
Heim >Datenbank >MySQL-Tutorial >Denken Sie daran, ein langsames Abfrageereignis zu teilen, das durch eine Fehleinschätzung des Online-MySQL-Optimierers verursacht wurde
Denken Sie daran, ein langsames Abfrageereignis zu teilen, das durch eine Fehleinschätzung des Online-MySQL-Optimierers verursacht wurde

- 黄舟Original
- 2017-03-06 13:42:571090Durchsuche
In diesem Artikel werden hauptsächlich die relevanten Informationen und die endgültige Lösung für ein langsames Abfrageereignis vorgestellt, das durch eine Fehleinschätzung des Online-MySQL-Optimierers verursacht wurde. Ich möchte ihn mit Ihnen teilen und hoffe, Ihnen etwas Inspiration zu geben.
Vorwort:
Ich habe wahnsinnig langsame Abfragen und Anforderungs-Timeout-Alarme erhalten und die Ausnahmen von MySQL-Anfragen anhand von Metriken analysiert. Ich habe viele langsame Abfragen mit cli gesehen –> show proceslist. Dieses SQL existierte vorher nicht, aber dieses Problem trat später aufgrund der Zunahme des Datenvolumens auf. Obwohl die Feed-Tabelle bis zu 100 Millionen groß ist, werden die häufigen E/A-Vorgänge nicht durch die Ineffizienz von innodb_buffer_pool_size verursacht, da die Feed-Flussinformationen die Merkmale der aktuellen Aktualität aufweisen. Später, nachdem die Ausführungsplananalyse näher erläutert wurde, wurde der Grund gefunden. Der MySQL-Abfrageoptimierer wählte einen Index, den er für effizient hielt.
Der MySQL-Abfrageoptimierer ist in den meisten Fällen zuverlässig. Wenn Ihre SQL-Sprache jedoch mehrere Indizes enthält, ist das Endergebnis oft etwas zögerlich. Da MySQL nur einen Index für dasselbe SQL verwenden kann, welchen soll ich wählen? Wenn die Datenmenge gering ist, veröffentlicht der MySQL-Optimierer den Primärschlüsselindex und gibt Index und Eindeutigkeit Vorrang. Wenn Sie eine Datenebene erreichen und Ihre Abfrageoperation abgeschlossen ist, verwendet der MySQL-Abfrageoptimierer wahrscheinlich den Primärschlüssel!
Denken Sie an einen Satz: Die Optimierung von MySQL-Abfragen basiert auf Überlegungen zu Abrufkosten und nicht auf Zeitkosten. Der Optimierer berechnet die Kosten basierend auf dem vorhandenen Datenstatus, anstatt tatsächlich SQL auszuführen.
Daher kann der MySQL-Optimierer nicht jedes Mal Optimierungsergebnisse erzielen. Wenn Sie die Kosten für jeden Index genau ermitteln möchten, müssen Sie sie einmal durchführen. Daher handelt es sich bei der Kostenanalyse nur um eine Schätzung.
Die Tabelle, über die wir hier sprechen, ist die Feed-Informationsflusstabelle. Wir wissen, dass auf die Feed-Informationsflusstabelle nicht nur häufig zugegriffen wird, sondern auch eine große Datenmenge vorhanden ist. Die Datenstruktur dieser Tabelle ist jedoch sehr einfach und der Index ist ebenfalls einfach. Es gibt insgesamt nur zwei Indizes, einen ist der Primärschlüsselindex und der andere ist der eindeutige Schlüsselindex.
Wie folgt: Die Größe dieser Tabelle hat die Milliardengrenze erreicht, da genügend Caches vorhanden sind und aus verschiedenen Gründen keine Zeit bleibt, die Datenbank in Tabellen aufzuteilen.
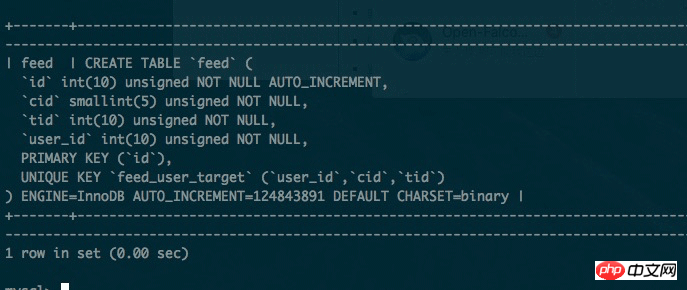
Das Problem ist folgendes: Wenn die Datengröße weniger als 100 Millionen beträgt, wählt der MySQL-Optimierer die Verwendung des Indexindex Abfrage Der Optimierer entscheidet sich für die Verwendung des Primärschlüsselindex. Das Problem dabei ist, dass die Abfragegeschwindigkeit zu langsam ist.
Dies ist die normale Situation:
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
partitions: NULL
type: range
possible_keys: PRIMARY,feed_user_target
key: feed_user_target
key_len: 6
ref: NULL
rows: 18
filtered: 50.00
Extra: Using where; Using index; Using filesort
1 row in set, 1 warning (0.00 sec)
Die gleiche SQL-Anweisung, nachdem sich das Datenvolumen erheblich geändert hat, MySQL-Abfrageoptimierung Auch die Indexauswahl des Servers hat sich geändert.
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
type: range
possible_keys: PRIMARY,feed_user_target
key: PRIMARY
key_len: 4
ref: NULL
rows: 11873197
Extra: Using where
1 row in set (0.00 sec)
Dann besteht die Lösung darin, Force Index zu verwenden, um den Abfrageoptimierer zu zwingen, den von uns angegebenen Index zu verwenden. Dies ist eine Python-Entwicklungsumgebung. Gängige Python-ORMs verfügen über Force-Index-, Ignore-Index- und Benutzerindex-Parameter.
explain SELECT * FROM `feed` force index (feed_user_target) WHERE user_id IN (116537309,116709093,116709377) ...
Wie können wir also dieses Problem verhindern? Aufgrund der Datenzunahme wählt der MySQL-Optimierer einen ineffizienten Index?
Ich habe Datenbankadministratoren mehrerer Fabriken um Rat zu diesem Problem gebeten und die Antworten, die ich bekam, waren die gleichen wie bei unserer Methode. Das Problem kann nur durch spätere langsame Abfragen erkannt werden und dann in der SQL-Anweisung einen Force-Index angeben, um das Indexproblem zu lösen. Darüber hinaus werden solche Probleme in den frühen Phasen der Online-Einführung des Systems vermieden, aber häufig kooperieren Geschäftsentwickler mit der Überprüfungsarbeit des DBA in der frühen Phase, aber in der späteren Phase, um Ärger zu vermeiden, oder sie Denken Sie, dass es kein Problem gibt, sie verursachen MySQL-Abfrageunfälle.
Ich weiß selbst wenig über die Indexauswahlregeln des MySQL-Optimierers und habe vor, später Zeit damit zu verbringen, die Regeln zu studieren
Das Obige ist eine gemeinsame Darstellung eines langsamen Abfrageereignisses, das durch eine Fehleinschätzung von verursacht wurde Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (www.php.cn).