
Heim >Backend-Entwicklung >C#.Net-Tutorial >.NET Framework – Ausführliche Erläuterung der Geschichte der Speicherverwaltung sowie der Erstellung und Zerstörung von Variablen (Bild)
.NET Framework – Ausführliche Erläuterung der Geschichte der Speicherverwaltung sowie der Erstellung und Zerstörung von Variablen (Bild)

- 黄舟Original
- 2017-03-18 13:34:271377Durchsuche
Vorwort
.net运行库通过垃圾回收器自动处理回收托管资源,非托管的资源需要手动编码处理。理解内存管理的工作原理,有助于提高应用程序的速度和性能。废话少说,切入正题。 主要阐述的概念见下图:
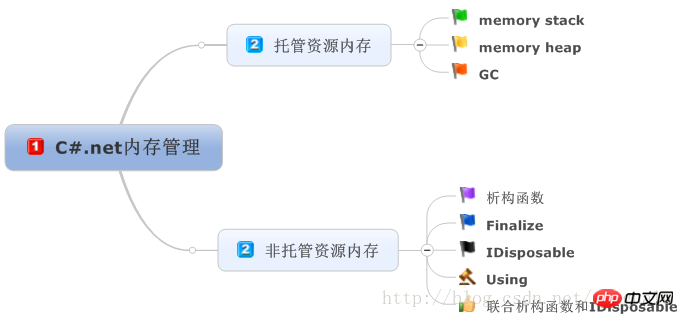
Konzepte
Erinnerung: schon wieder Bekannt als virtueller Speicher oder virtueller Adressraum, verwendet Windows ein virtuelles Adressierungssystem, um verfügbare Speicheradressen im Hintergrund automatisch den tatsächlichen Adressen im Hardwarespeicher zuzuordnen. Das Ergebnis ist, dass jeder Prozess auf einem 32-Bit-Prozessor 4 GB Speicher zum Speichern aller Teile des Programms verwenden kann, einschließlich ausführbarem Code (Exe-Dateien), aller vom Code geladenen DLLs und der beim Ausführen des Programms verwendeten DLLs Inhalte aller Variablen.
Speicherstapel
Im virtuellen Speicher des Prozesses gibt es einen Bereich, in dem die Lebensdauer einer Variablen verschachtelt werden muss.
Memory Heap
Im virtuellen Speicher eines Prozesses sind Daten noch lange nach Beenden der Methode verfügbar.
Verwaltete Ressourcen
Ressourcen, die der Garbage Collector automatisch im Hintergrund verarbeiten kann
Nicht verwaltete Ressourcen
Müssen manuell über Destruktor, Finalisieren, Ressourcen codiert werden verarbeitet durch Mechanismen oder Methoden wie IDisposable und Using.
Speicherstapel
Werttypdaten werden im Speicherstapel gespeichert, und der Instanzadresswert des Referenztyps wird ebenfalls im Speicherstapel abgelegt (siehe Diskussion). des Speicherheaps). Das Funktionsprinzip des Stapels kann durch den folgenden Codeabschnitt verstanden werden:
{ //block1开始
int a;
//solve something
{//block2开始
int b;
// solve something else
}//block2结束}//block1结束Beachten Sie 2 Punkte im obigen Code:
1) Der Umfang der Variablen in C# folgt dem Prinzip, zuerst zu deklarieren, dann den Gültigkeitsbereich zu verlassen und dann zuerst den Gültigkeitsbereich zu deklarieren, d. h. b wird zuerst freigegeben und a wird später freigegeben. Die Freigabereihenfolge ist immer entgegengesetzt zur Reihenfolge, in der sie Speicher zuweisen.
2) b befindet sich in einem separaten Blockbereich (block2) und der Blockname, in dem sich a befindet, ist block1, der in block2 verschachtelt ist .
Bitte sehen Sie sich das Diagramm unten an:
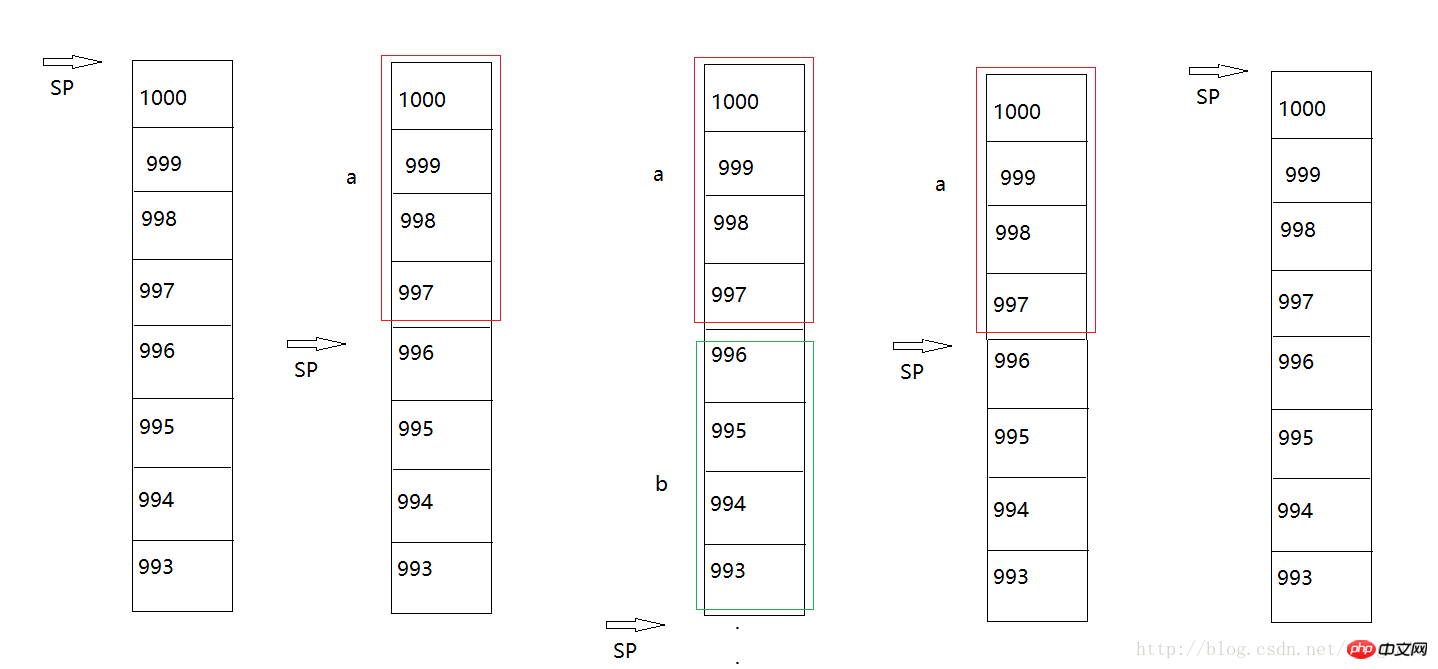
Bei der Stapelspeicherverwaltung ist dies immer der Fall gepflegt Ein Stapelzeiger, der immer auf die nächste verfügbare Adresse im Stationsbereich mit dem Namen sp zeigt, wie in der Abbildung gezeigt, vorausgesetzt, er zeigt auf die Adresse mit der Nummer 1000.
Die Variable a wird zuerst auf den Stapel geschoben. Angenommen, der Typ int belegt 4 Bytes, also 997 bis 1000 bis 996. Es ist ersichtlich, dass die Wachstumsrichtung des Speicherstapels von der hohen Adresse zur niedrigen Adresse ist.
Dann wird b auf den Stapel geschoben, belegt 993 ~ 996 und sp zeigt auf 992. Wenn Block block2 überschritten wird, gibt Variable b sofort den Speicher auf dem Speicherstapel frei und sp erhöht sich um 4 Bytes und zeigt auf 996.
Beim Bewegen nach außen und über den Block Block1 hinaus wird die Variable a sofort freigegeben. Zu diesem Zeitpunkt fügt sp weitere 4 Bytes hinzu und zeigt auf die ursprüngliche Anfangsadresse 1000 schiebt es dann auf den Stapel, diese Adressen werden wieder belegt und dann freigegeben, zyklisch hin und her.
Speicherheap
Obwohl der Stapel eine sehr hohe Leistung aufweist, ist er dennoch nicht für alle Variablen sehr flexibel, da die Lebensdauer der auf dem Speicherstapel befindlichen Variablen verschachtelt sein muss. In vielen Fällen ist diese Anforderung zu streng, da einige Daten noch lange nach Beendigung der Methode verfügbar sein sollen.
Solange der mit dem new-Operator angeforderte Heap-Speicherplatz erfüllt ist, ist die Verzögerung des Datendeklarationszeitraums erfüllt, wie bei allen Referenztypen. Verwenden Sie Managed Heap in .net, um Daten im Speicher-Heap zu verwalten.
Der verwaltete Heap in .net unterscheidet sich vom von C++ verwendeten Heap. Er arbeitet unter der Kontrolle des Garbage Collectors, während der C++-Heap auf niedriger Ebene ist.
Da Referenztypdaten auf dem verwalteten Heap gespeichert werden, wie werden sie gespeichert? Bitte schauen Sie sich den folgenden Code an
void Shout()
{
Monkey xingxing; //猴子类
xingxing = new Monkey();
} In diesem Code gehen wir von zwei Klassen aus, Monkey und AIMonkey, wobei die AIMonkey-Klasse das Monkey-Objekt erweitert.
Hier nennen wir Monkey ein Objekt und xingxing eine Instanz davon.
Deklarieren Sie zunächst eine Monkey-Referenz xingxing, weisen Sie Speicherplatz für diese Referenz auf dem Stapel zu. Denken Sie daran, dass dies nur eine Referenz und nicht das eigentliche Monkey-Objekt ist. Das ist wichtig zu bedenken! ! !
Schauen Sie sich dann die zweite Codezeile an:
xingxing = new Monkey();
它完成的操作:首先,它分配堆上的内存,以储存Monkey对象,注意了!!!这是一个真正的对象,它不是一个占用4个字节的地址!!! 假定Monkey对象占用64个字节,这64个字节包含了Monkey实例的字段,和.NET中用于识别和管理Monkey类实例的一些信息。这64个字节实在内存堆上分配的,假定内存堆上的地址1937~2000。new操作符返回一个内存地址,假定为997~1000,并赋值给xingxing。示意图如下所示:
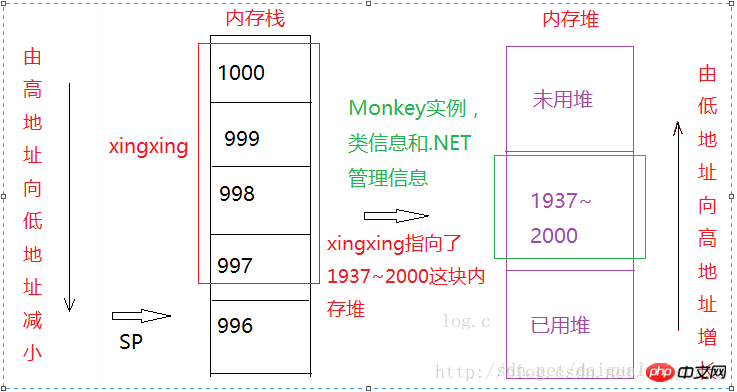
记住一点:
与内存栈不同的是,堆上的内存是向上分配的,由低地址到高地址。
从上面的例子中,可以看出建立引用实例的过程要比建立值变量的过程更复杂,系统开销更大。那么既然开销这么大,它到底优势何在呢?引用数据类型强大到底在哪里???
请看下面代码:
{//block1
Monkey xingxing; //猴子类
xingxing = new Monkey();
{//block2
Monkey jingjing = xingxing; //jingjing也引用了Monkey对象
//do something
} //jinjing超出作用域,它从栈中删除
//现在只有xingxing还在引用Monkey}//xingxing超出作用域,它从栈中删除//现在没有在引用Monkey的了 把一个引用实例的值xingxing赋值予另一个相同类型的实例jingjing,这样的结果便是有两个引用内存中的同一个对象Monkey了。当一个实例超出作用域时,它会从栈中删除,但引用对象的数据还是保留在堆中,一直到程序终止,或垃圾回收器回收它位置,而只有该数据不再有任何实例引用它时,它才会被删除!
随便举一个实际应用引用的简单例子:
//从界面抓取数据放到list中List<Person> persons = getPersonsFromUI(); //retrieve these persons from DBList<person> personsFromDB = retrievePersonsFromDB(); //do something to personsFromDBgetSomethingToPersonsFromDB();
请问对personsFromDB的改变,能在界面上及时相应出来吗?
不能!
请看下面修改代码:
//从界面抓取数据放到list中List<Person> persons = getPersonsFromUI();
//retrieve these persons from DBList<Person> personsFromDB = retrievePersonsFromDB();
int cnt = persons.Count;for(int i=0;i<cnt;i++)
{
persons[i]= personsFromDB [i] ;
}
//do something to personsFromDBgetSomethingToPersonsFromDB(); 修改后,数据能立即响应在界面上。因为persons与UI绑定,所有修改在persons上,自然可以立即响应。
这就是引用数据类型的强大之处,在C#.NET中广泛使用了这个特性。这表明,我们可以对数据的生存期进行非常强大的控制,因为只要保持对数据的引用,该数据就肯定位于堆上!!!
这也表明了基于栈的实例与基于堆的对象的生存期不匹配!
垃圾回收器 GC
内存堆上会有碎片形成,.NET垃圾回收器会压缩内存堆,移动对象和修改对象的所有引用的地址,这是托管的堆与非托管的堆的区别之一。
.NET的托管堆只需要读取堆指针的值即可,但是非托管的旧堆需要遍历地址链表,找出一个地方来放置新数据,所以在.NET下实例化对象要快得多。
堆的第一部分称为第0代,这部分驻留了最新的对象。在第0代垃圾回收过程中遗留下来的旧对象放在第1代对应的部分上,依次递归下去。。。
承上启下
以上部分便是对托管资源的内存管理部分,这些都是在后台由.NET自动执行的。下面看下非托管资源的内存管理,比如这些资源可能是UI句柄,network连接,文件句柄,Image对象等。.NET主要通过三种机制来做这件事。分别为析构函数、IDisposable接口,和两者的结合处理方法,以此实现最好的处理结果。下面分别看一下。
析构函数
C#编译器在编译析构函数时,它会隐式地把析构函数的代码编译为等价于Finalize()方法的代码,并确定执行父类的Finalize()方法。看下面的代码:
public class Person
{
~Person()
{ //析构实现
}
}~Person()析构函数生成的IL的C#代码:
protected override void Finalize()
{ try
{ //析构实现
} finally
{ base.Finalize();
}
} 放在finally块中确保父类的Finalize()一定调用。
C#析构函数要比C++析构函数的使用少很多,因为它的问题是不确定性。在销毁C++对象时,其析构函数会立即执行。但由于C#使用垃圾回收器,无法确定C#对象的析构函数何时执行。如果对象占用了 宝贵的资源,而需要尽快释放资源,此时就不能等待垃圾回收器来释放了。
第一次调用析构函数时,有析构函数的对象需要第二次调用析构函数,才会真正删除对象。如果频繁使用析构,对性能的影响非常大。
IDisposable接口
在C#中,推荐使用IDisposable接口替代析构函数,该模式为释放非托管资源提供了确定的机制,而不像析构那样何时执行不确定。
假定Person对象依赖于某些外部资源,且实现IDisposable接口,如果要释放它,可以这样:
class Person:IDisposable
{ public void Dispose()
{ //implementation
}
}
Person xingxing = new Person();//dom somethingxingxing .Dispose();上面代码如果在处理过程中出现异常,这段代码就没有释放xingxing,所以修改为:
Person xingxing = null;try{
xingxing = new Person(); //do something}finally{ if(xingxing !=null)
{
xingxing.Dispose();
}
}C#提供了一种语法糖,叫做using,来简化以上操作。
using(Person xingxing = new Person())
{ // do something} using在此处的语义不同于普通的引用类库作用。using用在此处的功能,仅仅是简化了代码,这种语法糖可以少用!!!
总之,实现IDisposable的对象,在释放非托管资源时,必须手动调用Dispose()方法。因此一旦忘记,就会造成资源泄漏。如下所示:
Image backImage = this.BackgroundImage;
if (backImage != null)
{
backImage.Dispose();
SessionToImage.DeleteImage(_imageFilePath, _imageFileName);
this.BackgroundImage = null;
}在上面那个例子中,backImage已经确定不再用了,并且backImage又是通过Image.FromFile(fullPathWay)从物理磁盘上读取的,是非托管的资源,所以需要Dispose()一下,这样读取Image的这个进程就被关闭了。如果忘记写backImage.Dispose();就会造成资源泄漏!
结合 析构函数和IDisposable这2种机制
一般情况下,最好的方法是实现两种机制,获得这两种机制的优点。因为正确调用Dispose()方法,同时把实现析构函数作为一种安全机制,以防没有调用Dispose()方法。请参考一种结合两种方法释放托管和非托管资源的机制:
public class Person:IDisposable
{ private bool isDisposed = false;
//实现IDisposable接口
public void Dispose()
{
//为true表示清理托管和非托管资源
Dispose(true);
//告诉垃圾回收器不要调用析构函数了
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
//isDisposed: 是否对象已经被清理掉了
if(!isDisposed)
{
if(disposing)
{
//清理托管资源
}
//清理非托管资源
}
isDisposed = true;
}
~Person()
{
//false:调用后只清理非托管资源
//托管资源会被垃圾回收器的一个单独线程Finalize()
Dispose(false);
}
}当这个对象的使用者,直接调用了Dispose()方法,比如
Person xingxing = new Person();//do somethingperson.Dispose();
此时调用IDisposable.Dispose()方法,指定应清理所有与该对象相关的资源,包括托管和非托管资源。
如果未调用Dispose()方法,则是由析构函数处理掉托管和非托管资源。
Das obige ist der detaillierte Inhalt von.NET Framework – Ausführliche Erläuterung der Geschichte der Speicherverwaltung sowie der Erstellung und Zerstörung von Variablen (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- .Net Core-Grafikverifizierungscode
- Laden der .NET Core-Konfigurationsdatei und DI-Injektion von Konfigurationsdaten
- Dokumentation zum .NET Core CLI-Tool dotnet-publish
- asp.net verwendet .net-Steuerelemente, um Dropdown-Navigationsmenüs zu erstellen
- So erhalten Sie den Namen des Controllers in Asp.net MVC