
Heim >Backend-Entwicklung >XML/RSS-Tutorial >Detaillierte Einführung in die Verwendung von XML-Denken zum Organisieren von Daten (Bild)
Detaillierte Einführung in die Verwendung von XML-Denken zum Organisieren von Daten (Bild)

- 黄舟Original
- 2017-03-27 17:20:051617Durchsuche
Vorwort
Die Zeiten haben sich geändert.
Früher wurden Daten meist manuell eingegeben und von Terminals mit dedizierten Netzwerkprotokollen in große Eisenkästen in „Glashäusern“ übertragen. Heute sind Informationen allgegenwärtig und präsent, aber nicht unbedingt in Ihrem Unternehmen zusammengefasst. Oft teilen wir Daten in einer „flachen“ Welt, in der es mehr Kanäle für Informationsquellen gibt und sich die Informationen selbst häufiger ändern. Darüber hinaus stellen Sie mit dem Aufkommen einer Reihe von Konzepten wie Web 2.0, Enterprise 2.0 und Internet Service Bus fest, dass es weitaus weniger bequem ist, die vom Lieferanten bereitgestellte Lageradresse in Ihrem eigenen „Glashaus“ zu finden als bei Google Karte.
Es scheint, dass alle Fesseln an Daten in der Vergangenheit nach und nach durch das Internet gebrochen wurden, aber als IT-Praktiker besteht unsere Aufgabe darin, Benutzern die Daten bereitzustellen, die sie benötigen, und die Mittel, die sie erhalten möchten Informationen, also Anwendung Es muss in der Lage sein, verschiedenen Änderungen standzuhalten, einschließlich Änderungen in der Benutzeroberfläche, über die wir uns in der Vergangenheit Sorgen gemacht haben, Änderungen bei Aufrufen zwischen Anwendungen, Änderungen in der internen Logik der Anwendungen und der immer schnelleren Geschwindigkeit, aber die Die grundlegendste Änderung sind Änderungen in den Daten selbst.
BeziehungModell sagt uns, dass wir eine zweidimensionale Tabelle verwenden sollen, um die Informationswelt zu beschreiben, aber das ist zu „un“ natürlich. Schauen Sie sich ein Buch oder es an ist der Heimdekorationsplan und die Aufgabenaufteilung des bald in Angriff genommenen Projekts. Es scheint, dass es nicht angemessen ist, ihn in eine zweidimensionale Tabelle einzutragen, selbst wenn er bis ins letzte Detail reduziert wird „Entitätsbeziehung“ wird in der sich schnell verändernden Umgebung immer notwendig sein. Sie beinhaltet eine Reihe von Änderungen in der „Daten-Anwendung-Front-End-Interaktion“ und betrifft oft den gesamten Körper.
Es scheint, dass viele Anwendungen der neuen Generation eine Lösung gefunden haben, die besser zum neuen Trend passt – XML, indem Anwendungen und Benutzererfahrung auf eine Weise organisiert werden, die näher an unserem eigenen Denken liegt. Kann die relativ grundlegende Arbeit der Datenorganisation für Unternehmen auch mit XML-Denken durchgeführt werden? Es sollte funktionieren.
Umgang mit Änderungen in den Datenentitäten selbst
Datenentitäten wurden immer als der stabilste Teil der Anwendung angesehen, unabhängig davon, ob wir Entwurfsmuster verwenden oder verschiedene Open-Source-Entwicklungsframeworks (einschließlich dieser Frameworks selbst) versuchen alle, sich an die Änderungen in der Anwendung selbst anzupassen. Wie ist die tatsächliche Situation?
l Die Dateneinheiten, die wir austauschen müssen, ändern sich häufig entsprechend den Anforderungen von uns selbst und unseren Partnern
l Die Dateneinheiten, die uns von unseren Partnern bereitgestellt werden, ändern sich häufig; >l Mit der Einführung von SOA- und Enterprise 2.0-Konzepten werden die Datenentitäten selbst aus mehreren Quellen zusammengeführt und auch die Datenentitäten selbst werden immer wieder zusammengestellt und kombiniert. Unsere eigenen Mitarbeiter hoffen immer, immer umfangreichere und detailliertere Informationen zu erhalten.
Daher werden in der Vergangenheit immer mehr Dateneinheiten verwendet, die je nach Bedarf und Design als am frühesten zu beheben galten und agiler im Bereich Technologie und Business Status Quo erfordert ständige Anpassungen. Um uns an diese Anforderung anzupassen, können wir von oben nach unten beginnen und die Flexibilität der Anwendung selbst ständig anpassen. Eine andere Möglichkeit besteht darin, dieses Problem von der „Grundlage“ aus anzugehen und neue Datenmodelle einzuführen, die sich kontinuierlich an diese Änderungen anpassen können , wie zum Beispiel: XML-Datenmodell und XML-bezogene Technologiefamilien.
Beim Definieren einer Benutzerentität reichen beispielsweise zunächst die folgenden Informationen aus, wobei ICustomer die Benutzer-
Schnittstelleist, die die Anwendung verwenden wird, und CUSTOMER die Darstellung im relationalen Datenbankmodus ist. ist XML:
Dann haben wir jedoch festgestellt, dass es bei diesem Entitätsdesign einige Probleme gibt, da wir die Büro- und Privattelefonnummer des Benutzers hinzufügen müssen , und möglicherweise 1, 2 E-Mails, seine MSN- oder Skype-Nummer usw. Unabhängig von anderen Problemen ergibt sich aus der Entwicklung der beiden RDBMS- und XML-Modelle allein auf der Grundlage der Anforderungen der Kategorie 1 des relationalen Modells folgendes Ergebnis: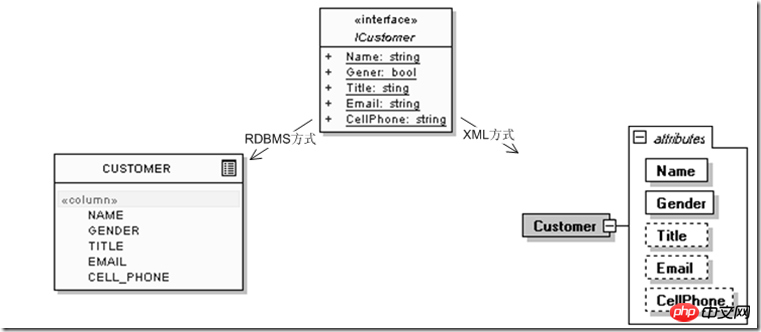
Es ist nicht schwer zu erkennen, dass es zwischen dem relationalen Modell und dem XML-Modell einen sehr großen Unterschied in der Anpassungsfähigkeit gibt, obwohl es sich lediglich um eine Änderung der „Kontaktinformationen“ am Ende der „Kunden“-Datenentität handelt. Das relationale Modell muss kontinuierlich um neue relationale Verwendungsmöglichkeiten erweitert werden, um kontinuierlich verfeinerte Dateneinheiten zu beschreiben. Die hierarchische Natur des XML-Modells selbst kann unter sich ändernden Bedingungen eine eigene kontinuierliche Erweiterung und Erweiterung ermöglichen. In tatsächlichen Projekten bestehen ähnliche Probleme mit Informationen wie „Ausbildungsstatus“ und „Berufserfahrungsstatus“, selbst wenn ein Kunde zu einem bestimmten Zeitpunkt die Methode „Abordnung“ zum Arbeitsstatus hinzufügen möchte Das entsprechende Feld ist reserviert, daher muss ich es als Zeichenfolge in das Feld „Arbeitseinheit“ einfügen, gefolgt von „(Abordnung)“. zum starren Datenmodell selbst, das die Daten auslöscht, und das hierarchische Modell kann es als untergeordneten Knoten oder Attribut beschreiben, sodass nicht nur mehrere Beziehungen (Kunden, Bildungsstatus) möglich sind , Berufserfahrung, Kontaktinformationen) werden in das relationale Modell einbezogen) werden in einer Datenentität konzentriert, und die erweiterten Informationen jeder Entität selbst (z. B. „Arbeitsmodus“: Abordnung, Austausch, kurzfristige Konzentration) usw. können Es kann auch innerhalb der Datenentität beschrieben werden, und gleichzeitig kann die „Kunden“-Entität selbst von externen Anwendungen aus betrachtet werden. Es ist immer noch eine Entität, sodass die Verwendung von Datenentitäten, die näher an realen Geschäftsszenarien sind, eine effektivere Anpassung an externe Szenarien ermöglicht Änderungen.
Was wir oben besprochen haben, ist nur eine Dateneinheit. Wenn wir uns zu bestimmten Geschäftsdomänenmodellen weiterentwickeln, müssen wir häufig mehrere Dateneinheiten gleichzeitig integrieren, um Geschäftsfunktionen abzuschließen. Beispielsweise verlangt die Versicherungspolice, dass Kunden zusätzlich zu den oben genannten Informationen persönliche Gesundheitsinformationen, Informationen zu Kindern, Eltern und den wichtigsten Familienmitgliedern des Partners angeben. Gleichzeitig werden die Bonitätsinformationen des Benutzers von anderen Institutionen und anderen Daten eingeholt Entitätskombinationen werden hauptsächlich innerhalb des Unternehmens verwendet. Aus Sicht der Datennutzung ist es daher am besten, wenn die Datenentität stabil ist, aber nur der Kontaktinformationsteil Die Benutzerinformationen können sich wiederholt ändern. Wenn die Anwendung vollständig von einer Kombination dieser sich ändernden Faktoren abhängt, ist es in der Tat schwierig, die Stabilität der Anwendung zu gewährleisten Verschiedene Anwendungen stützen sich so weit wie möglich nur auf eine bestimmte Entität. Dies kann der erste Schritt zu einer effektiven Verbesserung sein. Zu diesem Zeitpunkt kommen die Vorteile der hierarchischen Eigenschaften wieder zum Vorschein, zum Beispiel können wir diese Informationen entsprechend kombinieren zu verschiedenen Anwendungsthemen:
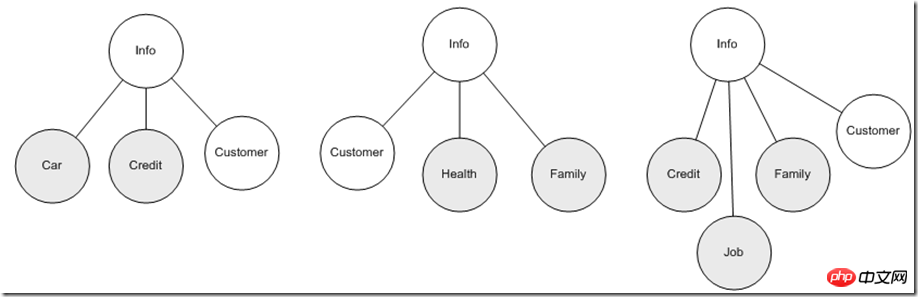
Auf diese Weise steht die Anwendung einer einheitlichen
Umgang mit der Integration von Daten und Inhalten
Die oben genannten Datenentitäten werden eher in einem zentralen Kontext diskutiert, aber neben der konzeptionellen Gestaltung gibt es auch andere Aspekte bei der Verwendung Ein spezifisches Problem ist, wie man sie „zusammenfasst“, was im Allgemeinen durch Datensätze erreicht wird.
(Aber ebenso wie das Wort „Architektur“ überbeansprucht wird, wird „Datenintegration“ von verschiedenen Herstellern auch als eine Kombination verschiedener Konzepte basierend auf ihren eigenen Produkteigenschaften definiert, wie z. B. BIAnbieter sind bestrebt, es als Synonym für ETL darzustellenAnbieter, die Datenaustauschplattformen bereitstellen, beschreiben es als Produkte, die das BizTalk Framework implementieren Bei der Datenintegration geht es für Unternehmen eher darum, die Bereitstellung von Datendiensten unter der Voraussetzung einer effektiven Governance sicherzustellen. Darüber hinaus umfasst die Datenintegration für einige Hersteller auch geschäftliche semantische Kombinationen usw.) Aber Auf welche Themen sollten wir uns als Benutzer konzentrieren?
l Zuordnung von Datenentitäten;
l Verbindung von Datenquellen unter verschiedenen Austauschprotokollen, Branchendatenstandards und Sicherheitskontrollbeschränkungen; >
l Überprüfung und Rekonstruktion von Datenentitäten; l Konvertierung von Datenträgern und Datenträgern Obwohl es theoretisch kein Problem ist, diese Aufgaben mit Codierung zu erledigen, Da die Unternehmensintegrationslogik immer komplexer wird und sich immer schneller ändert, reicht es nicht aus, den Code so zu ändern, dass er mit der 1:N-Integration zurechtkommt, wenn es sich oft um eine M:N-Situation handelt. Gibt es einen einfacheren Weg? Wenn wir nur von der logischen Ebene der „Zuordnung“ sprechen: lObjektorientiertes
Denken sagt uns, wir sollen uns auf Inversion verlassen, versuchen, uns auf Abstraktion statt auf Konkretheit zu verlassen, wie zum Beispiel auf Schnittstellen als Entitätstypen; XML Schema +XSLT
könnte eine Option sein.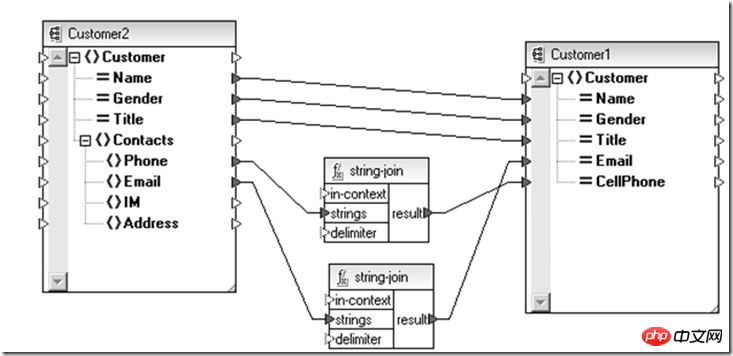
Das Obige ist eine Konvertierung, die durchgeführt wurde, um mit neuen und alten Benutzerentitäten kompatibel zu sein. Ebenso, wenn Sie den oben genannten Teil des Datenentitätsvorgangs Aggregation durchführen müssen Für verschiedene Themen können Sie es auch auf der Ebene der abstrakten Datendefinition (Schema) durch XSLT (Anpassungsbeziehung zwischen Schemas) verwenden.
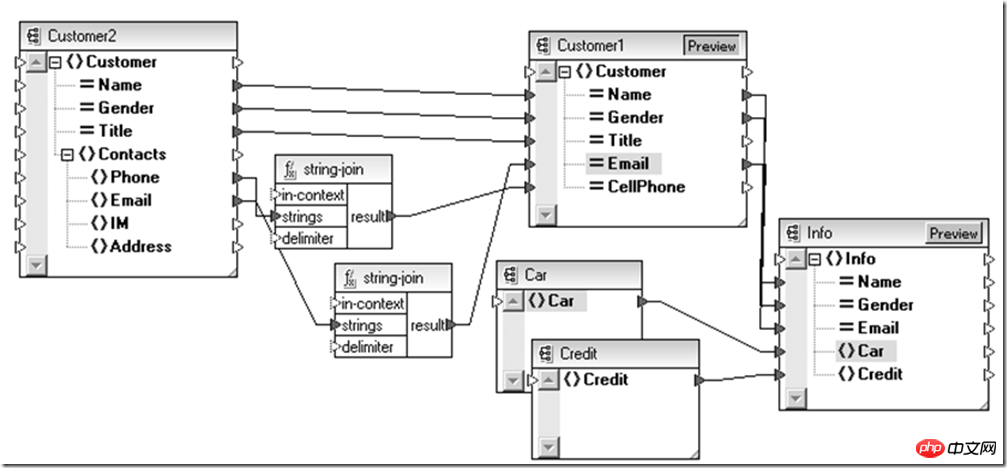
Auf diese Weise können wir sehen, wie die Daten auf Datenentitätsebene aggregiert werden, aber es gibt noch ein Problem, das vorher gelöst werden muss: Fahrzeuginformationen, Kredit Informations- und Legacy-Systeme Die Kundeninformationen werden in der relationalen Datenbank bzw. im Webservice des Partners gespeichert. Wie wird dieser Datenkanal verbunden? Von nun an ist XML immer noch eine gute Wahl.
Daten auf verschiedenen Datenträgern können in ihrer ursprünglichen Form, wie z. B. Klartext, relationale Datenbank, EDI-Nachricht oder SOAP-Nachricht, extrahiert und über verschiedene Informationskanäle-Aggregationspunkte an die Datenintegration übergeben werden , und konvertieren Sie dann heterogene Datenquellen über einen Adapter entsprechend den Anforderungen der Zieldatenquelle.
Wenn zu diesem Zeitpunkt ein Punkt-zu-Punkt-Adapter für jeweils zwei Typen entwickelt wird, entwickelt sich die Gesamtskala entlang des N^2-Level-Trends. Aus diesem Grund können Sie sie genauso gut in XML vereinheitlichen Das ist mit diesen Informationen kompatibel und wird dann verwendet. Nachdem die oben eingeführte XSLT-Technologie die Zuordnung zwischen Datenentitäten durchgeführt hat, konvertiert sie anschließend das XML in die für die Zieldatenquelle erforderliche Form, sodass die Komplexität des gesamten Anpassungssystems auf N reduziert wird Ebene.
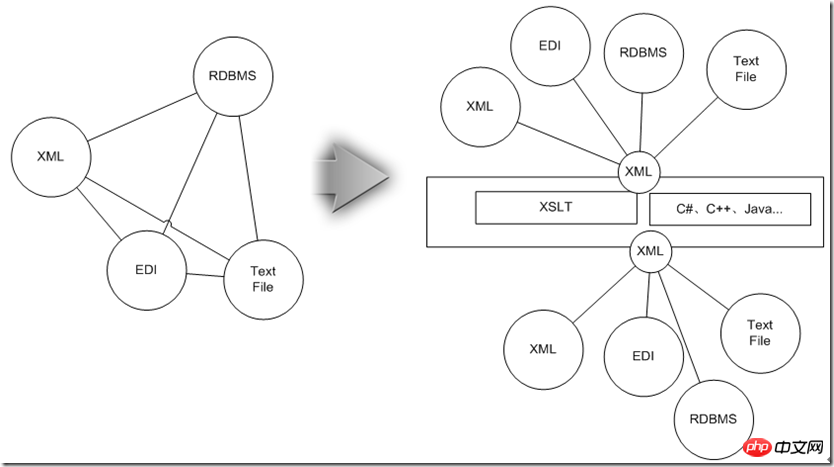
Als nächstes schauen wir uns an, wie die XML-Technologie die erforderlichen Datenintegrationsanforderungen erfüllt:
l Zuordnung von Datenentitäten, Datenmedien und Datenträgern Konvertierung, Überprüfung und Rekonstruktion von Datenentitäten:
Wie oben werden die Daten zunächst einheitlich in XML konvertiert und dann mithilfe der hierarchischen Vorteile von XML verarbeitet und mit XML-spezifischer Technologie kombiniert.
l Die Verbindung von Datenquellen unter verschiedenen Austauschprotokollen, Branchendatenstandards und Sicherheitskontrollbeschränkungen;
XML-Daten können nicht nur Netzwerke und Firewalls überwinden, sondern auch problemlos auf dem Netzwerk verwendet werden In der Internetumgebung (Sie können sie jedoch weiterhin mit der Methode „Message queue “ als Nachrichten definieren) werden die Daten selbst aufgrund spezieller Binäroperationen nicht durch das Austauschprotokoll eingeschränkt. Derzeit verwenden verschiedene Industriestandards grundsätzlich XML, um ihre eigenen Branchen-DMs (Data Modal) zu beschreiben. Auch wenn die Datenentitäten Ihres internen Systems selbst aufgrund von Problemen wie Datenbankdesign und historischem Erbe nicht mit diesen DMs übereinstimmen, gibt es verschiedene Protokolle und Standards für die einheitliche Verwaltung von XML-Daten können die Konvertierung erleichtern. Hinsichtlich der Sicherheit scheint es keine Familie von Sicherheitsstandards zu geben, die besser für die Internetumgebung geeignet ist als die WS-*-bezogenen Protokolle. Alle Standards können ausnahmslos XML-Entitäten verwenden, um die Kombinationsbeziehung zwischen Daten und zusätzlichen Sicherheitsmechanismen zu definieren.
l Orchestrierung des Datenaustauschprozesses;
Für homogene Systemumgebungen oder Plattformen, die ausschließlich auf kompatiblen Middleware-Systemen basieren, können Legacy-Workflow-Mechanismen zur Implementierung der Orchestrierung verwendet werden Zur Anpassung an das serviceorientierte Zeitalter kann der allgemeinere BPEL-Standard übernommen werden. Derzeit handelt es sich bei XML nicht nur um Daten, sondern auch um eine Form von Ausführungsanweisungen , das schon immer als plattformübergreifend beworben wurde. Mit anderen Worten: Der durch XML definierte Austauschprozess ist noch sprachübergreifender.
Es scheint, dass die Integration viele Probleme gelöst hat, aber ein offensichtliches Problem besteht darin, dass wir die gesamte Arbeit möglicherweise selbst implementieren und der Anwendung Schritt für Schritt mitteilen müssen, wie sie zu erledigen ist Wenn wir das Web nicht mehr nur als „neue Dinge“ betrachten, wenn wir es als ein System betrachten, das unseren Informationsinhalt bedient und interagieren kann, wie können wir uns dann diese verstreuten Servicemöglichkeiten präsentieren? Zu diesem Zeitpunkt werden vielleicht die Vorteile der offenen Metadatendefinition von XML wirklich zum Vorschein kommen.
Umgang mit der Komplexität des semantischen Netzwerks
Neben verschiedenen semantischen Algorithmen, wie man verschiedene verstreute Dienste aggregiert, um uns Dienste bereitzustellen, ist einer der Schlüsselfaktoren von XML das Finden Rückgrat der Datenhinweise und Klärung der Beziehungen zwischen Entitäten auf diesem Rückgrat und des Prozesses der schrittweisen Zerlegung und Verfeinerung. Daten auf dieser Ebene sind nicht nur Objekte, die von der Anwendung passiv aufgerufen werden, sie selbst bieten Unterstützung für weitere Schlussfolgerungen durch die Anwendung. Zum Beispiel:
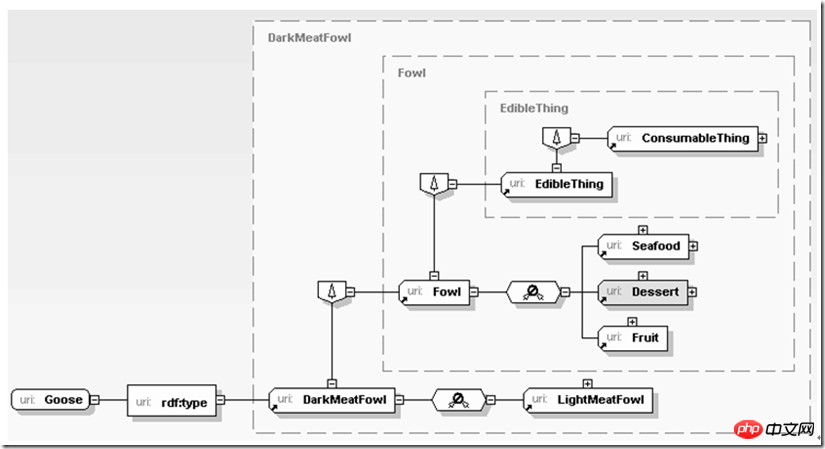
Hier erfährt die Anwendung zunächst, dass es sich bei dem aktuell verarbeiteten Objekt um Gänsefleisch handelt und dunkles Fleisch eine Art Geflügelfleisch ist, sodass die Anwendung essbar ist allmählich daraus schließen, dass Gänsefleisch essbar ist. Der obige Inferenzprozess ist nicht kompliziert, aber wenn er mithilfe einer relationalen Datenbank implementiert wird, ist er noch schwieriger zu implementieren, wenn er im Klartext geschrieben wird. Stellen Sie sich vor, alle Beziehungen zwischen Geflügel, Gemüse, Desserts usw. und Meeresfrüchte werden alle in Form von Beziehungen ausgedrückt. Das Schreiben von Datenbanken oder Texten ist wirklich „schwierig“. XML ist anders. Es kann unseren Denkgewohnheiten auf natürliche Weise nahe kommen und unsere vertraute Semantik auf offene, aber miteinander verflochtene Weise beschreiben, unabhängig davon, ob es sich um den Vorbereitungsprozess für Produktionsmaterialien in einer ERP-Umgebung eines Unternehmens oder um die Vorbereitung zum Kochen für eine Geburtstagsfeier handelt für Einkaufspläne.
Zusammenfassung
Vielleicht zu lange durch die Einschränkungen des zweidimensionalen Rasters eingeschränkt, werden unser Design und unsere Ideen für Anwendungen zunehmend durch die Computerverarbeitung selbst eingeschränkt, aber wenn sich das Geschäftsumfeld ändert, Die Die Zeit zwischen dem Auftreten von Geschäftsanforderungen und der Implementierung und dem Start von Anwendungen wird immer kürzer. Wir müssen unser Denken vom Computer abwenden. Derzeit scheint es vorzuziehen, eine offenere und nähere Datentechnologie einzuführen unser divergentes Denken. Für Unternehmen können wir nach der Implementierung der Daten weiterhin verschiedene ausgereifte Technologien verwenden, um sie zu vervollständigen. Auf einer näheren Geschäftsebene und näher an dieser volatileren Umgebung scheint XML jedoch flexibel und leistungsstark zu sein.
Das obige ist der detaillierte Inhalt vonDetaillierte Einführung in die Verwendung von XML-Denken zum Organisieren von Daten (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Verwenden von dom4j zum Parsen von XML in Java (Beispielcode)
- Wie liest Java XML-Dateien? Spezifische Implementierung
- Java-Beispielcode zum Generieren und Parsen von Dateien und Zeichenfolgen im XML-Format
- Lösung für die Verwendung von Sax zum Parsen von XML in Java
- Java verwendet XPath, um die gemeinsame Nutzung von XML-Beispielen zu analysieren