
Heim >Datenbank >MySQL-Tutorial >Detaillierte Erläuterung der MySQL-Indizes
Detaillierte Erläuterung der MySQL-Indizes

- 迷茫Original
- 2017-03-26 13:16:281632Durchsuche
Der Index von MySQL erfolgt über B+tree. B+tree ist eine Variante des ausgeglichenen Binärbaums, daher ist die Abfragegeschwindigkeit sehr hoch.
Indizes werden hauptsächlich in Clustered-Indizes und Hilfsindizes unterteilt:
Clustered-Index: Die Daten in MySQL werden über den Clustered-Index des Primärschlüssels gespeichert Im Blattknoten werden die Daten jeder Zeile gespeichert, daher fragen wir über den Primärschlüssel ab
Der Grund, warum es so schnell ist wie zuvor, liegt darin, dass der Primärschlüssel ein Clustered-Index ist und in der tatsächlichen Verwendung nur einer vorhanden ist Ein solcher B+-Baum wird erstellt, was erklären kann, warum der Primärschlüssel der Einzige ist.
Zitat aus dem Bild im Internet:
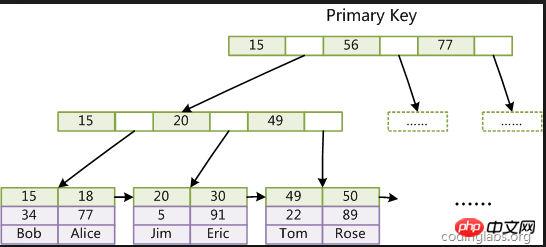
Die Suche auf jeder Ebene ist eine E/A-Operation, und im Allgemeinen beträgt die Anzahl der B + Baumschichten 2 -4. Im schlimmsten Fall sind also nur 4 IO-Operationen erforderlich.
Hilfsindex : Der Unterschied zwischen Hilfsindex und Clustered-Index besteht darin, dass nicht alle Daten in Blattknoten gespeichert werden, sondern der Speicherort der Daten. Dies entspricht der Verwendung des Hilfsindex
zum Suchen der Daten. Anschließend müssen wir detaillierte Informationen über den Baum des Clustered-Index finden.
Zitat aus dem Diagramm im Internet:
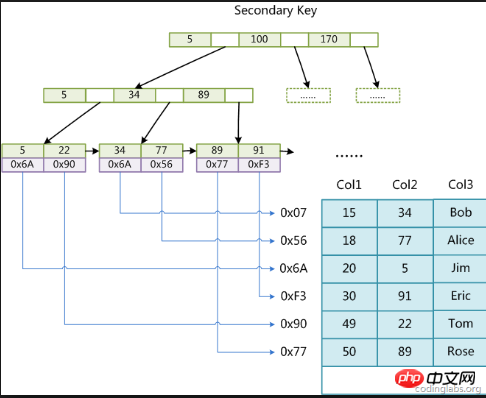
Dieses Diagramm ist ein logisches Diagramm, aber die unterste Ebene zeigt über die Blattknoten auf den Clustered-Index. Das heißt, als nächstes müssen Sie die
-Logik des ersten Diagrammtyps durchgehen.
Das Endergebnis ist also, dass mehrere Hilfsindexbäume auf einen Clustered-Indexbaum verweisen
(Die Zeichnung ist wirklich hässlich)
Über den Zeitpunkt der Erstellung eines Index
Da es sich um einen Baum handelt, wird er durch eine binäre Suche abgerufen, sodass er als Bedingung hinter wo und diesem The anwendbar ist Die Werte liegen in einem weiten Bereich und eignen sich für die Indexerstellung. Es ist nicht für Personen mit einem kleinen Bereich geeignet (is_delete, sex usw. Aufzählungen).
Für bestimmte Situationen können wir nach Showindex analysieren:
show index from company_related_person
Ergebnis:

Dann nach Kardinalität berechnen
select 105/(select count(*) from company_related_person) from DUAL
Das hier erhaltene Ergebnis ist 0,913 (dieser Wert hängt von der Speicherkapazität ab, es ist am besten, eine bestimmte Datenmenge zu haben, je näher dieser Wert an 1 liegt, desto höher ist die Indexeffizienz). Wenn der berechnete Wert sehr klein ist, wird empfohlen, keinen Index zu erstellen
Wir können die Verwendung des Index auch über „explain“ anzeigen
EXPLAIN select * from company_related_person where company_id='2'
Ausgabe

Schlüssel dargestellt Ist die aktuell verwendete Indexspalte. Das letzte Extra stellt die verwendete Methode dar. Die Verwendung eines Index stellt die Verwendung eines Index dar.
Für komplexe SQL-Anweisungen mit langsamen Abfragen können Sie diese Methoden zur Analyse verwenden .
Das Ziel der SQL-Leistungsoptimierung: mindestens die Bereichsebene erreichen, die Anforderung ist die Ref-Ebene, wenn es Konstanten sein kann, ist es am besten.
1) Konstanten In einer einzelnen Tabelle gibt es höchstens eine passende Zeile (Primärschlüssel oder eindeutiger Index) und die Daten können während der Optimierungsphase gelesen werden.
2) Ref bezieht sich auf die Verwendung eines normalen Index.
3) „Range“ führt einen Bereichsabruf für den Index durch
4) „Index“ bedeutet, direkt von der Festplatte zu lesen
Aus der obigen Abbildung können wir auch ersehen, dass wir die Referenz verwenden
Über den Unterschied zwischen Index und Schlüssel:
Wenn wir einen Index erstellen, haben wir oft die Frage: Was ist der Unterschied zwischen Index und Schlüssel? . Schlüssel ist ein Schlüsselwert, der Teil der relationalen Modelltheorie ist, z. B. Primärschlüssel (Primärschlüssel), Fremdschlüssel (Fremdschlüssel) usw., der zur Überprüfung der Datenintegrität und zur Eindeutigkeitsbeschränkung verwendet wird. Der Index befindet sich auf der Implementierungsebene. Sie können beispielsweise jede Spalte einer Tabelle indizieren. Wenn sich die indizierte Spalte dann in der SQL-Anweisung in der Where-Bedingung befindet, können Sie eine schnelle Datenlokalisierung und damit einen schnellen Abruf erhalten. Beim Unique Index handelt es sich lediglich um einen Indextyp. Die Einrichtung des Unique Index bedeutet, dass die Daten in dieser Spalte nicht wiederholt werden können
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der MySQL-Indizes. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!