
Heim >Datenbank >MySQL-Tutorial >Leistungsstarke MySQL-detaillierte Optimierung bestimmter Abfragetypen
Leistungsstarke MySQL-detaillierte Optimierung bestimmter Abfragetypen

- 黄舟Original
- 2017-03-15 17:23:481817Durchsuche
Dieser Abschnitt ist hauptsächlich für einige spezifische Arten von Optimierungsabfragen gedacht:
(1) Zählabfrageoptimierung;
(2) Verwandte Abfrage
(3) Unterabfrage
(4) GROUP BY- und DISTINCT-Optimierung
(5) LIMIT-Paging-Optimierung
Anzahlabfrageoptimierung
Die Rolle der COUNT()-Aggregatfunktion:
(1) Zählen Sie die Anzahl der Werte in einem bestimmten Spalte, und Sie können auch die Anzahl der Zeilen zählen. Es ist zu beachten, dass beim Zählen von Spaltenwerten der Spaltenwert nicht leer sein darf (NULL wird nicht gezählt)
(2) Zählen Sie die Anzahl der Zeilen im Ergebnissatz. Wenn der Spaltenwert nicht leer sein darf, wird die Anzahl der Zeilen in der Tabelle gezählt. Um dies sicherzustellen, müssen Sie jedoch COUNT() verwenden, um die Anzahl der Zeilen im Ergebnissatz zu ermitteln. Der Platzhalter ignoriert direkt alle Spaltenwerte und berechnet direkt die Anzahl der Zeilen zur Optimierung.
Für die MyISAM-Speicher-Engine ist COUNT(*) sehr schnell, wenn die Where-Abfragebedingungen nicht auf eine einzelne Tabelle beschränkt sind, da MyISAM selbst bereits die Gesamtzahl der Zeilen gespeichert hat. Wenn Qualifizierungsbedingungen vorliegen, sind auch Abfragestatistiken erforderlich.
Das Folgende ist ein einfaches Optimierungsbeispiel:
(1) Optimierung 1:
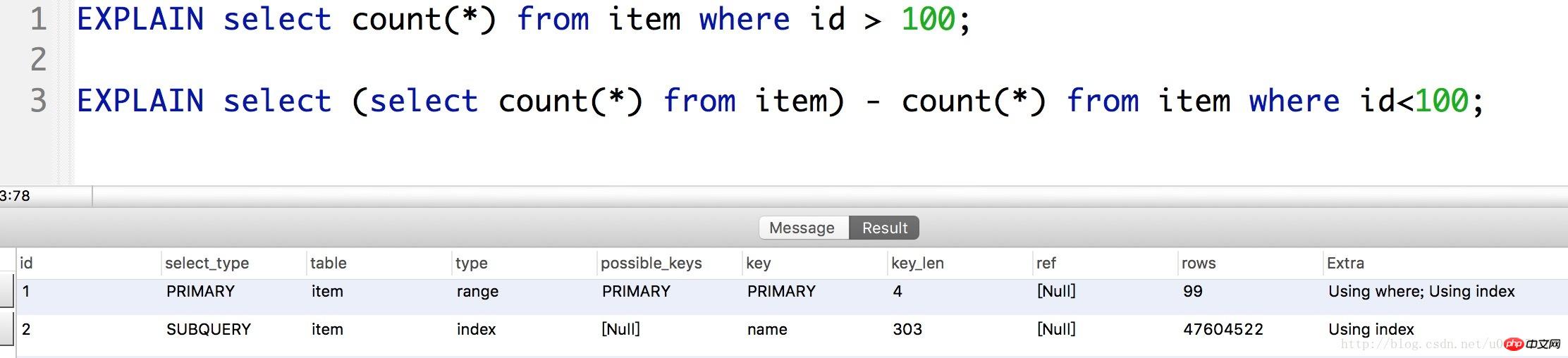
Es ist ersichtlich, dass wir die Aufzeichnungen direkt überprüfen id>100 , wobei mehr als 20 Millionen Datensatzzeilen gescannt werden. Aber aufgrund der COUNT()-Funktion können wir count() - (id
(2) Optimierung 2:
Darüber hinaus besteht eine weitere Optimierungsmethode darin, einen Covering-Index zu verwenden.
Assoziative Abfrageoptimierung
(1) Stellen Sie sicher, dass es einen Index für die Spalte der ON- oder USING-Klausel gibt. Wenn Sie einen Index erstellen, müssen Sie die Reihenfolge der Zuordnung berücksichtigen. Wenn Tabelle A und Tabelle B mit Spalte c verknüpft sind und die Zuordnungsreihenfolge des Optimierers B, A lautet, müssen Sie nur einen Index für Tabelle A erstellen. Nicht verwendete Indizes belegen Speicherplatz
(2) Stellen Sie sicher, dass der Ausdruck in allen Gruppierungs- und Sortiervorgängen nur Spalten in einer Tabelle betrifft. Auf diese Weise ist es für MySQL möglich, die Indexoptimierung
Unterabfrage
zu verwenden. Verwenden Sie Unterabfragen so wenig wie möglich, da Unterabfragen temporäre Tabellen generieren, es sei denn like count(*) Die temporäre Tabelle ist sehr klein.
GROUP BY- und DISTINCT-Optimierung
Der effektivste Weg zur Optimierung von GROUP BY und DISTINCT ist die Verwendung von Indizes.
Wenn der Index nicht verwendet werden kann, wird die Gruppierung nach zwei Strategien durchgeführt: temporäre Tabellen- oder Dateisortierung zur Gruppierung.
Alle Spalten für die Gruppierung müssen indiziert sein. Beispiel:
select product, count(*) from orders group by product;
Eine solche Abfrage muss einen Index für das Produkt erstellen.
LIMIT Paging-Optimierung
Bei der Durchführung von Paging-Vorgängen werden einige Daten normalerweise über Offsets abgefragt. In Verbindung mit der erläuterten Reihenfolge ist die Leistung dann im Allgemeinen gut.
Achten Sie darauf, der Spalte „Reihenfolge nach“ einen Index hinzuzufügen.
Aber für den Grenzwert 10.000, 10 müssen Sie zum Abrufen der angestrebten 10 Datensätze zunächst die vorherigen 10.000 Datensätze abfragen. Der Aufwand ist sehr hoch. In diesem Fall ist die Verwendung eines Deckungsindex die einfachste Möglichkeit zur Optimierung.
Das obige ist der detaillierte Inhalt vonLeistungsstarke MySQL-detaillierte Optimierung bestimmter Abfragetypen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!