLT verwenden: XPLORE. XPLORE öffnet und schließt kontinuierlich verschiedene Parameter in ORACLE, um den Ausführungsplan auszugeben. Schließlich können wir über den generierten Bericht den passenden Ausführungsplan finden, um festzustellen, ob es sich um ein BUG-Problem oder ein Parametereinstellungsproblem handelt.

Es ist sehr einfach, eine separate Datei für das zu testende SQL zu bearbeiten. Im Allgemeinen verwenden wir zum Testen die XPLAIN-Methode und rufen Sie zum Testen EXPLAIN PLAN FOR auf, um die Testeffizienz sicherzustellen.
SQLT Finden Sie die Grundursache des Problems heraus:

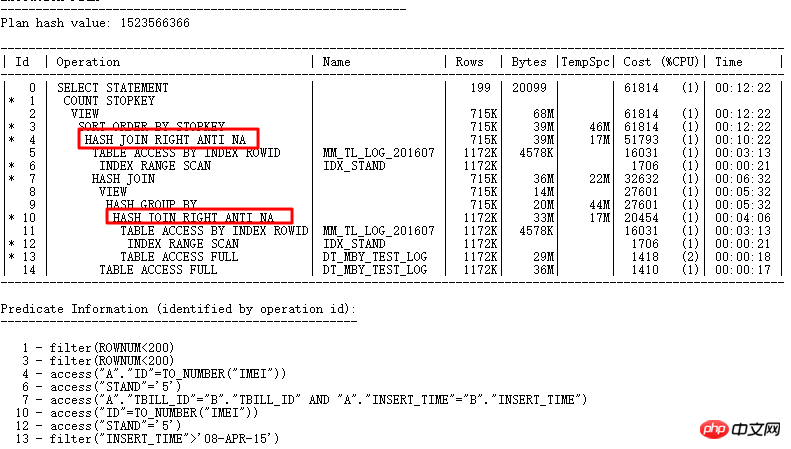
Finden Sie endlich heraus Grundursache des Problems durch SQLT XPLORE. Die neue Version deaktiviert den Parameter _optimier_squ_bottomup (in Bezug auf Unterabfragen). An diesem Punkt ist auch ersichtlich, dass viele Abfragekonvertierungen erfolgreich sein können und nicht nur ein Parameter funktioniert, sondern möglicherweise mehrere Parameter zusammenarbeiten. Deaktivieren Sie daher die Standardparameter und ändern Sie ihre Standardwerte nicht ohne weiteres, es sei denn, es gibt einen triftigen Grund. Zu diesem Zeitpunkt wurde dieses Problem mithilfe von SQLT schnell gelöst. Wenn SQLT nicht verwendet würde, wäre der Prozess zur Lösung des Problems offensichtlich umständlicher. Unter normalen Umständen sollten Entwickler zunächst SQL ändern.
Denken Sie darüber nach: Kann das ursprüngliche SQL besser optimiert werden?
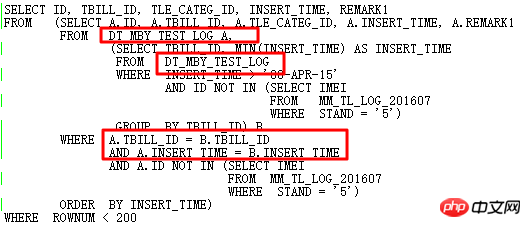
Wenn Sie die SQL weiter optimieren möchten, müssen Sie durch Beobachtung Ähnlichkeiten aufweisen: die Nachschlagetabelle DT_MBY_TEST_LOG Wenn innerhalb des angegebenen INSERT_TIME-Bereichs die kleinste INSERT_TIME für jede TBILL_ID verwendet wird und die ID nicht in der Unterabfrage enthalten ist, werden die Ergebnisse nach INSERT_TIME sortiert und schließlich TOP 199 verwendet.
Das ursprüngliche SQL verwendet Self-Join und zwei Unterabfragen, was redundant und kompliziert ist. Natürlich denke ich darüber nach, es mit Analysefunktionen umzuschreiben, um Selbstverknüpfungen zu vermeiden und dadurch die Effizienz zu verbessern. Das neu geschriebene SQL lautet wie folgt:
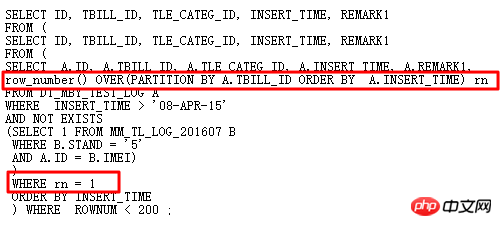
Ausführungsplan:
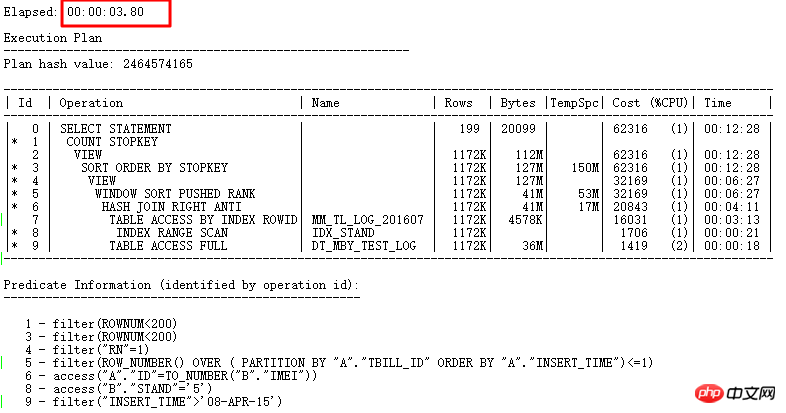
An diesem Punkt erfordert dieses SQL FILTER von Original Es dauerte mehr als 7 Sekunden, um die Grundursache des Problems zu finden und NULL AWARE ANTI JOIN zu verwenden. Schließlich dauerte es 3,8 Sekunden, um es vollständig neu zu schreiben.
(2) FILTER in OR-Unterabfrage
Schauen wir uns die gemeinsame Verwendung von OR und Unterabfrage an. Im eigentlichen Optimierungsprozess ist es im Allgemeinen nicht möglich, OR und Unterabfrage zusammen zu verwenden kann zu schwerwiegenden Leistungsproblemen führen. Es gibt zwei Möglichkeiten für die Verwendung von OR mit Unterabfrage:
Bedingung oder Unterabfrage
innerhalb der Unterabfrage Enthält oder, z in (wählen Sie … aus der Registerkarte „Bedingung 1“ oder „Bedingung 2“)
Lassen Sie mich die Verarbeitungsmethode der OR-Unterabfrageoptimierung anhand eines bestimmten Falls erläutern. In einer bestimmten Bibliothek 11g R2 bin ich auf die folgende SQL gestoßen , das mehrere Stunden lang nicht ausgeführt wurde:

Schauen wir uns zunächst den Ausführungsplan an:
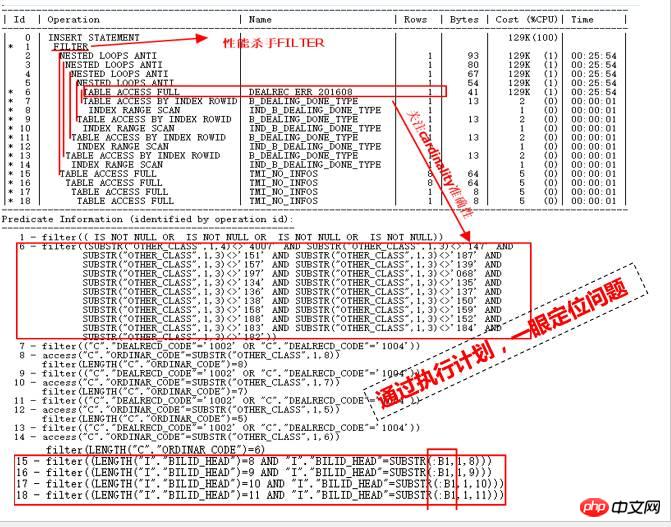
Wie können wir anhand dieses Ausführungsplans auf einen Blick die Ursache für eine langsame Leistung ermitteln? Die Positionierung wird hauptsächlich anhand der folgenden Punkte analysiert:
Zeilen im Ausführungsplan, dh die von jedem Schritt zurückgegebene Kardinalität ist sehr klein, nur wenige Zeilen und die Analysetabelle ist nicht zu groß. Wie konnte es also nicht abgeschlossen werden, selbst nachdem es mehrere Stunden lang gelaufen war? Ein wichtiger Grund kann sein, dass die statistischen Informationen ungenau sind, was dazu führt, dass der CBO-Optimierer Fehler einschätzt. Dies ist der erste Punkt.
Sehen Sie sich die ID=15- bis 18-Teile an. Sie sind die zweiten untergeordneten Knoten der ID=1-FILTER-Operation. Der erste untergeordnete Knoten ist offensichtlich der ID=2-Teil ID=2 Wenn der geschätzte Kardinalitätsfehler tatsächlich groß ist, ist die Anzahl der vollständigen Scans für die vier Tabellen mit ID=15 bis 18 enorm, was zu einer Katastrophe führen wird.
Natürlich sind auch viele verschachtelte Schleifen im ID=2-Teil sehr verdächtig. Der Eingang zur ID=2-Operation befindet sich im ID=6-Teil wird nach DEALREC_ERR_201608 gescannt und es wird geschätzt, dass 1 zurückgegeben wird. Offensichtlich ist dies die Hauptursache für den NESTED LOOPS-Vorgang, daher muss die Genauigkeit überprüft werden.
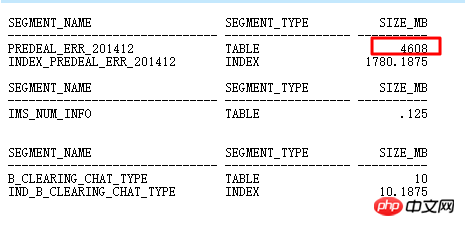
Die Haupttabelle DEALREC_ERR_201608 gibt 20 Millionen Zeilen in der Abfragebedingung ID=6 zurück. Es wird geschätzt, dass der Plan nur eine Zeile enthält. Daher wird die Anzahl der NESTED LOOPS tatsächlich mehrere zehn Millionen Mal ausgeführt Bei geringer Effizienz sollte HASH JOIN verwendet werden.
Darüber hinaus ist ID=1 FILTER und seine untergeordneten Knoten sind ID=2 und ID=15, 16, 17 und 18. Dieselbe ID 15-18 wurde auch zig Millionen Mal gesteuert .
Nachdem Sie die Ursache des Problems herausgefunden haben, lösen Sie es Schritt für Schritt. Zuerst müssen wir die Genauigkeit der Kardinalität ermitteln, die durch die Abfragebedingung substr(other_class, 1, 3) NOT IN ('147', '151', …) für die Tabelle DEALREC_ERR_201608 im Teil ID=6 erhalten wird , um statistische Informationen zu sammeln.
Es wurde jedoch festgestellt, dass die Verwendung von „Size Auto“ und „Size Repeat“ keine Auswirkung auf die Erfassung von Histogrammen für „other_class“ hatte. Die Schätzung der Abfragebedingungsrückgabe für „other_class“ im Ausführungsplan betrug immer noch 1 (tatsächlich 20 Millionen Zeilen).

Der Ausführungsplan nach der Ausführung lautet wiederum wie folgt:
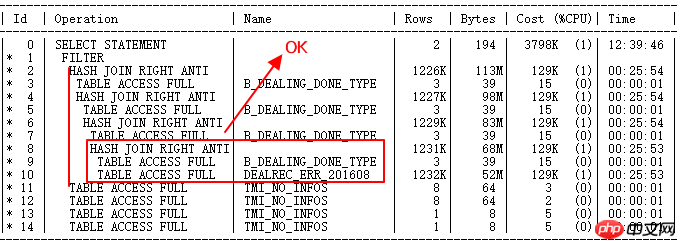
DEALREC_ERR_201608 und B_DEALING_DONE_TYPE ursprünglich ging NL Der HASH JOIN funktioniert jetzt korrekt. Die Build-Tabelle ist eine kleine Ergebnismenge, die Sondentabelle ist eine große Ergebnismenge der ERR-Tabelle, richtig.
Aber ID=2 und ID=11 bis 14, also die OR-Unterabfrage mit TMI_NO_INFOS oder FILTER, steuern zig Millionen untergeordnete Knotenabfragen, was die nächste Optimierung darstellt muss Frage lösen.
Leistung von 12 Stunden bis 2 Stunden.
Was jetzt gelöst werden muss, ist das FILTER-Problem. Es gibt ODER-Bedingungen für Unterabfragen. Wenn einfache Bedingungen abgefragt und konvertiert werden können, werden sie im Allgemeinen in eine Vereinigung umgewandelt nach der All-Ansicht Führen Sie dann Semi-Join und Anti-Join durch (in die Union-All-Ansicht konvertieren, wenn die Prädikattypen unterschiedlich sind, meldet SQL möglicherweise einen Fehler). Bei dieser Komplexität kann der Optimierer die Transformation nicht abfragen, daher ist das Umschreiben die einzig mögliche Methode. Nach der Analyse von SQL stellt sich heraus, dass es sich bei der Abfrage um dieselbe Tabelle handelt und die Bedingungen ähnlich sind, die Länge jedoch unterschiedlich ist, sodass sie einfach zu handhaben ist!

So ändern Sie den Unterabfrage-Ausführungsplan mit ODER von FILTER zu JOIN. Zwei Methoden:
1) Wechsel zu UNION ALL/UNION
2) Semantisches Umschreiben wurde bereits verwendet und intern in UNION-ähnliche Operationen umgewandelt Wenn Sie den Tabellenzugriff reduzieren, können Sie die ODER-Bedingung nur vollständig neu schreiben, um die Konvertierung in eine UNION-Operation zu vermeiden.
Lassen Sie uns die ursprüngliche ODER-Bedingung analysieren:
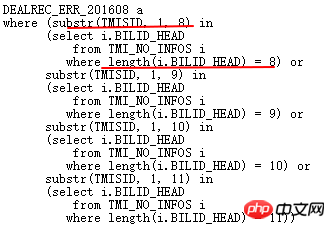
Die obige Bedeutung ist, dass die ersten 8, 9, 10 und 11 Ziffern der TMISID des ERR Tabellenübereinstimmung TMI_NO_INFOS.BILLID_HEAD , die entsprechende übereinstimmende BILLID_HEAD-Länge beträgt genau 8,9,10,11. Offensichtlich kann die Semantik wie folgt umgeschrieben werden:
Die ERR-Tabelle ist mit der TMI_NO_INFOS-Tabelle verknüpft. Die ersten 8 Ziffern von ERR.TMISID stimmen genau mit den ersten 8 Ziffern von ITMI_NO_INFOS.BILLID_HEAD überein, mit einer Länge zwischen 8- 11. Unter dieser Voraussetzung ist TMISID wie „BILLID_HEAD %“.
Beginnen Sie nun mit der vollständigen Änderung mehrerer OR-Unterabfragen, um SQL schlanker und effizienter zu gestalten. Wie folgt umgeschrieben:
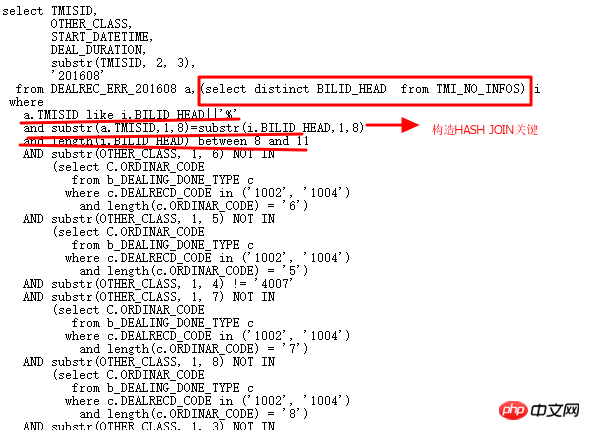
Der Ausführungsplan lautet wie folgt:
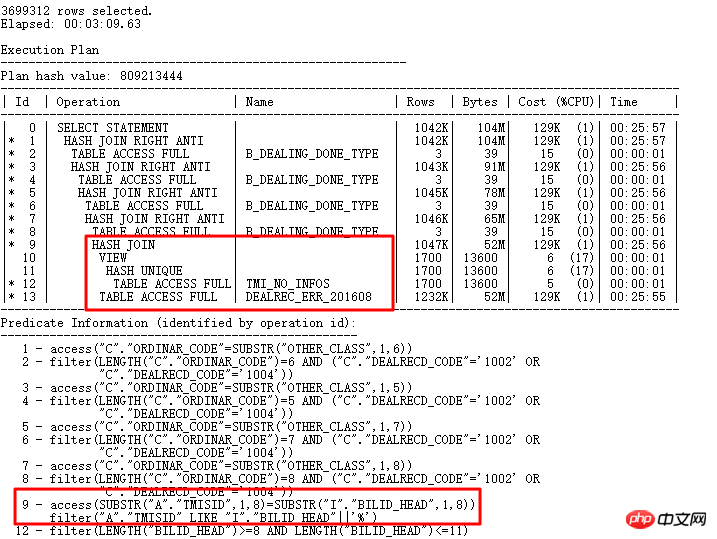
1) Der aktuelle Ausführungsplan ist endlich geworden kürzer und einfacher Nach dem Lesen wurde der HASH JOIN durch Logik neu geschrieben. Die Ausführung des endgültigen SQL, das mehr als 3 Millionen Datenzeilen zurückgab, dauerte ursprünglich 12 Stunden, jetzt wird es jedoch in 3 Minuten ausgeführt.
2) Denken: Das Schreiben von SQL mit guter Struktur und klarer Semantik hilft dem Optimierer, einen vernünftigeren Ausführungsplan auszuwählen. Daher ist das gute Schreiben von SQL auch eine technische Aufgabe.
Ich hoffe, dass Sie durch diesen Fall einige Anregungen erhalten, wie Sie SQL als Abfragekonverter schreiben und den Zugriff auf Tabellen, Indizes, Partitionen usw. reduzieren können Es ist für ORACLE einfacher, einige effiziente Algorithmen zu verwenden, um die Effizienz der SQL-Ausführung zu verbessern.
Tatsächlich bedeutet eine OR-Unterabfrage nicht unbedingt, dass es sich überhaupt nicht um eine Unnest handeln kann. Bitte sehen Sie sich das folgende Beispiel an:
Abfrage, die nicht unnest sein kann be unnest:
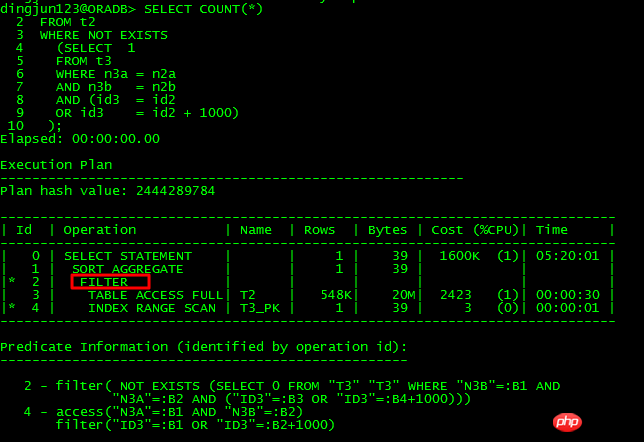
Can unnest query:
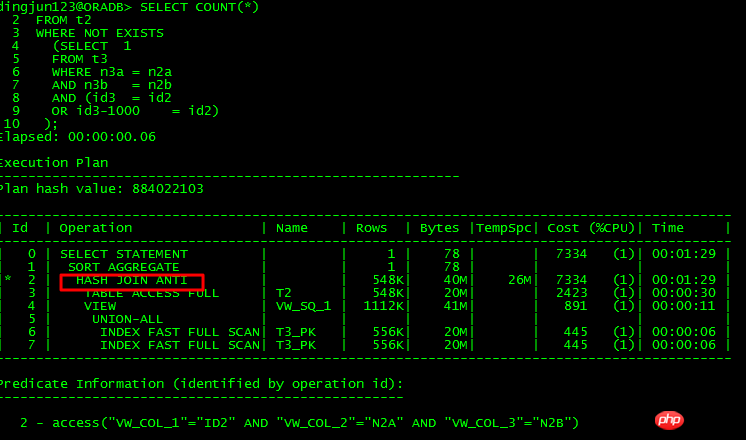
Der Unterschied zwischen diesen beiden SQLs besteht darin, die Bedingung oder id3 zu konvertieren = id2-1000 in oder id3 -1000 = id2, ersteres kann nicht unnest sein, und letzteres kann unnest sein. Durch die Analyse von 10053 können wir wissen:
Das Auftreten von unnest:
SU: Aufheben der Verschachtelung von Abfrageblöcken im Abfrageblock SEL$1 (#1), die zum Aufheben der Verschachtelung gültig sind.
Unterabfrage-Aufheben der Verschachtelung im Abfrageblock SEL$1 (#1)SU: Aufheben der Verschachtelung, für das keine Kostenberechnung erforderlich ist.
SU: Berücksichtigung der Aufhebung der Verschachtelung der Unterabfrage im Abfrageblock SEL$1 (#1).
SU: Prüfung der Gültigkeit der Aufhebung der Verschachtelung der Unterabfrage SEL$2 (#2)
SU: SU umgangen: Ungültige korrelierte Prädikate.
SU: Gültigkeitsprüfungen fehlgeschlagen.
Kann nicht verschachtelt erscheinen:

Und Schreiben Sie die SQL wie folgt um:

Schließlich fragt CBO zunächst die T3-Bedingungen ab, erstellt eine UNION ALL-Ansicht und ordnet sie dann T2 zu. Unter diesem Gesichtspunkt sind die Unschachtelungsanforderungen für OR-Unterabfragen relativ streng. Aus der Analyse dieser Anweisung geht hervor, dass ORACLE Unschachtelungsoperationen durchführen kann, ohne dass Operationen an den Haupttabellenspalten erforderlich sind. Der Optimierer selbst verschiebt die +1000-Bedingung nicht nach links Da es streng ist, kann die OR-Unterabfrage in den meisten Fällen nicht verschachtelt werden, was zu verschiedenen Leistungsproblemen führt.
(3) FILTER-ähnliche Probleme
FILTER-ähnliche Probleme spiegeln sich hauptsächlich in UPDATE-bezogenen Aktualisierungen und skalaren Unterabfragen wider. Obwohl das Schlüsselwort FILTER in solchen SQL-Anweisungen nicht explizit vorkommt, ist das interne Die Operation ist genau die gleiche wie die FILTER-Operation.
Erster Blick auf das UPDATE-bezogene Update:

14999 Zeilen müssen hier aktualisiert werden:
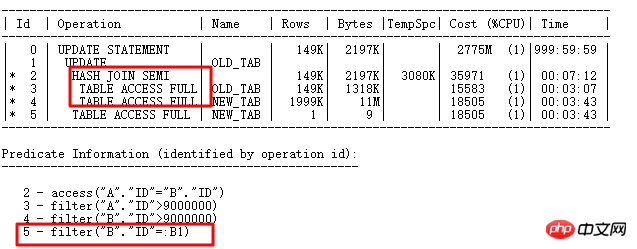
Der Teil „ID=2“ ist der Auswahlteil „wo vorhanden“. Fragen Sie zuerst die Bedingungen ab, die aktualisiert werden müssen, und führen Sie dann die zugehörige Unterabfrageaktualisierung aus. Sie können sehen, dass die Bindungsvariable in angezeigt wird ID=5 Teil: B1. Offensichtlich ist die UPDATE-Operation ähnlich wie im ursprünglichen FILTER. Wenn die ID-Spalte weniger wiederholte Werte aufweist, wird die Unterabfrage für jede ausgewählte Zeile und die mit der Unterabfragetabelle NEW_TAB verknüpfte Abfrage häufig ausgeführt. Dies wirkt sich auf die Effizienz aus. Das heißt, der Vorgang mit der ID=5 muss häufig zweitklassig ausgeführt werden.
Natürlich ist die Feld-ID hier sehr eindeutig. Sie können einen UNIQUE INDEX oder einen normalen INDEX light erstellen, damit der Index in Schritt 5 verwendet werden kann. Hier ist ein Beispiel für diese UPDATE-Optimierungsmethode. Ohne einen Index zu erstellen, können Sie auch solche UPDATE: MERGR- und UPDATE INLINE VIEW-Methoden verarbeiten.
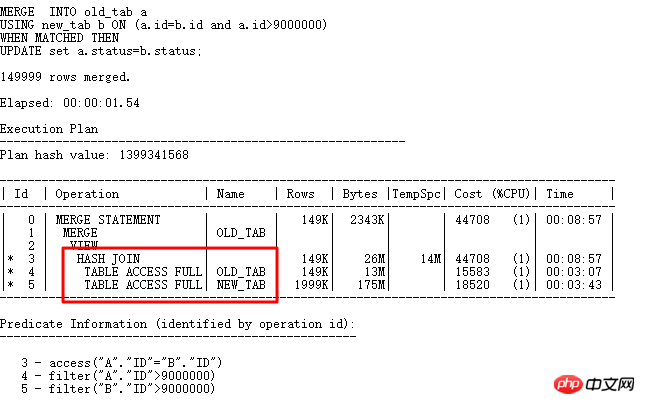
Verwenden Sie HASH JOIN direkt in MERGE, um mehrere Zugriffsvorgänge zu vermeiden und dadurch die Effizienz erheblich zu steigern. Schauen wir uns an, wie man UPDATE LINE VIEW schreibt:
UPDATE
(SELECT a.status astatus,
b.status bstatus
FROM old_tab a,
new_tab b
WHERE a .id= b.id
AND a.id >9000000
)
SET astatus=bstatus;
erfordert, dass b.id a ist Bei beibehaltenem Schlüssel (eindeutiger Index, eindeutige Einschränkung, Primärschlüssel) meldet 11g bypass_ujvc einen Fehler, ähnlich wie bei der MERGE-Operation.
Werfen wir einen Blick auf skalare Unterabfragen, die häufig zu schwerwiegenden Leistungsproblemen führen:
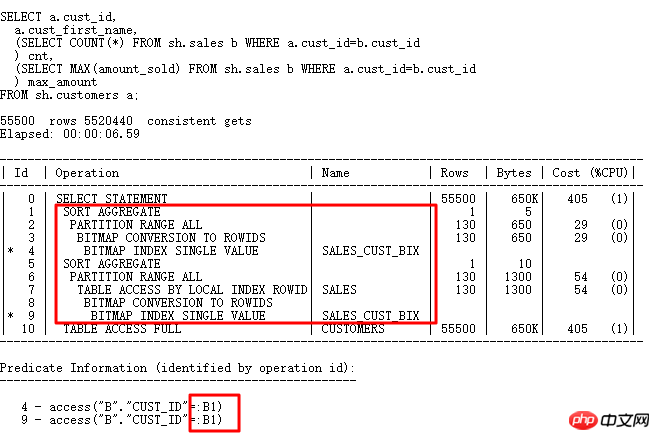
Der Plan skalarer Unterabfragen und die Ausführung gewöhnlicher Pläne Die Reihenfolge ist unterschiedlich. Obwohl die skalare Unterabfrage oben steht, wird sie von den Ergebnissen der Tabelle CUSTOMERS unten gesteuert. Jede Zeile steuert eine skalare Unterabfrageabfrage (mit Ausnahme von CACHE), die auch der FILTER-Operation ähnelt.
Wenn Sie die Skalar-Unterabfrage optimieren möchten, müssen Sie normalerweise die SQL neu schreiben und die Skalar-Unterabfrage in eine äußere Join-Form ändern (sie kann auch in eine normale JOIN-Form umgeschrieben werden, wenn die Einschränkungen und das Geschäft erfüllt sind). :

Nach dem Umschreiben wird die Effizienz erheblich verbessert und der HASH JOIN-Algorithmus verwendet. Werfen wir einen Blick auf CACHE in der skalaren Unterabfrage (FILTER- und UPDATE-bezogene Aktualisierungen sind ähnlich). Wenn die zugehörige Spalte viele wiederholte Werte enthält, wird die Unterabfrage zu diesem Zeitpunkt seltener ausgeführt und die Effizienz ist besser:
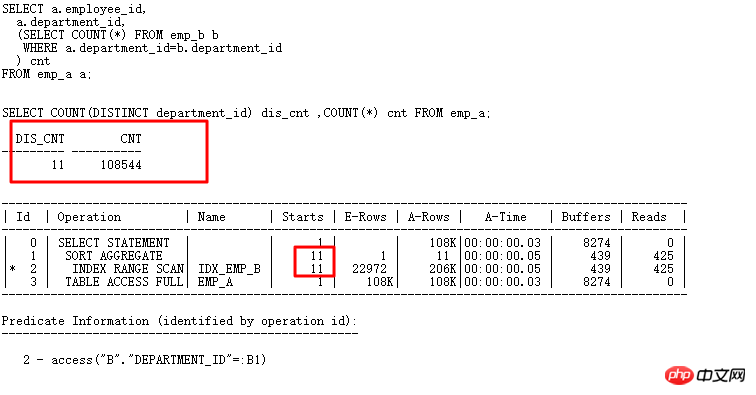
Die skalare Unterabfrage ist die gleiche wie FILTER und verfügt über CACHE. Beispielsweise hat emp_a oben 108.000 Zeilen, aber die wiederholte Abteilungs-ID ist nur 11. Auf diese Weise ist die Abfrage Scannt nur 11 Mal und die Anzahl der Scans der Unterabfragetabelle ist gering. Die Effizienz wird verbessert.
In Bezug auf das FILTER-Performance-Killer-Problem werde ich hauptsächlich diese drei Punkte teilen. Natürlich gibt es viele andere erwähnenswerte Punkte, die von uns täglich mehr Aufmerksamkeit und Ansammlung erfordern, um zu werden vertraut mit dem Umgang mit einigen Problemen des Optimierers.
2 TABLE-Funktion 8168 Kardinalitätsproblem
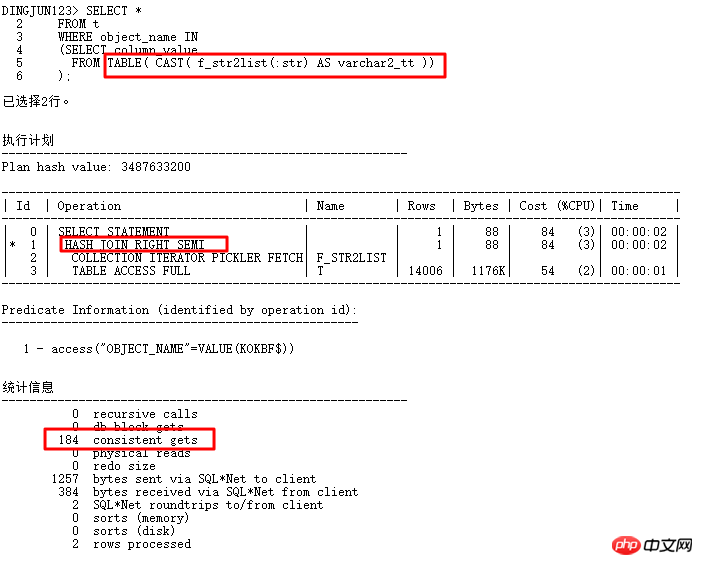
Dieses Problem ergibt sich aus dem Bindungs-in-Listen-Problem, bei dem die TABLE-Funktion zum Erstellen der eingehenden durch Kommas getrennten Werte verwendet wird Als Unterabfragebedingungen übergibt das Front-End im Allgemeinen weniger Werte, aber tatsächlich wird die HASH JOIN-Operation ausgeführt und der T-Tabellenindex kann nicht verwendet werden. Sobald die Ausführungshäufigkeit hoch ist, hat dies zwangsläufig größere Auswirkungen auf dem System. Warum weiß ORACLE nicht, dass die TABLE-Funktion nur sehr wenige Werte übergibt?
Weitere Analyse:
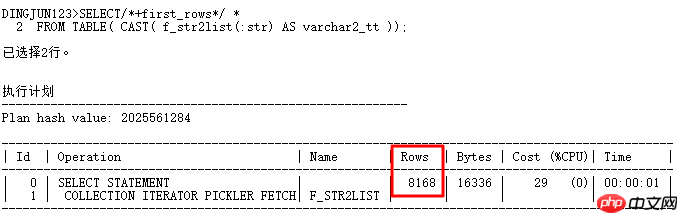
Aus den obigen Ergebnissen können wir ersehen, dass die Standardanzahl der Zeilen der TABLE-Funktion 8168 Zeilen beträgt (die von der TABLE-Funktion erstellte Pseudotabelle enthält keine statistischen Informationen, dieser Wert ist im Allgemeinen viel höher). als die Anzahl der Zeilen in tatsächlichen Anwendungen, was häufig dazu führt, dass der Ausführungsplan einen Hash-Join anstelle einer verschachtelten Schleife durchläuft. Wie kann man diese Situation ändern? Natürlich können Sie den Ausführungsplan über Hinweis-Eingabeaufforderungen ändern. Häufig verwendete Hinweise sind:
erste_Zeilen, Index, Kardinalität, Verwendung_nl usw.
Hier ist eine spezielle Einführung in die Kardinalität (Tabelle | Alias, n). Dieser Hinweis kann den CBO-Optimierer denken lassen, dass die Anzahl der Zeilen in der Tabelle n ist, sodass der Ausführungsplan vorliegt kann geändert werden. Schreiben Sie nun die obige Abfrage neu:
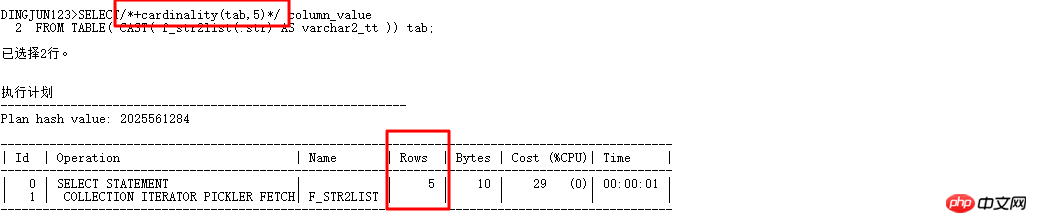
Kardinalität hinzufügen (Tab, 5), um den CBO-Optimierer automatisch auszuführen. Der Optimierer behandelt die Kardinalität der Tabelle als 5 und die vorherige Wo Als die Basis der Listenabfrage standardmäßig 8168 war, wurde Hash-Join verwendet. Jetzt, da die Kardinalität verfügbar ist, versuchen Sie es schnell:
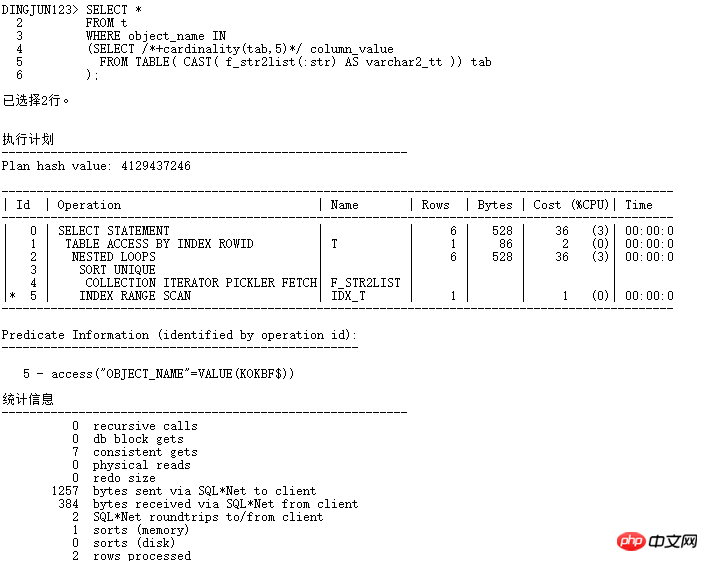
Verwenden Sie jetzt die Operation NESTED LOOPS und untergeordnet Knoten können INDEX RANGE SCAN verwenden, der logische Lesevorgang ändert sich von 184 auf 7 und die Effizienz wird Dutzende Male verbessert. In tatsächlichen Anwendungen ist es natürlich am besten, keine Hinweise hinzuzufügen, und Sie können die SQL PROFILER-Bindung verwenden.
3 Ungenaues Problem bei der Selektivitätsberechnung
Oracles interne Berechnung der Selektivität erfolgt im numerischen Format. Wenn daher ein String-Typ auftritt, wird der String in einen RAW-Typ konvertiert und dann konvertiert Wenn die konvertierte Zahl sehr groß ist, können die intern konvertierten Zahlen relativ ähnlich sein, was zu ungenauen selektiven Berechnungen führen kann. Beispiel:

Der Ausführungsplan lautet wie folgt:
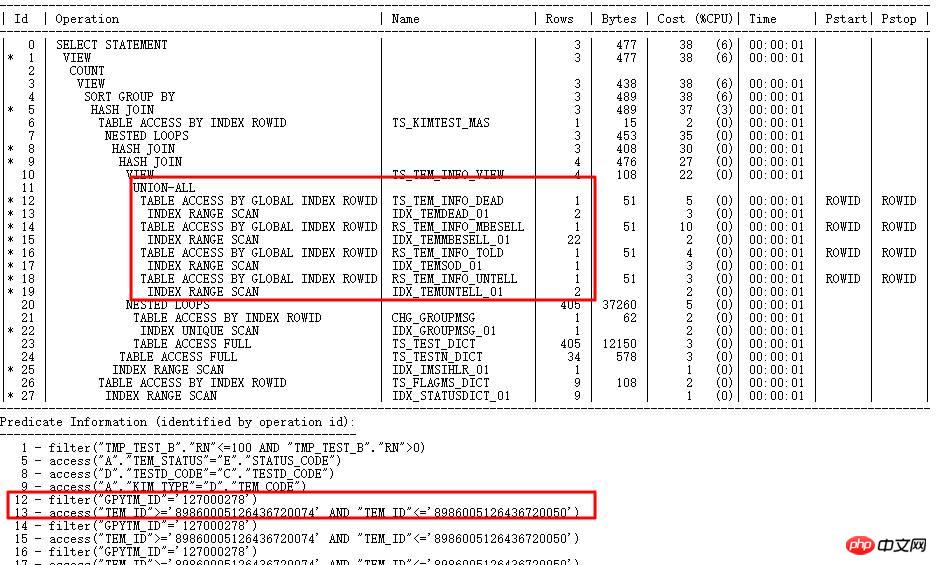
Der SQL-Ausführungsplan verwendet den TEM_ID-Index und benötigt Die Kardinalität der entsprechenden Schritte im Plan ist sehr gering (zig Ebenen), aber die tatsächliche Kardinalität ist sehr groß (Millionen Ebenen) und die statistischen Informationen zur Beurteilung sind falsch.
Warum zum falschen Index gehen?
Da TEM_ID ein CHAR-String-Typ mit einer Länge von 20 ist, wandelt die interne Berechnungsselektivität von CBO die Zeichenfolge zunächst in RAW um und wandelt dann RAW in eine Zahl um, wobei 15 Stellen von links gerundet werden. Daher ist es möglich, dass die Zeichenfolgenwerte sehr unterschiedlich sind und die Werte nach der Konvertierung in Zahlen ähnlich sind (da mehr als 15 Ziffern mit 0 aufgefüllt werden), was zu selektiven Berechnungsfehlern führt. Nehmen Sie als Beispiel die Spalte TEM_ID in TS_TEM_INFO_DEAD:

Die tatsächliche Anzahl der gemäß den Bedingungen abgefragten Zeilen beträgt 29737305. Daher geht der Index schief.
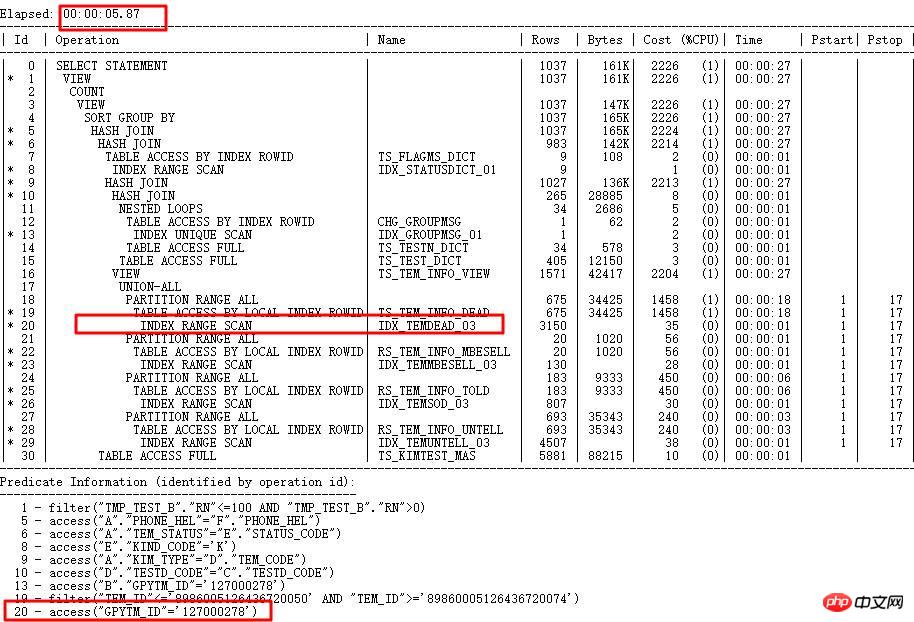
Lösung:
Erfassen Sie das TEM_ID-Spaltenhistogramm. Aufgrund bestimmter Einschränkungen des internen Algorithmus können Zeichenfolgen mit unterschiedlichen Werten denselben internen berechneten Wert haben. Für die Zeichenfolge sind die Werte unterschiedlich, aber nach der Konvertierung in Zahlen sind sie gleich. ORACLE speichert den tatsächlichen Wert zur Überprüfung in ENDPOINT_ACTUAL_VALUE und verbessert die Genauigkeit des Ausführungsplans. Nach korrekter Indizierung von GPYTM_ID liegt die Laufzeit zwischen mehr als 1 Stunde und weniger als 5 Sekunden.
4 Neue Funktionen führen zu Ausführungsfehlern
Die unsachgemäße Verwendung neuer Funktionen kann zu schwerwiegenden Problemen führen, z ACS- und Kardinalitätsrückmeldungen führen zu häufigen Änderungen in den Ausführungsplänen, was sich negativ auf die Effizienz, zu viele Untercursoren usw. auswirkt. Daher müssen neue Funktionen mit Vorsicht verwendet werden, einschließlich der oben erwähnten 11g-Null-Aware-Anti-Join-Funktion, die ebenfalls viele Fehler aufweist.
Der heute zu analysierende Fall ist das SQL, das beim Upgrade der Hauptversion von 10g auf 11g aufgetreten ist. Es lief normal in 10g, wurde jedoch in 11g falsch ausgeführt. Die SQL lautet wie folgt:
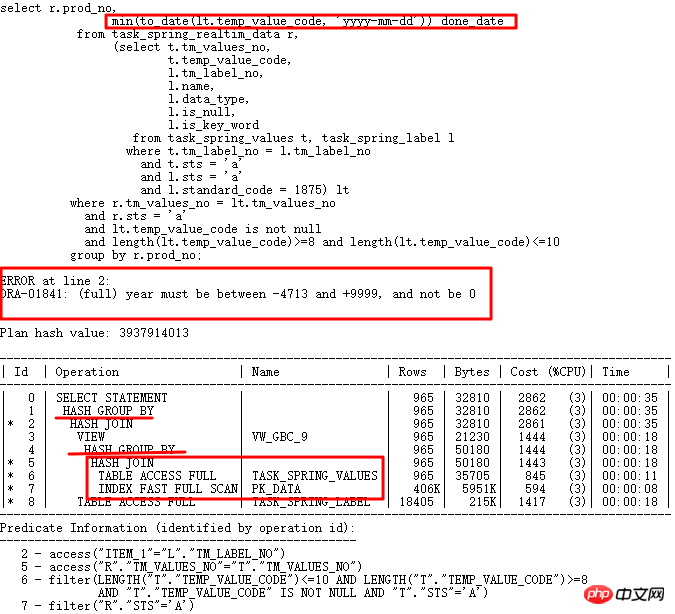
10g ist normal. Nach dem Upgrade auf 11g r2 tritt der Datumskonvertierungsfehler beim Speichern mehrerer Formatzeichenfolgen auf. Korrekter Ausführungsplan: LT-bezogene Abfrage wird zuerst ausgeführt und dann mit der Tabelle verknüpft. Der falsche Ausführungsplan besteht darin, dass TASK_SPRING_VALUES zuerst der Tabelle zugeordnet und dann als VIEW gruppiert und dann mit TASK_SPRING_LABEL verknüpft und dann erneut gruppiert wird. Hier gibt es 2 GROUP BY-Operationen, was sich vom 10g-Ausführungsplan mit nur 1 unterscheidet GROUP BY-Vorgang, der schließlich zu einem Fehler führt.
Natürlich muss untersucht werden, warum 10053 die erste Wahl ist:
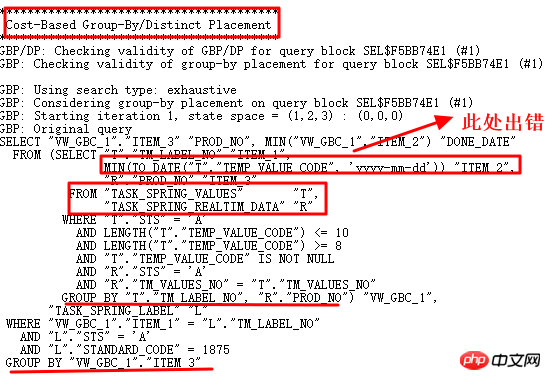
Analysieren Sie anhand der 10053-Operation, ob sie gefunden werden soll das Nicht-Datumsformat Wert:
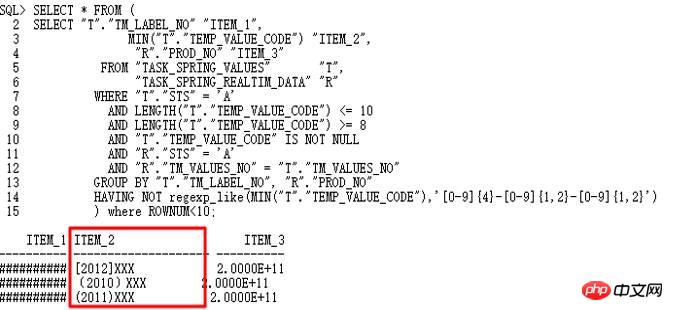
Es wurde tatsächlich eine Zeichenfolge im Format „JJJJ-MM-TT“ gefunden, daher ist der to_date-Vorgang fehlgeschlagen. Wie aus 10053 hervorgeht, wird hier die Operation „Gruppieren nach/Eindeutige Platzierung“ verwendet. Daher ist es notwendig, die entsprechenden Steuerparameter zu finden und diese Abfragekonvertierung zu deaktivieren.
Korrigiert nach Deaktivierung der impliziten GBP-Parameter: _optimizer_group_by_placement. Der richtige Ausführungsplan lautet wie folgt:
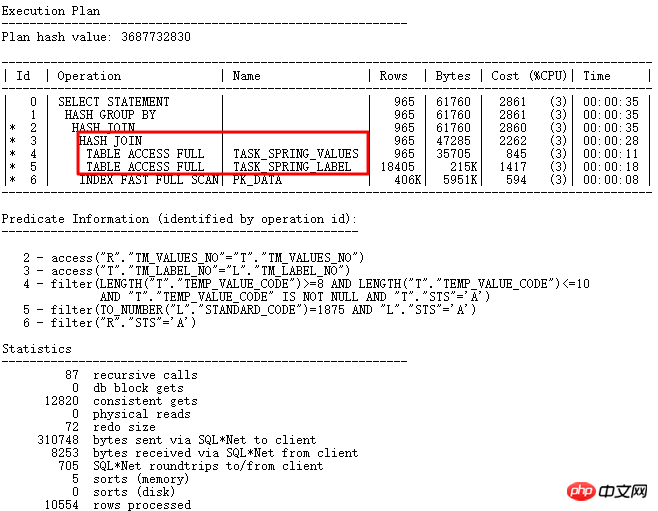
Denken: Der Kern dieses Problems liegt in der unangemessenen Gestaltung der Feldverwendung, bei der temp_value_code als varchar2 zum Speichern gewöhnlicher Zeichen verwendet wird , numerische Zeichen und das Datumsformat JJJJ-MM-TT, es gibt to_number, to_date und andere Konvertierungen im Programm, die stark von der Reihenfolge der Tabellenverbindungen und Bedingungen im Ausführungsplan abhängen. Daher ist ein gutes Design sehr wichtig, insbesondere um die Konsistenz der zugehörigen Feldtypen und die Einzelrolle der Felder sicherzustellen und die Anforderungen des Paradigmas zu erfüllen.
5 CBO kann mit schlechten Schreibmethoden nichts anfangen
Gut strukturiertes SQL kann für CBO leichter verständlich sein, was bessere Abfragekonvertierungsvorgänge ermöglicht und so den Grundstein für die nachfolgende Generierung von legt Der beste Ausführungsplan und dann die praktische Anwendung. Während des Prozesses konnte CBO nichts tun, da es dem SQL-Schreiben keine Beachtung schenkte. Das Folgende ist eine Fallstudie zum Paginierungsschreiben.
Ineffizientes Paging-Schreiben:

Ursprüngliche Schreibmethode Die innerste Ebene wird basierend auf use_date und anderen Bedingungen abgefragt, dann sortiert, Rownum wird abgerufen und mit einem Alias versehen und die äußerste Schicht wird rnlaw verwendet. Was ist das Problem?
Wenn Sie Paging direkt <,<= schreiben, können Sie die Zeilennummer direkt nach der Sortierung erhalten (zwei Ebenen der Verschachtelung). Wenn Sie den Intervallwert erhalten müssen, erhalten Sie >,>= unter die äußerste Ebene (drei Ebenen) verschachtelt).
Diese Anweisung erhält <= und die Verwendung von drei Verschachtelungsebenen macht es unmöglich, den STOPKEY-Algorithmus für Paging-Abfragen zu verwenden, da rownum das Prädikat-Push verhindert, was zu keiner STOPKEY-Operation im Ausführungsplan führt.
<=Paging erfordert nur 2 Verschachtelungsebenen und die Spalte done_date verfügt über einen Index. Gemäß der Bedingung done_date>to_date('20150916','YYYYMMDD') werden nur die ersten 20 Zeilen abgerufen. Der Index- und STOPKEY-Algorithmus kann effizient genutzt werden. Nach Abschluss des Umschreibens wird ein absteigender Index-Scan verwendet, die Ausführungszeit beträgt 1,72 s bis 0,01 s und die logische E/A liegt zwischen 42648 und 59, wie folgt:

Effizientes Paging-Schreiben sollte der Spezifikation entsprechen und Indizes vollständig nutzen, um Sortierungen zu vermeiden.
6 CBO BUG-Problem
CBO BUG erscheint häufiger bei der Abfragekonvertierung. Sobald ein BUG auftritt, kann es schwierig sein, ihn zu diesem Zeitpunkt schnell zu analysieren oder SQLT XPLORE zu verwenden Finden Sie die Ursache des Problems. Zum Beispiel:
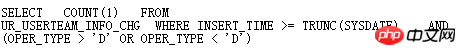
Der oper_type dieser Tabelle hat einen Index, und die Bedingung oper_type>'D' oder oper_type<'D' ist besser, den Index zu verwenden, aber in Tatsache ist, dass Oracle einen vollständigen Tabellenscan und eine schnelle Analyse über SQLT durchgeführt hat >
Offensichtlich ist _fix_control=8275054 sehr verdächtig. Durch die Abfrage von MOS: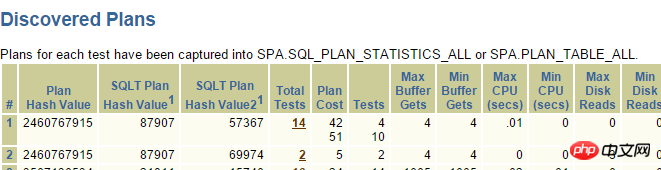
 7 HASH-Kollisionsproblem
7 HASH-Kollisionsproblem
HASHJOIN ist ein effizienter Algorithmus, der speziell für die Big-Data-Verarbeitung verwendet wird und nur für äquivalente Join-Bedingungen, für Tabellenerstellungstabellen (Hash-Tabellen) und Sondentabellenkonstruktionen verwendet werden kann eine HASH-Operation, um die Ergebnismenge zu finden, die die Bedingungen erfüllt.
Das allgemeine Format ist wie folgt: 
Lassen Sie uns ein kleines Beispiel verwenden, um die Hash-Kollision zu analysieren:
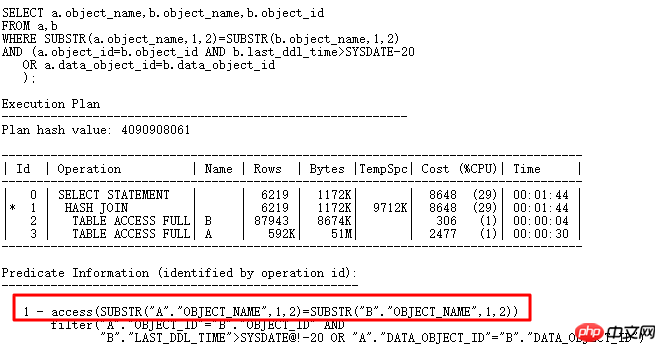
Davon enthält Tabelle a 61w mehrere Datensätze und Tabelle b 7w mehrere Datensätze. Aus dem Ausführungsplan ergibt sich kein Problem bei der Ausführung von HASH Die tatsächliche Ausführung dieses SQL-Vorgangs war jedoch erst nach mehr als 10 Minuten abgeschlossen und die CPU-Auslastung stieg plötzlich an, was viel länger dauerte als der Zugriff auf die beiden Tabellen.
Wenn Sie HASHJOIN kennen, sollten Sie zu diesem Zeitpunkt überlegen, ob eine Hash-Kollision aufgetreten ist. Wenn eine große Datenmenge in vielen Buckets gespeichert ist, ähnelt die Suche nach Daten in solchen Hash-Buckets einer verschachtelten Schleife . , wird die Effizienz zwangsläufig stark reduziert. Die weitere Analyse sieht wie folgt aus:

Suchen Sie nach Werten, die größer als doppelte Daten und größer als 3000 sind. Tatsächlich gibt es viele. Natürlich gibt es auch noch viele größere verbleibende Daten. Sie können EVENT 10104 verwenden:
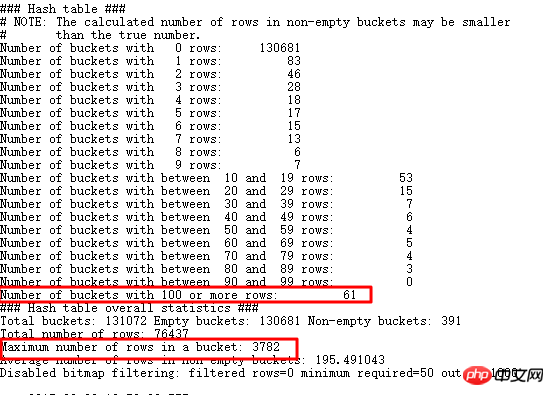
Sie können sehen, dass es 61 Buckets gibt, die mehr als 100 Zeilen speichern Der größte Eimer speichert 3782 Artikel, was und was wir herausgefunden haben, konsistent ist. Kehren wir zum ursprünglichen SQL zurück:
Warum hat Oralce substr(b.object_name,1,2) zum Erstellen der HASH-Tabelle ausgewählt, wenn OR erweitert werden kann und das ursprüngliche SQL in eine UNION ALL-Form geändert wird? , dann die HASH-Tabelle Es kann mit substr(b.object_name,1,2), b.object_id und data_object_id erstellt werden. Dann muss die Eindeutigkeit sehr gut sein, was das Hash-Kollisionsproblem wie folgt lösen sollte:

Die aktuelle SQL-Ausführungszeit ist von ursprünglich 10 Minuten ohne Ergebnisse auf 4 Sekunden nach der Ausführung gestiegen. Schauen wir uns die intern erstellten HASHTABLE-Informationen an:
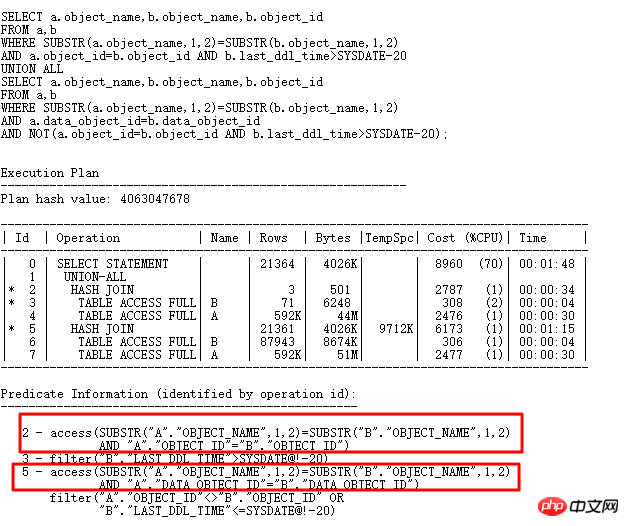
Der mit den meisten Daten werden nur 6 im Bucket gespeichert, daher muss die Leistung viel besser sein als zuvor. In praktischen Anwendungen sind Hash-Kollisionen möglicherweise komplizierter. Wenn Sie auf Hash-Kollisionen stoßen, versuchen Sie, die SQL neu zu schreiben und zu prüfen, ob Sie andere, selektivere Spalten hinzufügen können für JOIN.
Rückblickend weiß ich, dass nach dem Umschreiben in UNION ALL zwei kombinierte Spalten verwendet werden, um eine bessere HASH-Tabelle zu erstellen. Warum macht Oracle das also nicht? Es ist ganz einfach. Ich mache das nur als Beispiel, um das Problem der HASH-Kollision zu veranschaulichen. Wenn Sie mehr selektive Spalten haben und statistische Informationen sammeln, kann Oracle die SQL erweitern.
3. Stärken Sie die SQL-Prüfung und lösen Sie Leistungsprobleme in den Kinderschuhen.
Wenn Sie immer die Rolle eines Feuerwehrmanns spielen, um Online-Probleme zu lösen, wird dies offensichtlich nicht der Fall sein In der Lage, der schnellen Entwicklung heutiger IT-Systeme gerecht zu werden, liegt das Hauptleistungsproblem in SQL-Anweisungen. Wenn die SQL-Anweisungen während der Entwicklungs- und Testphase überprüft werden können, kann dies der Fall sein gefunden werden und intelligente Eingabeaufforderungen zur schnellen Optimierung bereitgestellt werden können, dann zahlreiche Online-Fragen. Darüber hinaus können Online-SQL-Anweisungen kontinuierlich überwacht werden, um Anweisungen mit Leistungsproblemen umgehend zu erkennen und so den Zweck einer vollständigen Lebenszyklusverwaltung von SQL zu erreichen.
Zu diesem Zweck kombinierte das Unternehmen jahrelange Betriebs-, Wartungs- und Optimierungserfahrung, um unabhängig SQL-Audit-Tools zu entwickeln, was die Effizienz der SQL-Audit-Optimierung und Leistungsüberwachungsverarbeitung erheblich verbessert.
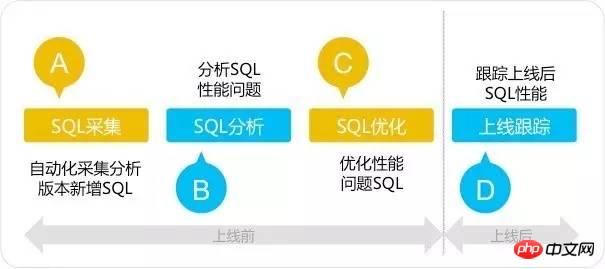
Das SQL-Prüfungstool verwendet eine vierstufige Regel: SQL-Erfassung – SQL-Analyse – SQL-Optimierung – Online-Verfolgung. Die vierstufige SQL-Prüfungsmethode unterscheidet sich von der herkömmlichen SQL-Optimierungsmethode und Optimierung, bevor das System online geht. Konzentrieren Sie sich auf die Lösung von SQL-Problemen, bevor das System online geht, und verhindern Sie, dass Leistungsprobleme in den Kinderschuhen stecken. Wie in der folgenden Abbildung dargestellt:
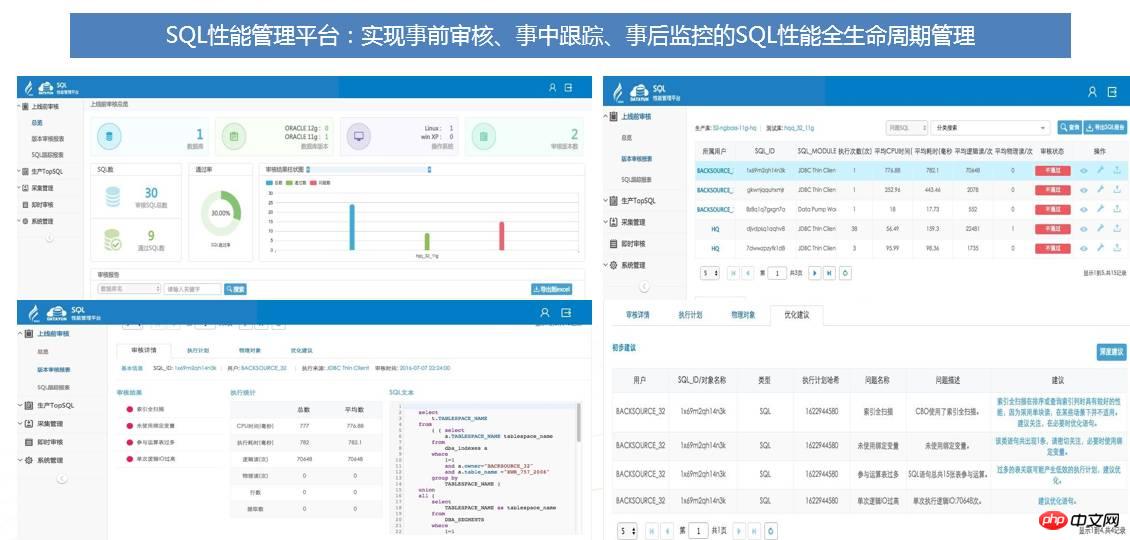
Die folgenden Probleme können durch die SQL-Performance-Management-Plattform gelöst werden:
Vorher: SQL-Leistungsprüfung, bevor Sie online gehen, um Leistungsprobleme in den Kinderschuhen zu eliminieren.
Während: SQL-Leistungsüberwachungsverarbeitung, rechtzeitig Änderungen in der SQL-Leistung erkennen, nachdem Sie online gegangen sind , in der SQL-Leistung Wenn Änderungen auftreten und keine schwerwiegenden Probleme verursachen, beheben Sie diese umgehend.
Anschließend: TOPSQL-Überwachung und rechtzeitige Alarmverarbeitung.
Die SQL-Performance-Management-Plattform ermöglicht eine 360-Grad-Verwaltung und Steuerung der SQL-Leistung über den gesamten Lebenszyklus. Durch verschiedene intelligente Eingabeaufforderungen und Verarbeitung werden die meisten der ursprünglich durch SQL verursachten Leistungsprobleme gelöst . Lösen Sie Probleme, bevor sie auftreten, und verbessern Sie die Systemstabilität.
Das Folgende ist ein typischer Fall einer SQL-Prüfung:
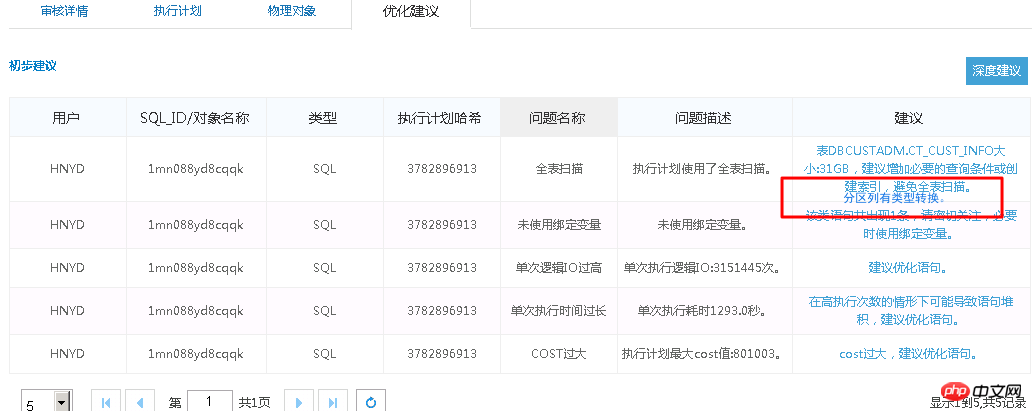
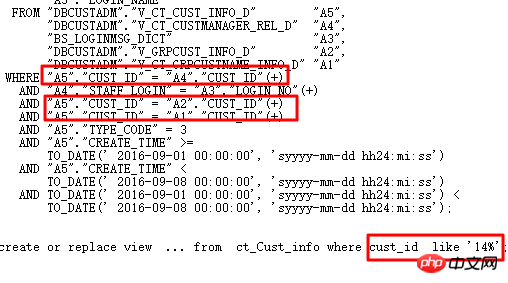
Der Ausführungsplan lautet wie folgt:
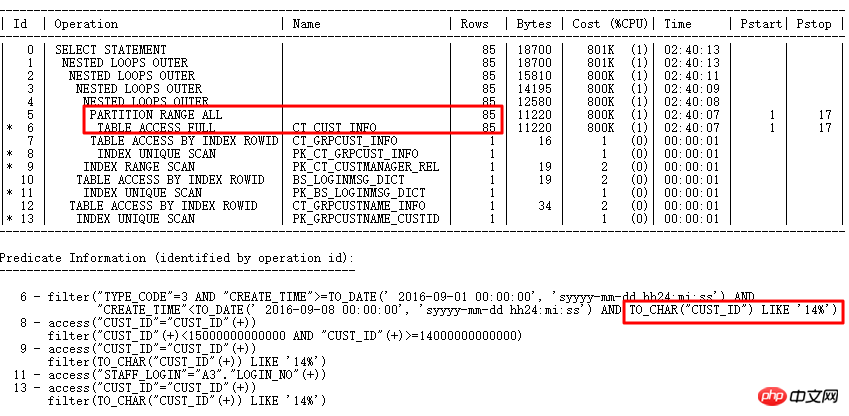
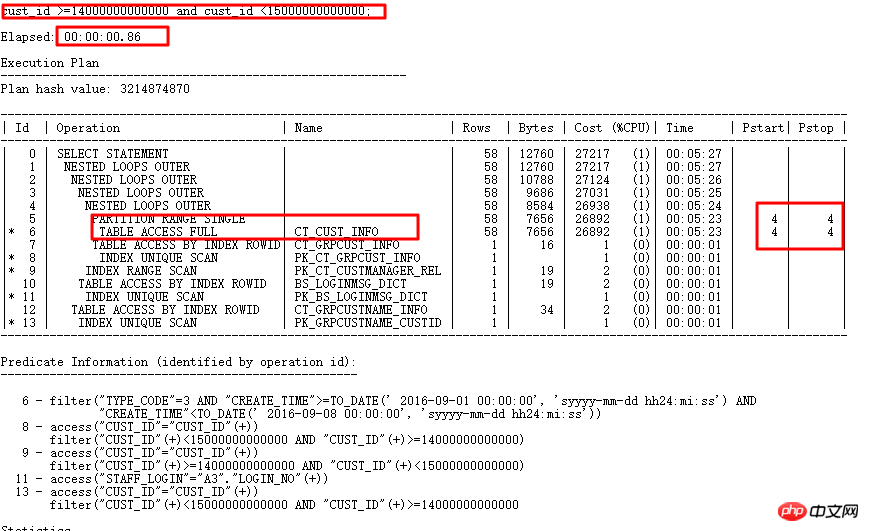
Das ursprüngliche SQL wird 1688 Sekunden lang ausgeführt. Finden Sie Optimierungspunkte genau durch intelligente SQL-Audit-Optimierung – Partitionsspalten verfügen über eine Typkonvertierung. 0,86 s nach der Optimierung.
SQL-Audit ist ein Modul der Xinju Database Performance Management Platform DPM. Wenn Sie mehr über DPM erfahren möchten, können Sie sich zur Kommunikation an Master Zou Deyu (WeChat: carydy) wenden und Diskussion.
Heute zeige ich Ihnen hauptsächlich einige Probleme des Oracle-Optimierers und Lösungen für häufige Probleme. Natürlich sind die Probleme des Optimierers nicht auf die heute geteilten Probleme beschränkt, obwohl CBO sehr leistungsfähig ist und erheblich verbessert wurde 12c, Es gibt jedoch viele Probleme. Nur wenn wir im täglichen Leben mehr ansammeln und beobachten und bestimmte Methoden beherrschen, können wir nach Problemen eine Strategie entwickeln und den Kampf gewinnen.
Fragen und Antworten
F1: Ist der Hash-Join sortiert? Können Sie das Prinzip des Hash-Joins kurz erklären?
A1: ORACLE HASH JOIN selbst muss nicht sortiert werden, was eines der Merkmale ist, die SORT MERGE JOIN auszeichnet. Das Prinzip von ORACLE HASH JOIN ist relativ kompliziert. Sie können sich auf den HASH JOIN-Teil von Jonathan Lewis' Kostenbasierte Oracle-Grundlagen beziehen. Das Wichtigste für HASH JOIN ist beispielsweise, herauszufinden, wann es langsam sein wird , HASH_AREA_SIZE ist zu klein und HASH TABLE kann nicht vollständig im Speicher platziert werden, es kommt zu einem Festplatten-HASH-Vorgang und der oben erwähnten HASH-Kollision.
F2: Wann sollten Sie nicht indexieren?
A2: In vielen Fällen wird die Indizierung nicht verwendet. Der erste Grund ist, dass die Indizierung zu gering ist Ein häufiges Problem besteht auch darin, dass Operationen an Indexspalten ausgeführt werden, was dazu führt, dass keine Indizierung möglich ist. Es gibt viele weitere Gründe, warum der Index nicht verwendet werden kann. Weitere Informationen finden Sie im MOS-Dokument: Diagnosing Why a Query is Not Using an Index (Dokument-ID 67522.1).
Das obige ist der detaillierte Inhalt vonLösen Sie das SQL-Optimierungsproblem von CBO (ausführliche Erklärung mit Bildern und Texten). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!