
Heim >Backend-Entwicklung >Python-Tutorial >Erweiterte Verwendung regulärer Ausdrücke in Python
Erweiterte Verwendung regulärer Ausdrücke in Python
- 巴扎黑Original
- 2017-03-30 14:15:221937Durchsuche
Für Python erfordert das Erlernen der Regelmäßigkeit das Erlernen der Verwendung des Moduls re. In diesem Artikel werden einige fortgeschrittene Techniken vorgestellt, die jeder beherrschen sollte.
Reguläres Ausdrucksobjekt kompilieren
Die re.compile-Funktion generiert ein reguläres Ausdrucksobjekt basierend auf einer Musterzeichenfolge und optionalen Flag-Parametern. Dieses Objekt verfügt über eine Reihe von Methoden zum Abgleichen und Ersetzen regulärer Ausdrücke. Es gibt geringfügige Unterschiede in der Verwendung. Um beispielsweise eine Zeichenfolge abzugleichen, können Sie die folgende Methode verwenden:
Wenn Sie „compilieren“ verwenden, wird daraus:
Warum müssen Sie es verwenden? so was? Tatsächlich werden reguläre Ausdrucksobjekte wiederverwendet, um die Geschwindigkeit des Abgleichs regulärer Ausdrücke zu verbessern. Vergleichen wir die Effizienz der beiden Methoden: 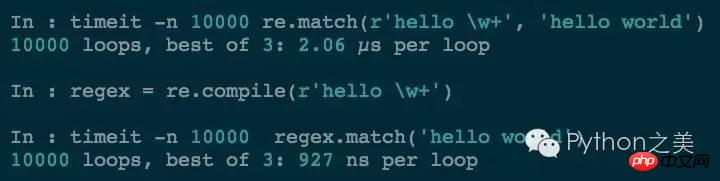
Sie sehen, dass die zweite Methode viel schneller ist. Bei der tatsächlichen Arbeit werden Sie feststellen, dass der Effekt umso besser ist, je mehr Sie kompilierte Objekte mit regulären Ausdrücken verwenden.
Gruppieren
Möglicherweise haben Sie die Verwendung der Gruppierung übereinstimmender Inhalte gesehen: 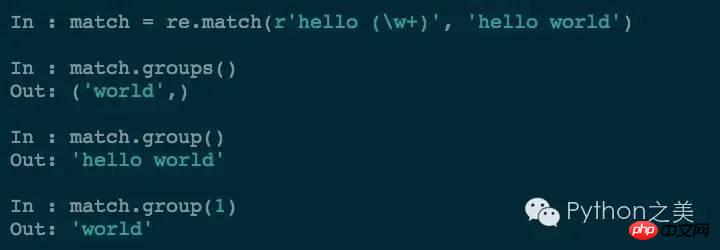
Durch Hinzufügen von Klammern zum Mit den abzugleichenden Objekten können Sie die Übereinstimmungsergebnisse genau abgleichen. Wir können auch eine verschachtelte Gruppierung durchführen: 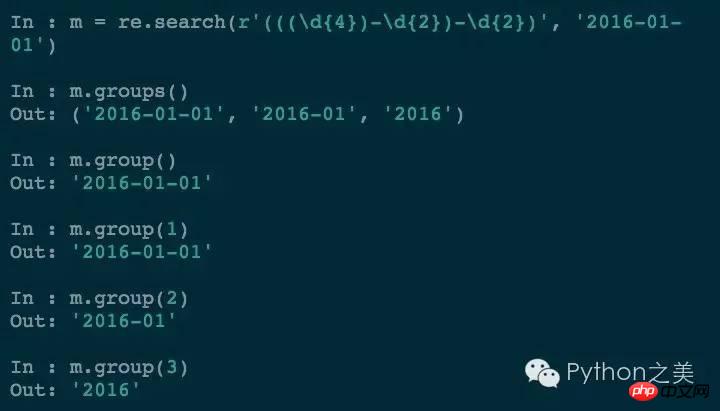
Gruppierung kann die Anforderungen erfüllen, aber manchmal ist die Lesbarkeit schlecht, dann kann die Gruppierung benannt werden: 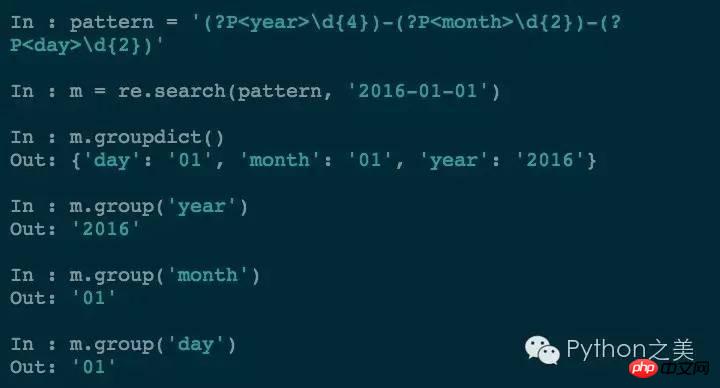
Jetzt ist die Lesbarkeit sehr hoch.
String-Matching
Schüler, die sed gelernt haben, haben möglicherweise die folgende Ersetzungsverwendung gesehen:
Diese 1 stellt das Ergebnis des vorherigen regulären Matchs dar. Der obige Sed dient dazu, den übereinstimmenden Ergebnissen eckige Klammern hinzuzufügen.
hat auch diese Verwendung im re-Modul: 
Es ist auch möglich, benannte Gruppierung zu verwenden: 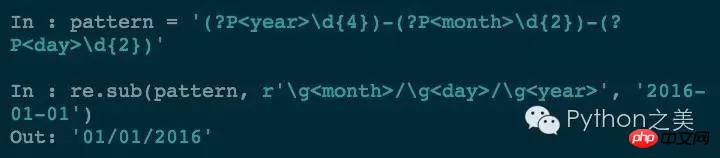
Schauen Sie sich um
Das Modul unterstützt auch Nearest Matching, schauen Sie sich einfach das Beispiel an: 
Verwenden Sie die Funktion
beim regulären Matching Das meiste, was wir zuvor gesehen haben, ist das Matching eines Ausdrucks, aber manchmal sind die Anforderungen viel komplexer, insbesondere beim Ersetzen.
Zum Beispiel können Chat-Datensätze über die Slack-API abgerufen werden, wie zum Beispiel der folgende Satz:
Unter ihnen sind <@U1EAT8MG9> und <@U0K1MF23Z> Bei Slack müssen Sie diese Korrespondenz über andere Schnittstellen abrufen.
Das Ergebnis sieht ähnlich aus:
Nach dem Parsen der Korrespondenz hoffe ich auch, dass die spitzen Klammern entfernt werden nach der Ersetzung steht „@xiaoming, @laolin Ja, das ist tatsächlich so“
Wie kann man das mit regulären Ausdrücken erreichen? 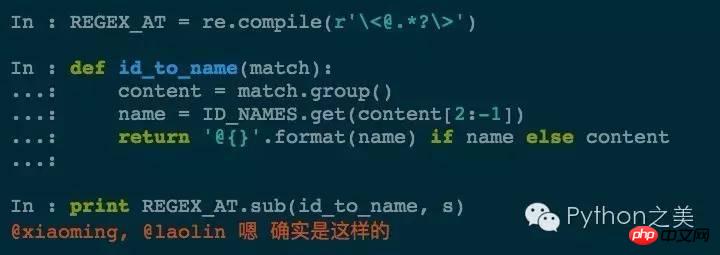
Muster kann also natürlich auch eine Funktion sein
Das obige ist der detaillierte Inhalt vonErweiterte Verwendung regulärer Ausdrücke in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!