
Heim >Backend-Entwicklung >PHP-Tutorial >Der Weg zum Wachstum der Back-End-Systemarchitektur von News APP – Detaillierte Grafik- und Texterklärung zum Design der Hochverfügbarkeitsarchitektur
Der Weg zum Wachstum der Back-End-Systemarchitektur von News APP – Detaillierte Grafik- und Texterklärung zum Design der Hochverfügbarkeitsarchitektur

- 黄舟Original
- 2017-03-06 09:37:475543Durchsuche
Bitte geben Sie die Quelle für den Nachdruck an: Nachrichten Wachstumspfad der APP-Back-End-Systemarchitektur – Hochverfügbarkeitsarchitekturdesign
1. Zum ersten Mal das Heilige Land betreten
2. Fundamentbau: komplette Rekonstruktion
3. Goldenes Elixier: Treten Sie in die Falle. . Und es ist eine große Falle
4. Yuanying: Angesichts der Herausforderungen kommt der Verkehr
5. Out of Body: Anpassung und Optimierung der Serverarchitektur
6. Die Trübsal überwinden: Service-Governance-Plattform
7. Mahayana: hohe Verfügbarkeit des Servers
8. Aufstieg: Hohe Verfügbarkeit des Clients – [2017 HTTPS+HTTP-DNS]
1. Zum ersten Mal das Heilige Land betreten
Aufgrund von Arbeitsvereinbarungen wurden einige Senioren aus dem ursprünglichen APP-Backend in andere Geschäftsabteilungen versetzt. Sie begannen Ende 2015, die Backend-Arbeit für den Kunden zu übernehmen. Das erste Mal das Heilige Land zu betreten war wie der Eintritt ins Fegefeuer.
Da zu diesem Zeitpunkt noch eine Menge Geschäftsentwicklungsarbeit ansteht, die die kontinuierliche Unterstützung meiner Freunde erfordert, hatte ich keine andere Wahl, als mich allein mit der APP-Back-End-Entwicklung zu befassen.
Von der Content-Business-Entwicklung, mit der ich früher vertraut war, bis hin zur Entwicklung von APP-Back-End-Schnittstellen weiß ich immer noch nicht viel Fachwissen über APP, das ich am Ende nur konsultieren und von ihnen lernen kann Gleichzeitig möchte ich mich am Ende bei meinen Klassenkameraden für ihre Hilfe bedanken. Trotz verschiedener Schwierigkeiten wird das Unternehmen weiter voranschreiten und die Versionsiterationen sind noch im Gange.
Auf diese Weise habe ich jeden Tag programmiert und Fehler behoben, während ich mich gleichzeitig um die unterschiedlichen Bedürfnisse von mehr als einem Dutzend wunderschöner Produktmädchen gekümmert habe.
Die alte API wurde Anfang 2012 entwickelt. Bis Ende 2015 wurde sie in fast vier Jahren von vier Personengruppen gehandhabt. Sie können sich vorstellen, wie viele Fallstricke es gab, mitten in der Nacht aufzustehen um Online-Fehler zu beheben.
Gleichzeitig waren die Leistungsprobleme der alten API nicht optimistisch. Die Reaktionszeit der Schnittstelle war zu diesem Zeitpunkt noch gering, und die ursprünglichen Entwickler schenkten der Servicearchitektur und -optimierung keine besondere Aufmerksamkeit. Da die Anzahl der Benutzer schnell wächst, wird der Dienst nach dem Start von PUSH ausfallen und wir haben keine andere Wahl, als ihn auszuführen. Auf diese Weise dauerte dies mehr als einen Monat, während intensive Versionsiterationen unterstützt, Fallstricke beschritten und geschlossen und natürlich stillschweigend Löcher gegraben wurden.
Nachdem ich den gesamten alten API-Code vollständig verstanden hatte, stellte ich fest, dass innerhalb von vier Jahren Dutzende Versionen der APP veröffentlicht wurden. Der ursprüngliche, von den Meistern und Senioren geschriebene Code wurde in vier Jahren von mehreren Wellen bis zur Unkenntlichkeit verändert. Es verstößt ernsthaft gegen die ursprüngliche Absicht des Designs, und es gibt keine Trennung zwischen den Versionen. Es gibt mehr als zehn IF-ELSEs und kann nicht mehr erweitert werden Es heißt, dass sich ein Umzug auf den gesamten Körper auswirken kann und nur ein paar Codezeilen angepasst werden können. Dies kann dazu führen, dass der gesamte Dienst aller Versionen nicht verfügbar ist. Wenn er weiterhin gewartet wird, kann er nur anderthalb Jahre oder sogar länger dauern Je länger jedoch die Zeit, desto chaotischer wird der Geschäftscode und desto passiver wird er sein.
2. Fundamentbau: Schnittstellenrekonstruktion
Wenn Sie sich nicht ändern, wird es nicht lange dauern! Wir können uns nur entscheiden und völlig neu aufbauen!
Die Geschäftsentwicklung und die Versionsiteration können jedoch nur von zwei Klassenkameraden übernommen werden, die die Entwicklung der alten API weiterhin unterstützen. Gleichzeitig begann ich, das Design der neuen Schnittstellenarchitektur zu untersuchen.
Aufgrund mangelnder Erfahrung und begrenzter Fähigkeiten in der APP-Entwicklung entdeckte ich eine Lücke in der Schnittstellenrekonstruktion. Ich blieb zwei Wochen lang auf und schrieb mehrere Frameworks, die ich tagsüber mit meinen Klassenkameraden besprach warf sie einen nach dem anderen um.
Ich hatte keine andere Wahl, als verschiedene Informationen nachzuschlagen, aus den Erfahrungen wichtiger Internetanwendungen zu lernen und gleichzeitig berühmte Lehrer zu besuchen [Danke an: @青哥, @雪大夫, @京京, @强哥 @太哥und Freunde auf der APP- und WAP-Seite], durch viel Lernen habe ich langsam einen Gesamtplan für die gesamte Idee zum Aufbau einer neuen Schnittstellenarchitektur entwickelt, und ich habe das Gefühl, das Licht der Welt erblickt zu haben.
Nachdem ich eine Woche lang Tag und Nacht gearbeitet habe, habe ich zunächst die gesamte Rahmenstruktur fertiggestellt. Ich arbeite ununterbrochen und traue mich nicht aufzuhören, also fangen wir an, meine Freunde zur Arbeit zu führen!
Obwohl wir eine allgemeine Vorstellung vom Gesamtdesign haben, steht die Rekonstruktion der Benutzeroberfläche ebenfalls vor großen Problemen und erfordert die volle Unterstützung von APP-, Produkt- und Statistikstudenten, um fortzufahren.
Die neue Schnittstelle unterscheidet sich hinsichtlich der Aufrufmethode und der Datenausgabestruktur vollständig von der alten Schnittstelle, was viele Änderungen am APP-Code erfordert [Danke an @Huihui @明明 für Ihre Unterstützung und Zusammenarbeit]
Natürlich steht auch die Statistik vor dem gleichen Problem, das heißt, alle ursprünglichen Statistikregeln müssen geändert werden. Gleichzeitig möchte ich mich auch bei [@婵女@Statistikabteilung @Produktklassenkameraden] bedanken. für die starke Zusammenarbeit. Ohne die Unterstützung beider Seiten, Produkte und Statistiken wäre der Fortschritt der Schnittstellenrekonstruktionsarbeiten unmöglich. Gleichzeitig möchte ich allen Führungskräften für ihre starke Unterstützung danken, um sicherzustellen, dass die Rekonstruktionsarbeiten wie geplant verlaufen.
Die neue Benutzeroberfläche ist hauptsächlich unter folgenden Aspekten konzipiert:
1. Sicherheit,
1>: Fügen Sie eine Signaturüberprüfung zu Schnittstellenanforderungen hinzu, richten Sie einen Anforderungsmechanismus für die Schnittstellenverschlüsselung ein, generieren Sie eine eindeutige ID für jede Anforderungsadresse und verwenden Sie eine bidirektionale Verschlüsselung auf dem Server und dem Client, um böswilliges Interface-Brushing wirksam zu vermeiden.
2>, Registrierungssystem für alle Geschäftsparameter, einheitliches Sicherheitsmanagement
2, Skalierbarkeit
Hohe Kohäsion und geringe Kopplung, erzwungene Versionstrennung, flache Entwicklung von APP-Versionen bei gleichzeitiger Verbesserung der Wiederverwendbarkeit des Codes, kleine Versionen folgen dem Vererbungssystem.
3. Ressourcenmanagement
Service-Registrierungssystem, einheitlicher Ein- und Ausgang, alle Schnittstellen müssen im System registriert werden, um eine nachhaltige Entwicklung sicherzustellen. Gewährleisten Sie die anschließende Überwachung und Planung des Downgrades.
4. Einheitliches Cache-Planungs- und Zuweisungssystem
3. Goldenes Elixier: Treten Sie in die Falle. . . . Und es ist eine große Falle
Die neue Benutzeroberfläche wurde wie geplant mit der Veröffentlichung von Version 5.0 eingeführt. Ich dachte, alles würde gut werden, aber wer weiß, vor mir wartete stillschweigend eine große Grube auf mich.
Die APP verfügt über eine PUSH-Funktion. Jedes Mal, wenn ein PUSH ausgegeben wird, wird eine große Anzahl von Benutzern sofort zum Besuch der APP aufgerufen.
Jedes Mal, wenn die neue Schnittstelle PUSH sendet, hängt der Server auf, was tragisch ist.
Fehlerausprägung:
1. php-fpm ist blockiert und der Gesamtstatus des Servers ist normal
2. Nginx ist nicht ausgefallen und der Dienst ist normal.
3. Starten Sie php-fpm neu. Der Dienst ist für eine Weile normal, stirbt jedoch nach einigen Sekunden wieder ab.
4. Die Benutzeroberfläche reagiert langsam oder es kommt zu einer Zeitüberschreitung und die App wird ohne Inhalt aktualisiert
Fehlerbehebung bei Vermutungen
An den folgenden Fragen habe ich zunächst gezweifelt,
1. MC hat ein Problem
2. MYSQL ist langsam
3. Großes Anfragevolumen
4. Bei einigen Anfragen handelt es sich um alte Schnittstellen des Proxys, wodurch die Anfragen verdoppelt werden
5. Netzwerkprobleme
6. Einige abhängige Schnittstellen sind langsam und belasten Dienste
Aufgrund fehlender Protokollaufzeichnungen konnte jedoch keine Grundlage gefunden werden.
Problemverfolgung:
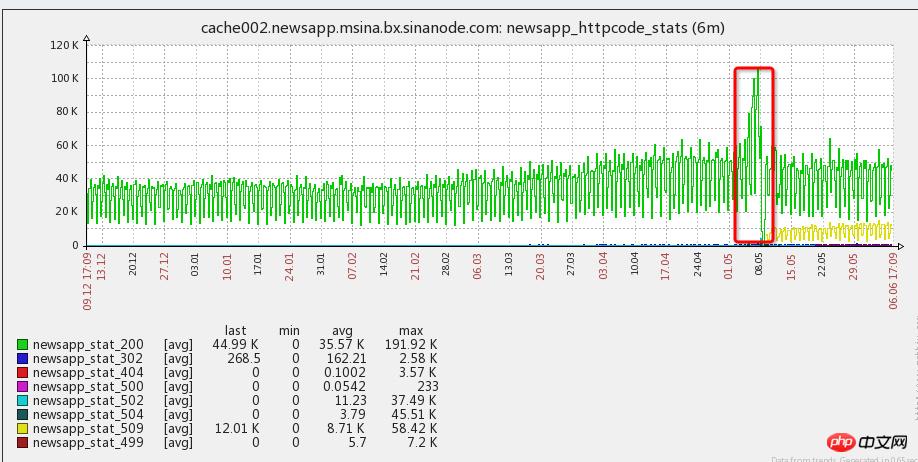
Der Serverdruck steigt sofort beim Senden einer push. PHP-FPM wird in kurzer Zeit blockiert und hängen bleiben. Solange eine Backend-Schnittstelle langsam ist, führt dies zu Warteschlangen und Wartezeiten wird abstürzen, bis PHP vollständig abstürzt.
1. Beim Drücken wird eine große Anzahl von APP-Benutzern zurückgerufen. Wenn der Client gleichzeitig geöffnet wird, beträgt die Anzahl das Drei- bis Fünffache der üblichen Zeiten (wie in der Abbildung dargestellt (Morgen- und Abendspitzen). wird überlagert))
2. Wenn der Client PUSH öffnet, werden viele Schnittstellenressourcen aufgerufen, und zu Beginn wird die neue API gestartet. Es gab keine ausreichende Kommunikation mit den Studenten auf der APP-Seite, was zu sofortigen Anfragen nach einer großen Anzahl von Schnittstellen führte, darunter viele Echtzeitinteressen, Werbung usw., die nicht zwischengespeichert werden konnten, und eine große Anzahl von Back-End-Schnittstellen, die streifig waren. und MYSQL und andere Ressourcen, was zu langen Wartezeiten führt.
3. Das Zeitlimit für die Schnittstellenanforderungs-Backend-Ressource ist zu lang eingestellt und langsame Schnittstellenanforderungen werden nicht rechtzeitig freigegeben, was dazu führt, dass eine große Anzahl von Schnittstellenanforderungen in der Warteschlange wartet
Der Benutzer Der Umfang wächst und der APP-Benutzerumfang ist derselbe wie zu Beginn des Jahres. Im Vergleich zur Verdoppelung der Anzahl lag der Schwerpunkt der Arbeit auf der Code-Rekonstruktion, aber Serverressourcen wurden ignoriert und es gab keine neuen Maschinen , was auch ein Grund für dieses Scheitern ist. [Hinweis: Hardware-Investitionen sind tatsächlich die kostengünstigsten Investitionen]
Dann, und dann ist es gestorben. . .
Problem gelöst:
1. Optimieren Sie den NGINX-Layer-Cache, indem Sie CACHE auf dem NGINX-Layer durchführen.
2 Bei der Verarbeitung [z. B. Statistiken] kehrt NGINX direkt zurück, ohne PHP zu verwenden, wodurch der Druck auf PHP-FPM verringert wird.
3 Reorganisieren Sie die angeforderten Back-End-Schnittstellenressourcen, priorisieren Sie sie entsprechend der geschäftlichen Bedeutung und kontrollieren Sie sie streng Time-out.
4. Fügen Sie neue Geräte hinzu und berechnen und konfigurieren Sie Serverressourcen basierend auf der Benutzerskala
5. Zeichnen Sie Ressourcenanrufprotokolle auf, überwachen Sie abhängige Ressourcen und finden Sie den Anbieter, der Probleme rechtzeitig löst, wenn ein Ressourcenproblem vorliegt
6. Passen Sie die MC-Cache-Struktur an, um die Cache-Auslastung zu verbessern
7. Kommunizieren Sie vollständig mit dem Kunden, um die Reihenfolge und Häufigkeit der Schnittstellenanforderungen durch die APP sorgfältig zu regeln und so die effektive Schnittstellennutzung zu verbessern.
Durch diese Reihe von Verbesserungsmaßnahmen ist der Effekt immer noch deutlich erkennbar Die Leistungsvorteile der neuen API im Vergleich zur alten API sind wie folgt :
Alt: Anfragen von weniger als 100 ms machen 55 % aus
 Antwortzeit der alten API
Antwortzeit der alten API
Neu: Mehr als 93 % Reaktionszeit beträgt weniger als 100 ms
 Neue API-Reaktionszeit
Neue API-Reaktionszeit
Zusammenfassung des Problems:
Die Hauptursachen sind hauptsächlich folgende: 1. Unzureichende Reaktion, 2. Mangel an wiederholter Kommunikation, 3. Unzureichende Robustheit, 4. PUSH-Eigenschaften
1>, unzureichende Reaktion
Die Anzahl der Benutzer hat sich seit Jahresbeginn mehr als verdoppelt, aber es gelang nicht, genügend Aufmerksamkeit zu erregen Battlefield und fügte nicht rechtzeitig Serverausrüstungsressourcen hinzu, was zu einer großen Grube führte.
2>, mangelnde Kommunikation
Ich hatte keine ausreichende Kommunikation mit meinen Klassenkameraden auf der APP-Seite und der Betriebs- und Wartungsabteilung und kümmerte mich nur darum, was zu meinen Füßen geschah. Stellen Sie sicher, dass Sie eine ausreichende Kommunikation mit den Terminal- und Betriebs- und Wartungsstudenten aufrechterhalten und diese in eine Einheit integrieren. Entsprechend den vorhandenen Ressourcenbedingungen [Hardware, Software, abhängige Ressourcen usw.] werden der Zeitpunkt und die Häufigkeit verschiedener Ressourcenanforderungen im Detail vereinbart und Anforderungen an Nicht-Hauptanwendungsschnittstellen entsprechend verzögert, um sicherzustellen, dass das Hauptgeschäft verfügbar ist und Nutzen Sie die Serviceressourcen voll aus.
Hinweis: Es ist besonders wichtig, eine gute Kommunikation mit Klassenkameraden aufrechtzuerhalten. Während der Entwicklung fordern Klassenkameraden Schnittstellen basierend auf den Geschäftslogikanforderungen der APP an. Wenn Sie zu viele Schnittstellen anfordern, ist dies gleichbedeutend damit, dass Ihre eigene APP eine große Anzahl von Schnittstellen startet Ddos-Angriffe auf Ihren eigenen Server, was sehr schrecklich ist. .
3>, unzureichende Robustheit
Eine übermäßige Abhängigkeit von vertrauenswürdigen Schnittstellen von Drittanbietern, unangemessene Timeout-Einstellungen für abhängige Schnittstellen, unzureichende Cache-Auslastung, keine Notfallsicherung und Probleme mit abhängigen Ressourcen können nur zum Tod führen.
Hinweis: Prinzip des Misstrauens, vertrauen Sie keinen abhängigen Ressourcen, seien Sie darauf vorbereitet, dass abhängige Schnittstellen jederzeit hängen bleiben, stellen Sie sicher, dass Sie Maßnahmen zur Notfallwiederherstellung haben, legen Sie ein striktes Timeout fest und geben Sie auf, wenn Sie sollten . Entwickeln Sie eine gute Strategie zur Serviceverschlechterung. [Referenz: 1. Geschäfts-Downgrade, Cache hinzufügen, um die Aktualisierungshäufigkeit zu reduzieren, 2. Hauptgeschäft sicherstellen, unnötiges Geschäft eliminieren, 3. Benutzer-Downgrade, einige Benutzer aufgeben und hochwertige Benutzer schützen]. Protokolle aufzeichnen Protokolle sind die Augen des Systems. Auch wenn die Protokollierung einen Teil der Systemleistung verbraucht, müssen Protokolle aufgezeichnet werden. Sobald ein Problem mit dem System auftritt, kann das Problem schnell lokalisiert und gelöst werden Protokolle.
4>, plötzlich großer Verkehr
PUSH und Dritte bringen sofort große Mengen an Datenverkehr mit sich, was für das System unerträglich ist und es an wirksamen Leistungsschaltern, Strombegrenzungs- und Herabstufungsmaßnahmen zum Selbstschutz mangelt.
Zusammenfassung: Auch ich habe durch diese Frage viel gelernt und ein tieferes Verständnis der gesamten Systemarchitektur gewonnen. Gleichzeitig wurde mir auch klar, dass manche Dinge nicht so einfach als selbstverständlich gelten. Man muss umfassende und detaillierte Vorbereitungen treffen, bevor man etwas unternimmt. Beim Refactoring geht es nicht nur um das Umschreiben des Codes. Es erfordert ein umfassendes Verständnis und Bewusstsein für die gesamten Upstream- und Downstream-Systemressourcen, und wenn dies nicht erfolgt, führt dies unweigerlich zu Fallstricken.
4. Werdende Seele: Sich Herausforderungen stellen
Ich freue mich darauf, freue mich darauf, der Verkehr kommt, die Olympischen Spiele stehen vor der Tür!
BOSS Bruder Tao sagte: Wenn die Olympischen Spiele nicht schiefgehen, werde ich die Schüler mit einer großen Mahlzeit verwöhnen! Wenn bei den Olympischen Spielen etwas schief geht, gönnen Sie Bruder Tao ein Festmahl! Es darf also keine Probleme mit dem Fest geben!
Wir haben uns auf Olympia vorbereitet und viele Optimierungsarbeiten durchgeführt, um die olympische Verkehrsspitze bestens überstehen zu können.
1. Alle abhängigen Ressourcen wurden sorgfältig sortiert und wichtige Geschäftsschnittstellen sorgfältig überwacht
2. Stellen Sie das Protokollberichtsmodul auf der APP-Seite bereit, um abnormale Protokolle in Echtzeit zur Überwachung zu melden
3. Aktualisieren und erweitern Sie den MC-Cluster und optimieren und verwalten Sie den Systemcache einheitlich
4. Einführung einer mehrstufigen Business-Leistungsschalter- und Downgrade-Strategie
Aber die Olympischen Spiele stehen vor der Tür und das System steht noch vor einer großen Bewährungsprobe. Um sicherzustellen, dass alle Indikatoren des Systems normal und problemlos funktionieren, haben wir dafür gesorgt, dass Ingenieure im Unternehmen im Einsatz sind 24 Stunden am Tag, die erste olympische Goldmedaille, erfüllte die Erwartungen und brachte sofortigen Erfolg. Bei mehr als dem Fünffachen des üblichen Datenverkehrs waren verschiedene Ressourcen knapp und der Server begann mit voller Kapazität zu arbeiten. In diesem Moment kamen unsere bisherigen Vorbereitungen ins Spiel. Der diensthabende Ingenieur achtete stets auf den großen Überwachungsbildschirm, passte die Systemparameter jederzeit entsprechend den Überwachungsdaten und dem Serverlaststatus an und erwärmte gleichzeitig verschiedene Daten vorgerückt und die erste olympische Goldmedaille erfolgreich gewonnen! Nach der ersten Goldmedaille stellte ich während der Olympischen Spiele fest, dass der Verkehr bei anderen Goldmedaillenveranstaltungen im Vergleich zur ersten Goldmedaille nicht allzu groß war. Ich dachte naiverweise, dass der gesamte olympische Verkehrshöchstwert sicher überwunden war. [Das erste Bild zur Überwachung von Goldanomalien sieht wie folgt aus]
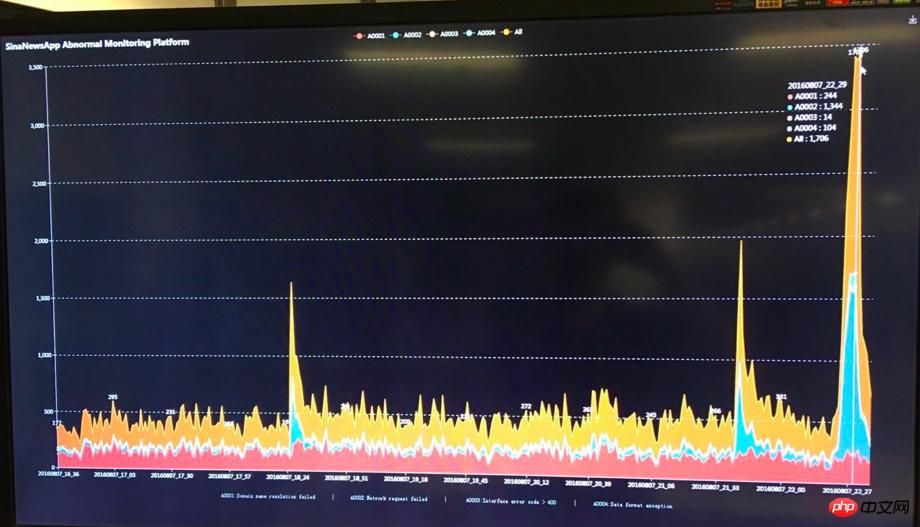
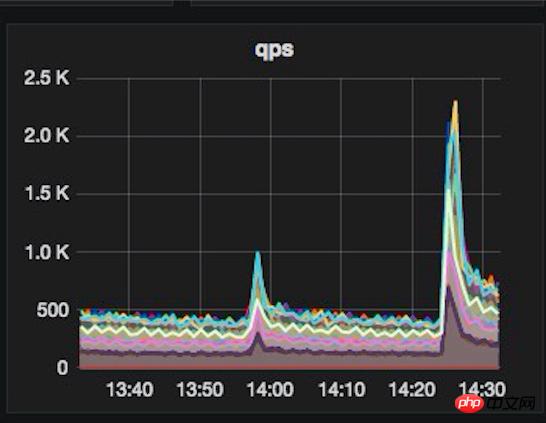
Aber [Gott arbeitet zum Guten. . 】Der Vorfall mit dem Baby kommt plötzlich und überschneidet sich mit den Olympischen Spielen! Der von PUSH am ersten Tag des Baby-Vorfalls verursachte Datenverkehr übertraf mit der starken Unterstützung vieler Bagua-Benutzer den größten Test unseres Lebens bei weitem. Der Server lief unter Volllast Der APP-Zugriff begann sofort nach PUSH zu reagieren. Im langsamen Fall beginnt auch die Fehlerrate bei der Anzeige der Echtzeitüberwachung zu steigen.
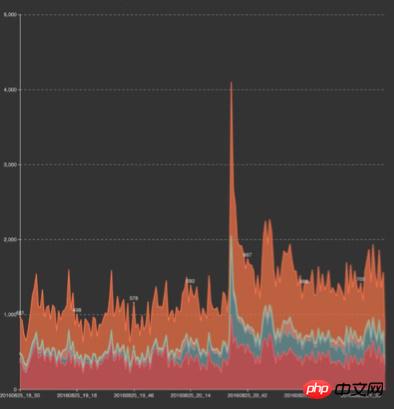 Baby-Event PUSH und Olympische Spiele überlagern den Verkehr
Baby-Event PUSH und Olympische Spiele überlagern den Verkehr
Wir haben sofort einen Notfallplan aktiviert, um das System vor Überlastung zu schützen, und Dienste in der Reihenfolge ihrer Wichtigkeit heruntergestuft [im Allgemeinen einschließlich: Reduzierung der Aktualisierungshäufigkeit, Verlängerung der Cache-Zeit und Deaktivierung], um die Gesamtsystemverfügbarkeit vor Beeinträchtigungen zu schützen und sicherzustellen, dass die Das System kann die Verkehrsspitze problemlos überwinden. Nachdem das Downgrade manuell aktiviert wurde, beginnt das System, schnell eine große Menge an Ressourcen freizugeben, die Systemlast beginnt stetig zu sinken und die benutzerseitige Reaktionszeit kehrt auf das normale Niveau zurück. Nachdem der PUSH vorüber ist [der Höhepunkt dauert normalerweise etwa 3 Minuten], brechen Sie das Downgrade manuell ab.
Obwohl der Baby-Vorfall während der Olympischen Spiele plötzlich ausbrach, haben wir ihn reibungslos überstanden, es gab keine Probleme mit dem gesamten Service und auch die gesamten Geschäftsdaten der APP haben sich durch diese beiden Vorfälle erheblich verbessert.
BOSS lud die Schüler auch zu einem Festmahl und einer fröhlichen Zeit ein!
Zusammenfassung: 1. Das Überwachungssystem muss detaillierter sein und die Ressourcenüberwachung muss hinzugefügt werden, da durch eine Post-Mortem-Analyse festgestellt wird, dass einige der festgestellten Probleme nicht durch den Verkehr verursacht werden, sondern möglicherweise auf die Abhängigkeit zurückzuführen sind Ressourcenprobleme, die zu einer Überlastung des Systems führen und die Auswirkungen verstärken. 2. Verbessern Sie das Alarmsystem. Aufgrund des unvorhersehbaren Auftretens von Notfällen ist es unmöglich, dass jemand 24 Stunden am Tag im Dienst ist. 3. Das Service-Management-System des automatischen Downgrade-Mechanismus wartet darauf, eingerichtet zu werden. Wenn es auf plötzlichen Datenverkehr oder plötzliche Anomalien in abhängigen Ressourcen stößt, wird es automatisch unbeaufsichtigt heruntergestuft.
5. Out of Body: Geschäftsoptimierung und Anpassung der Serverarchitektur
Das sich schnell entwickelnde Geschäft hat auch höhere Anforderungen an verschiedene Indikatoren unseres Systems gestellt. Der erste ist die serverseitige Reaktionszeit.
Die Reaktionsgeschwindigkeit der beiden Kernfunktionsmodule der APP, des Feed-Streams und des Textes, hat einen großen Einfluss auf die gesamte Benutzererfahrung. Gemäß den Anforderungen der Führung haben wir zunächst ein frühes Ziel: Die durchschnittliche Reaktionszeit Der Feed-Stream beträgt 100 ms. Zu diesem Zeitpunkt beträgt die Gesamtantwortzeit des Feeds etwa 500-700 ms, was ein langer Weg ist!
Das Feed-Streaming-Geschäft ist komplex und basiert auf vielen Datenressourcen, wie z. B. Echtzeitwerbung, Personalisierung, Kommentaren, Bildübertragung, Fokusbildern, Bereitstellung fester Positionen usw. Einige Ressourcen können für Echtzeitberechnungsdaten nicht zwischengespeichert werden Wir können uns nicht auf Caching verlassen und können es nur auf andere Weise lösen.
Zuerst haben wir mit dem Betriebs- und Wartungsteam zusammengearbeitet, um die Serversoftware-Systemumgebung insgesamt zu aktualisieren, Nginx auf Tengine aktualisiert und dann PHP aktualisiert. Der Upgrade-Effekt war ziemlich offensichtlich und die Gesamtreaktionszeit wurde um etwa 20 % verkürzt. Obwohl die Leistung verbessert wurde, ist sie noch weit vom Ziel entfernt. Während die Optimierung fortschreitet, führen wir eine Protokollanalyse für die gesamte Geschäftsverbindung des Feeds durch, um die Bereiche herauszufinden, die die meiste Leistung verbrauchen, und sie nacheinander zu besiegen.
Die ursprüngliche Serverstruktur ist wie folgt:
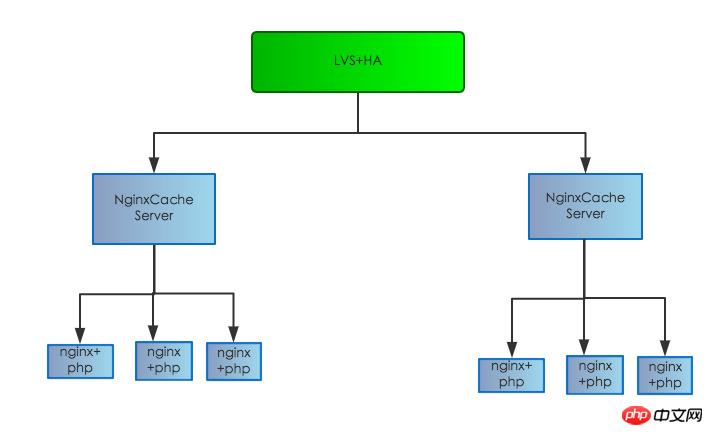
Es ist unterteilt in: Lastausgleichsschicht, Proxy-Schicht und Web-Schicht. Der Client-Zugriff wird zunächst über den Nginx-Proxy-Schicht-Proxy weitergeleitet Wenn sich die Ebene und die Webmaschine nicht auf demselben Gerät oder sogar an verschiedenen Orten im selben Computerraum befinden, kann es zu erheblichen Leistungseinbußen kommen Der Nginx-Protokolldatensatz der Proxy-Ebene ist zehn oder sogar Hunderte von Millisekunden länger als die Antwortzeit des Protokolldatensatzes der Web-Ebene, und es liegt ein einzelner Fehler in der ursprünglichen Cache-Ebene vor. Nachdem das Problem gefunden wurde, haben wir die Serverstruktur wie folgt angepasst: offline Die ursprüngliche Cache-Schicht wird auf den Web-Front-End-Computer verschoben, um Einzelpunkt-Engpässe zu reduzieren und das Risiko von Einzelpunkt-Ausfällen zu eliminieren, die die Gesamtverfügbarkeit des Dienstes beeinträchtigen.
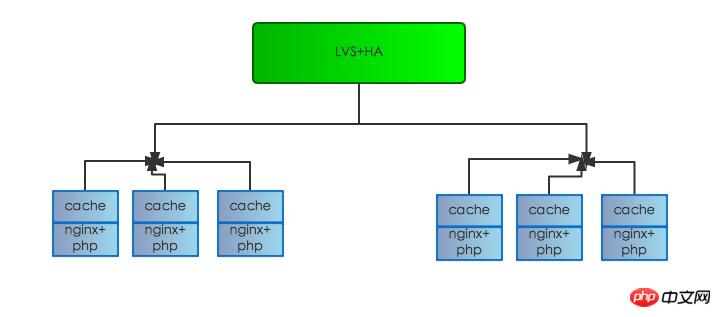
Nach Abschluss der Serverstrukturanpassung wurde auch die Feed-Reaktionszeit stark verkürzt und die Leistung deutlich verbessert und liegt bei etwa 200-350 ms. Dem gesetzten Ziel näher kommen, das gesetzte Ziel aber immer noch nicht erreichen.
Eines Tages entdeckten unsere Ingenieure versehentlich ein Problem beim Debuggen des Codes. Durch eine große Anzahl von Tests haben wir überprüft, dass die mit PHP gelieferte Standard-CURL-Bibliothek keine Millisekunden unterstützt In der offiziellen PHP-Dokumentation haben wir festgestellt, dass die alte Version der PHP-Libcurl-Bibliothek dieses Problem aufweist [später wurde festgestellt, dass die meisten Business-PHP-Versionsumgebungen im Unternehmen dieses Problem haben] Dies bedeutet, dass wir die große Anzahl abhängiger Schnittstellen-Timeouts genau steuern können Das System wurde nicht wirksam, was auch zu einer Verzögerung der Systemleistung führte. Die Lösung dieses Problems wird mit Sicherheit eine große Verbesserung der Gesamtleistung mit sich bringen. Wir werden sofort mit dem Online-Graustufen-Verifizierungstest beginnen Nach mehreren Tagen des Online-Tests wurden keine weiteren Probleme festgestellt und die Leistung hat sich wirklich stark verbessert. Daher haben wir den Umfang schrittweise erweitert, bis alle Server online waren. Die Daten zeigten, dass der Server-Feed nach dem Upgrade der libcurl-Versionsbibliothek Die Reaktionszeit erreichte ohne weitere Optimierung direkt 100-100, was sehr offensichtlich ist.
Die Serverstrukturschicht und die Softwaresystemumgebungsschicht haben ihr Möglichstes getan, aber sie haben noch nicht die festgelegte Anforderung von 100 ms für die durchschnittliche Feed-Antwortzeit erreicht. Zu diesem Zeitpunkt kann nur der Online-Feed gestartet werden Die Flussanforderung basiert auf Ressourcen, die nacheinander ausgeführt wurden. Die Überlastung einer Ressource führt dazu, dass nachfolgende Anforderungen in die Warteschlange gestellt werden, was zu einer Verlängerung der Gesamtantwortzeit führt. Wir begannen zu versuchen, PHP CURL auf gleichzeitige Multithread-Anforderungen umzustellen, seriell auf parallel umzustellen und mehrere abhängige Ressourcenschnittstellen gleichzeitig anzufordern, ohne zu warten. Durch die technische Forschung unserer Freunde haben wir die CURL-Klassenbibliothek neu geschrieben, um sie bereitzustellen Um Probleme zu vermeiden, haben wir einen langen Zeitraum mit umfangreichen Graustufentests durchgeführt und diese in der Online-Produktionsumgebung veröffentlicht. Gleichzeitig wurde die Reaktionszeit des Server-Feed-Streams belohnt weniger als 100 ms. Gleichzeitig wird die durchschnittliche Reaktionszeit der Schnittstelle auf innerhalb von 15 ms gesteuert.
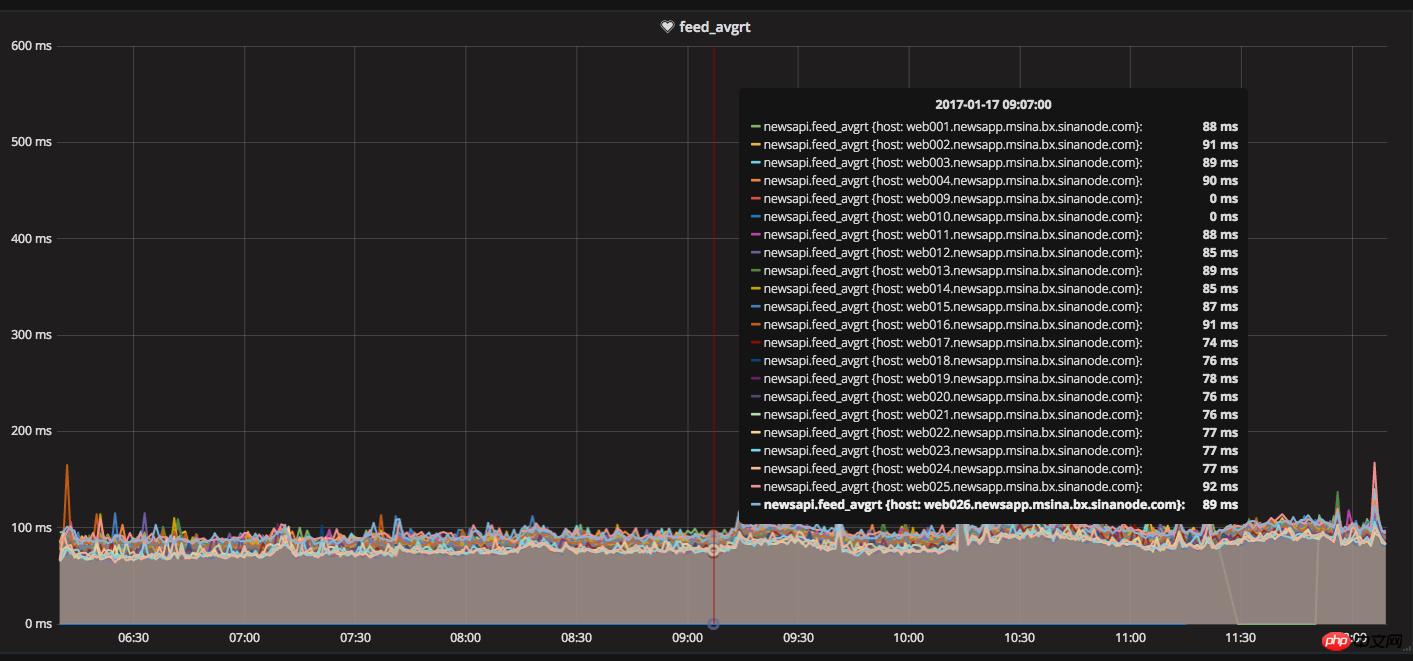
Feedflow-Reaktionszeit
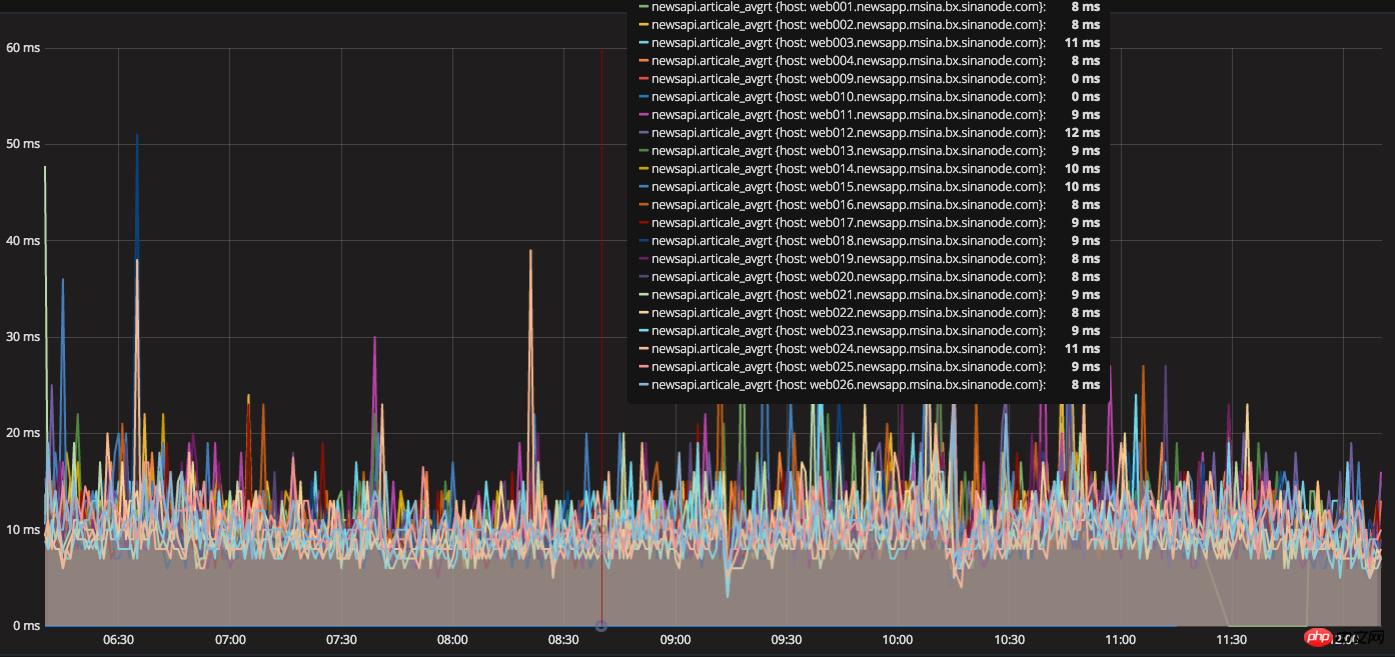 Durchschnittliche Textantwortzeit
Durchschnittliche Textantwortzeit
Anschließend führten wir eine verteilte Bereitstellung von Servern in jedem Computerraum durch, verteilten VIP-Netzwerkzugangsknoten neu, optimierten Netzwerkanrufressourcen und vermieden die negativen Auswirkungen auf die Benutzererfahrung, die durch betreiberübergreifenden Nord-Süd-Zugriff verursacht werden können.
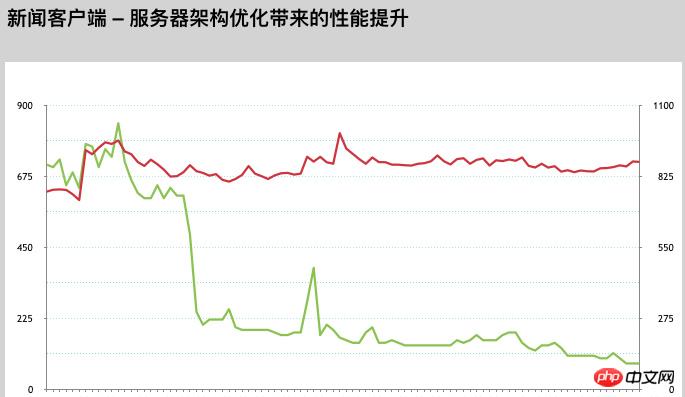
Durch die oben genannte Vielzahl an Optimierungsanpassungen wurde auch die Tragfähigkeit unseres Gesamtsystems deutlich verbessert.
Der aktuelle Spitzen-QPS liegt bei 134.000 und die höchste tägliche Anzahl an HIT-Anfragen erreicht etwa 800 Millionen. Das Volumen ist bereits sehr beeindruckend.
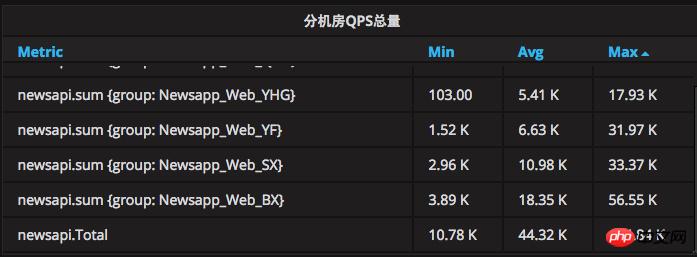
Die QPS-Tragfähigkeit einer einzelnen Maschine wurde ebenfalls erheblich verbessert. Das ursprüngliche 500-800-QPS-System mit einer einzelnen Maschine war voll ausgelastet, aber jetzt ist das 2,5K-System mit einer einzelnen Maschine immer noch absolut stabil und bewegungslos.
Dank der kontinuierlichen Bemühungen der Teammitglieder und auch der Betriebs- und Wartungsstudenten für ihre großartige Unterstützung konnten die Leistung und die Lastbeständigkeit des Nachrichten-APP-Schnittstellensystems erheblich verbessert werden.
6. Die Trübsal überwinden: Service-Governance-Plattform
Nur durch strategisches Handeln können wir tausend Meilen gewinnen.
News-APP-Schnittstellen sind derzeit auf Hunderte von Schnittstellen und Ressourcen von Drittanbietern angewiesen. Sobald ein Problem mit einer oder mehreren Schnittstellen und Ressourcen auftritt, kann dies leicht die Systemverfügbarkeit beeinträchtigen.
Basierend auf dieser Situation haben wir dieses System entworfen und entwickelt. Die Hauptsystemmodule sind wie folgt:
Service-Selbstschutz, Service-Verschlechterung, Fehleranalyse und Call-Chain-Überwachung, Überwachung und Alarmierung. Selbstgebautes Offline-Rechenzentrum, das sich auf das Ressourcenlebenserkennungssystem und den Schnittstellenzugriffsplanungsschalter stützt. Das Offline-Rechenzentrum sammelt wichtige Geschäftsdaten in Echtzeit. Das Lebenserkennungssystem erkennt den Ressourcenzustand und die Verfügbarkeit in Echtzeit und den Schnittstellenzugriffsplanungsschalter Wenn das System ein Problem mit einer Ressource erkennt, führt es über den Schnittstellenzugriffskontrollschalter automatisch eine Herabstufung und Reduzierung der Zugriffshäufigkeit durch und verlängert automatisch die Datencachezeit. Das System zur Lebensdauererkennung erkennt kontinuierlich Sobald die Ressource vollständig nicht verfügbar ist, schließt der Steuerschalter den Schnittstellenanforderungszugriff vollständig, um eine automatische Dienstverschlechterung zu bewirken, und ermöglicht dem lokalen Rechenzentrum, Daten für Benutzer bereitzustellen. Nachdem der Lebenstest erkannt hat, dass die Ressource verfügbar ist, setzen Sie den Anruf fort. Dieses System hat eine starke Abhängigkeit von Ressourcen [wie CMS, Kommentarsystemen, Werbung usw.] schon oft vermieden. Fehler Die Auswirkungen auf die Verfügbarkeit von Nachrichten-Client-Diensten Wenn die abhängigen Ressourcen ausfallen, lautet die Geschäftsreaktion: Der Kunde ist sich dessen im Grunde nicht bewusst. Gleichzeitig haben wir ein vollständiges Ausnahmeüberwachungs-, Fehleranalyse- und Anrufkettenüberwachungssystem eingerichtet, um sicherzustellen, dass Probleme so schnell wie möglich vorhergesagt, entdeckt und gelöst werden können [ausführlich in Kapitel 7 Server-Hochverfügbarkeit].
Gleichzeitig entwickelt sich das Kundengeschäft rasant weiter und jedes Funktionsmodul wird schnell aktualisiert und iteriert. Um der schnellen Iteration ohne ernsthafte Codeprobleme gerecht zu werden, haben wir auch den Code-Graustufen- und Release-Prozess erweitert. Wenn eine neue Funktion gestartet wird, wird sie zunächst einer Graustufenüberprüfung unterzogen. Wenn ein Problem mit der neuen Funktion auftritt, wird sie gleichzeitig mit voller Kapazität gestartet Es kann jederzeit auf die alte Version umgestellt werden, um den normalen Betrieb sicherzustellen.
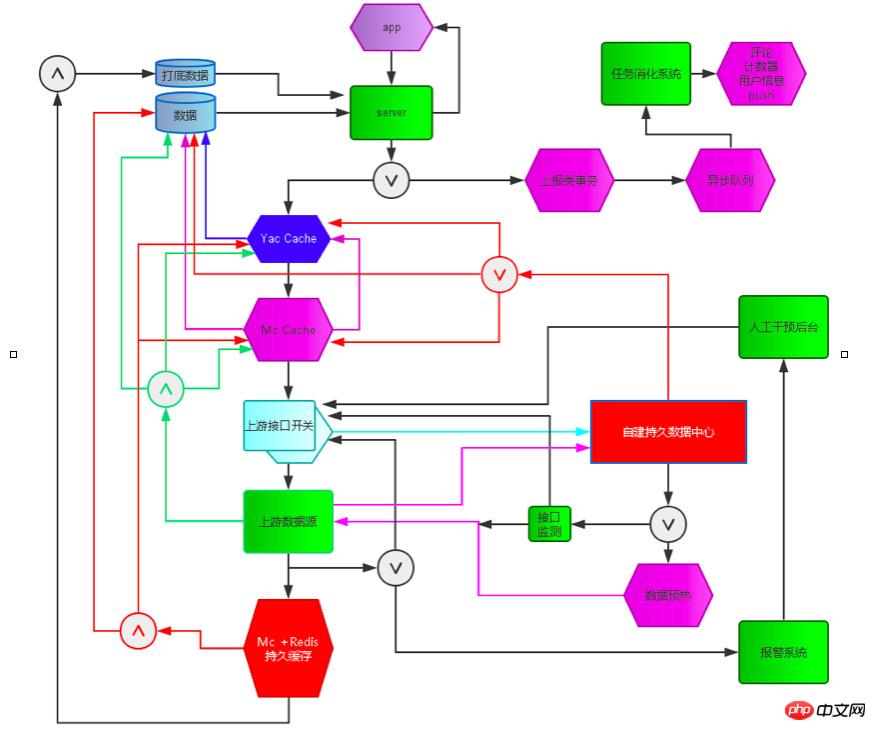 Implementierung der Service-Governance-Plattform-Technologie
Implementierung der Service-Governance-Plattform-Technologie
Nachdem die Service-Governance-Plattform erstellt wurde, sieht unsere System-Service-Architektur ungefähr wie folgt aus:
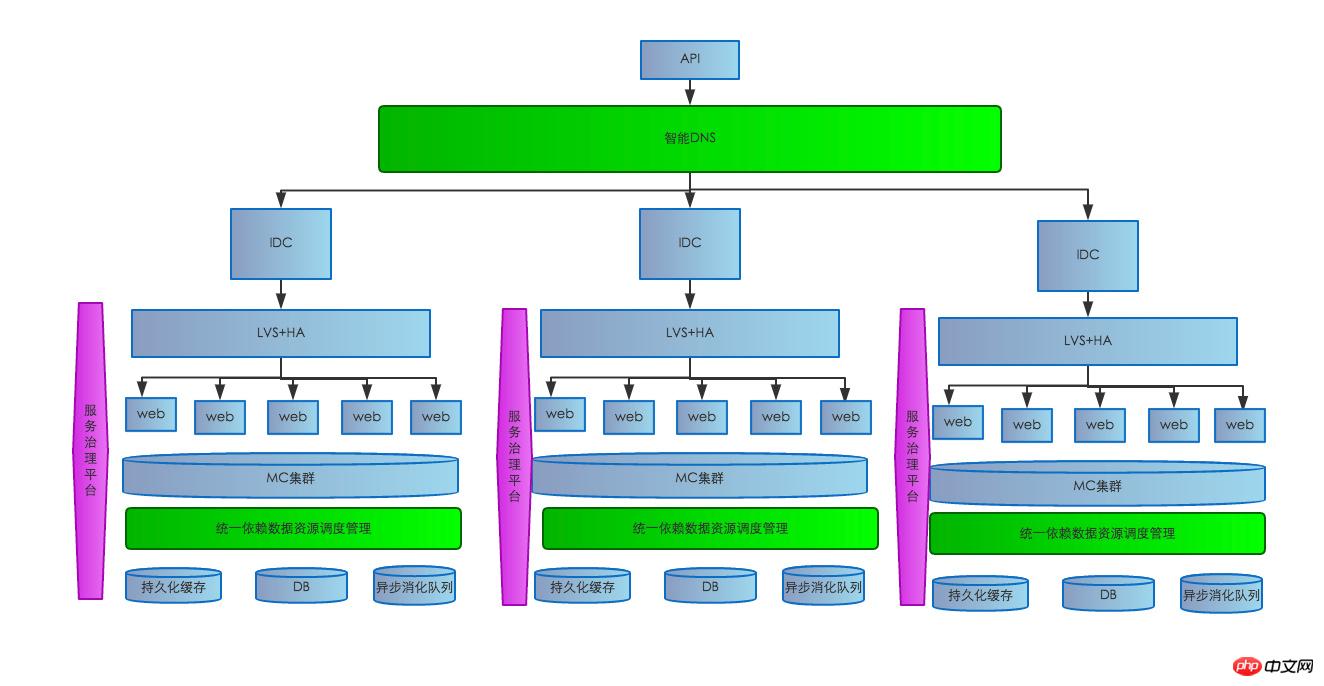
7. Mahayana: hohe Verfügbarkeit des Servers
Hochverfügbarkeit ist derzeit eines der besorgniserregendsten Probleme bei WEB-Dienstsystemen mit hoher Parallelität und hohem Datenverkehr. Hochverfügbarkeitsdesign ist ein systematisches Projekt, das viele Aspekte umfasst wie (Netzwerk, Serverhardware, Webdienste, Cache, Datenbank, Abhängigkeit von Upstream-Ressourcen, Protokolle, Überwachung, Alarme, Selbstschutz, Notfallwiederherstellung, schnelle Verarbeitung und Wiederherstellung). .
Definition von Hochverfügbarkeit:
Die Definitionsformel der Systemverfügbarkeit (Verfügbarkeit) lautet: Verfügbarkeit = MTBF / ( MTBF + MTTR ) × 100 %
MTBF (Mean Time Between Failure), also die mittlere Zeit zwischen Ausfällen, ist ein Indikator, der die Zuverlässigkeit des gesamten Systems beschreibt. Bei einem großen Websystem bezieht sich MTBF auf die durchschnittliche Zeit, die die Dienste des gesamten Systems benötigen, um kontinuierlich ohne Unterbrechung oder Fehler ausgeführt zu werden.
MTTR (Mean Time to Repair), also die durchschnittliche Systemwiederherstellungszeit, ist ein Indikator, der die Fehlertoleranzfähigkeit des gesamten Systems beschreibt.
Bei einem großen Websystem bezieht sich MTTR auf die durchschnittliche Zeit, die das System benötigt, um vom Fehlerzustand in den Normalzustand zurückzukehren, wenn eine Komponente im System ausfällt.
Aus der Formel ist ersichtlich, dass eine Erhöhung der MTBF oder eine Verringerung der MTTR die Systemverfügbarkeit verbessern kann.
Es stellt sich also die Frage, wie die Systemverfügbarkeit durch diese beiden Indikatoren verbessert werden kann.
Aus der obigen Definition können wir erkennen, dass ein wichtiger Faktor für die Hochverfügbarkeit: MTBF die Systemzuverlässigkeit [mittlere Zeit zwischen Ausfällen] ist.
Dann listen wir auf, welche Probleme sich auf MTBF auswirken werden: 1. Server-Hardware, 2. Netzwerk, 3. Datenbank, 4. Cache, 5. Abhängige Ressourcen, 6. Codefehler, 7. Plötzlich großer Datenverkehr, hohe Parallelität Diese Probleme werden gelöst, Ausfälle können vermieden und die MTBF verbessert werden.
Basierend auf diesen Fragen: Wie macht der News-Client das derzeit?
Der erste Server-Hardwarefehler: Wenn ein Server-Hardwarefehler dazu führt, dass der Dienst auf diesem Server nicht verfügbar ist, ist die Struktur wie unten dargestellt. Das aktuelle System ist LVS+HA mit mehreren Es gibt ein Life-Detection-System auf dem Server, LVS+HA. Wenn eine Anomalie erkannt wird, wird diese rechtzeitig aus dem Lastausgleich entfernt, um zu verhindern, dass Benutzer auf den problematischen Server zugreifen und einen Fehler verursachen.
Das zweite interne Netzwerkproblem: Wenn ein großer interner Netzwerkfehler auftritt, treten eine Reihe von Problemen auf, z. B. Fehler beim Lesen abhängiger Ressourcen, Fehler beim Zugriff auf die Datenbank usw Fehler beim Lesen und Schreiben des Cache-Clusters usw., der Umfang der Auswirkungen ist relativ groß und die Folgen sind schwerwiegend. Dann werden wir dieses Mal weitere Artikel schreiben. Im Allgemeinen treten Netzwerkprobleme hauptsächlich auf, wenn der Zugriff zwischen Computerräumen blockiert oder blockiert ist. Es kommt äußerst selten vor, dass das Netzwerk im selben Computerraum getrennt wird. Da einige abhängige Schnittstellen auf verschiedene Computerräume verteilt sind, wirken sich computerraumübergreifende Netzwerkprobleme hauptsächlich auf die langsame Reaktion oder Zeitüberschreitung der abhängigen Schnittstellen aus. Für dieses Problem wenden wir eine mehrstufige Caching-Strategie an Wenn die Schnittstelle abnormal ist, wird zuerst der lokalisierte Echtzeit-Cache verwendet. Wenn der Echtzeit-Cache des Clusters durchdrungen ist, greifen Sie sofort auf den Echtzeit-Cache des Clusters zu. Greifen Sie auf den persistenten Verteidigungscache des lokalen Computerraums zu. Wenn der persistente Cache nicht erreicht wird, wird die Sicherungsdatenquelle an den Benutzer zurückgegeben. Gleichzeitig wird die vorgewärmte Sicherungsdatenquelle nur zwischengespeichert dauerhaft, so dass Benutzer nichts davon bemerken und größere Ausfälle vermieden werden. Um das Problem der durch Netzwerkprobleme verursachten Datenbankverzögerungen zu lösen, verwenden wir hauptsächlich asynchrones Schreiben in die Warteschlange, um den Speicher zu vergrößern und zu verhindern, dass das Datenbankschreiben überlastet wird und die Systemstabilität beeinträchtigt.
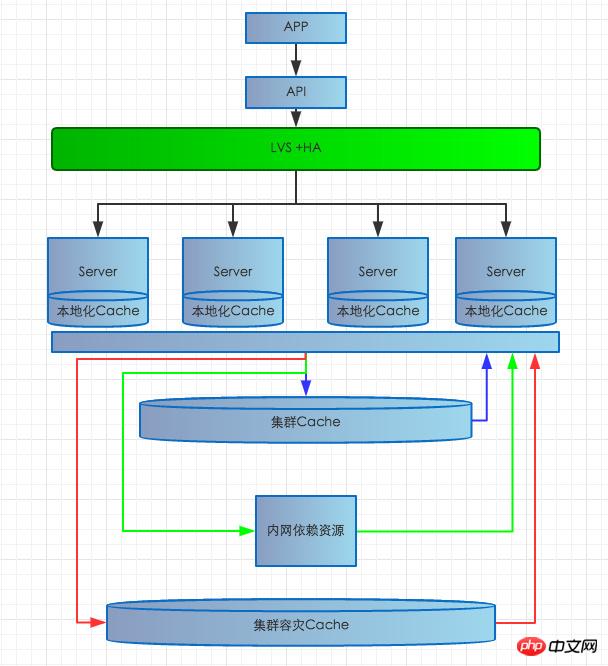
Der sechste Codefehler : In der Vergangenheit gab es Fälle, in denen Codierungsfehler zu blutigen Online-Ausfällen führten, und viele der Probleme wurden durch Fehler auf niedriger Ebene verursacht, daher haben wir uns auch auf diesen Bereich konzentriert.
Zunächst müssen wir den Code-Entwicklungs- und Release-Prozess standardisieren. Mit dem Wachstum des Unternehmens steigen auch die Anforderungen an die Systemstabilität und -zuverlässigkeit Ursprünglicher sozialer Zustand der Brandrodung und der Alleinarbeit. Alle Abläufe müssen standardisiert und prozessorientiert sein.
Wir haben Folgendes verbessert: Entwicklungsumgebung, Testumgebung, Simulationsumgebung, Online-Umgebung und Online-Prozess. Nachdem der Ingenieur den Selbsttest in der Entwicklungsumgebung abgeschlossen hat, erwähnt er die Testumgebung und die Testabteilung führt den Test durch. Nach dem Bestehen des Tests geht er in die Simulationsumgebung und führt den Simulationstest durch Das Online-System muss vom Administrator genehmigt werden. Nach Abschluss der Online-Regression wird die Online-Regressionsüberprüfung durchgeführt Schlägt die Überprüfung fehl, kann das Online-System mit einem Klick auf die Umgebung vor dem Start zurückgesetzt werden.
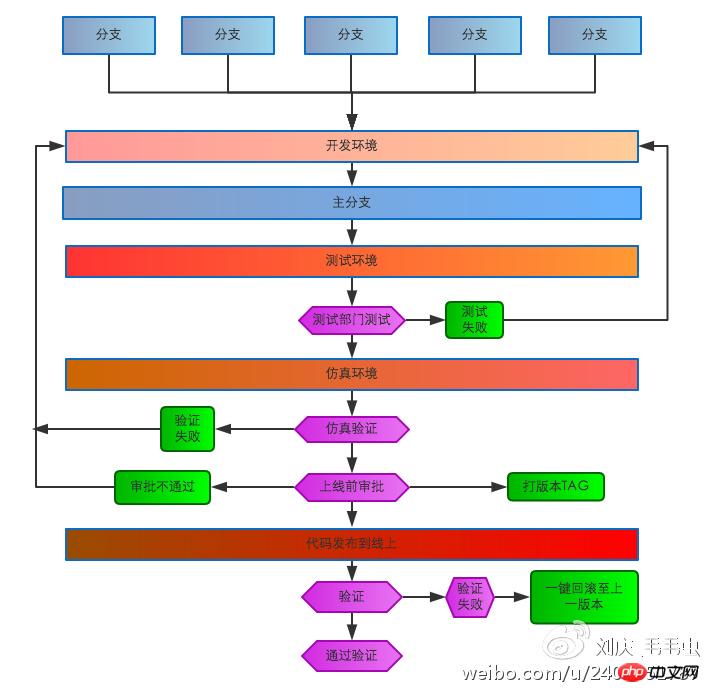 Code-Entwicklungs- und Veröffentlichungsprozess
Code-Entwicklungs- und Veröffentlichungsprozess
Dann zu Artikel 7 : Wie gehen wir mit plötzlich großem Datenverkehr und hoher Parallelität um?
Plötzlich großer Datenverkehr definieren wir im Allgemeinen als Hotspots und Notfälle, die in kurzer Zeit eine große Anzahl von Zugriffsanfragen mit sich bringen, die den erwarteten Lastbereich der Systemsoftware und -hardware bei weitem überschreiten. Wenn sie nicht behandelt werden, kann dies Auswirkungen auf den Gesamtdienst haben. Diese Situation dauert nur kurze Zeit. Wenn es zu spät ist, eine neue Online-Maschine vorübergehend hinzuzufügen, ist dies bedeutungslos, nachdem die Maschine online ist und die Verkehrsspitze vorüber ist. Wenn zu irgendeinem Zeitpunkt eine große Anzahl von Backup-Maschinen online vorbereitet werden, sind diese Maschinen 99 % der Zeit im Leerlauf, was eine Menge finanzieller und materieller Ressourcen verschwendet.
In einer solchen Situation benötigen wir ein vollständiges Verkehrsplanungssystem sowie Leistungsschalter und Strombegrenzungsmaßnahmen. Wenn plötzlich großer Datenverkehr aus bestimmten Bereichen kommt oder sich auf einen oder mehrere IDC-Computerräume konzentriert, können Sie einen Teil des Datenverkehrs vom Computerraum mit höherer Auslastung auf den Computerraum mit ungenutztem Datenverkehr aufteilen, um den Druck gemeinsam zu verteilen. Wenn die Verkehrssegmentierung jedoch nicht ausreicht, um das Problem zu lösen, oder die Verkehrslast aller Computerräume relativ hoch ist, können wir den gesamten Systemdienst nur durch Leistungsschalter und Strombegrenzung schützen. Sortieren Sie zunächst nach der Priorität Business-Modul und fahren Sie dann entsprechend dem Business-Downgrade fort. Wenn das Business-Downgrade das Problem immer noch nicht lösen kann, werden wir damit beginnen, Dienste mit niedriger Priorität nacheinander zu deaktivieren, um wichtige Funktionsmodule beizubehalten und weiterhin externe Dienste bereitzustellen In extremen Fällen, wenn das Business-Downgrade die Verkehrsspitze nicht überstehen kann, werden wir die derzeitigen einschränkenden Schutzmaßnahmen vorübergehend aufgeben, um die Verfügbarkeit der meisten hochwertigen Benutzer aufrechtzuerhalten.
Ein weiterer wichtiger Indikator für Hochverfügbarkeit ist die durchschnittliche Wiederherstellungszeit des MTTR-Systems, also wie lange es dauert, bis der Dienst nach einem Ausfall wiederhergestellt ist.
Die wichtigsten Punkte zur Lösung dieses Problems sind: 1. Den Fehler finden, 2. Die Fehlerursache lokalisieren, 3. Den Fehler beheben
Diese drei Punkte sind gleichermaßen wichtig: Wir müssen Fehler rechtzeitig erkennen. Das Schlimmste ist, dass wir das Problem lange Zeit nicht gefunden haben Benutzerverluste sind das Schlimmste. Wie erkennt man also Fehler rechtzeitig?
Das Überwachungssystem ist das wichtigste Glied im gesamten System und sogar im gesamten Produktlebenszyklus. Es liefert rechtzeitige Warnungen, um Fehler im Vorfeld zu erkennen, und stellt im Nachhinein detaillierte Daten zur Verfolgung und Lokalisierung von Problemen bereit.
Zunächst müssen wir über einen vollständigen Überwachungsmechanismus verfügen, aber Überwachung reicht nicht aus. Wir müssen auch rechtzeitig Alarme auslösen und das zuständige Personal rechtzeitig benachrichtigen. In diesem Zusammenhang haben wir mit Unterstützung der Betriebs- und Wartungsabteilung ein unterstützendes Überwachungs- und Alarmsystem aufgebaut.
Im Allgemeinen besteht ein vollständiges Überwachungssystem hauptsächlich aus diesen fünf Aspekten: 1. Systemressourcen, 2. Server, 3. Dienststatus, 4. Anwendungsausnahmen, 5. Anwendungsleistung, 6. Ausnahmeverfolgungssystem
1. Systemressourcenüberwachung
Überwachen Sie verschiedene Netzwerkparameter und serverbezogene Ressourcen (CPU, Speicher, Festplatte, Netzwerk, Zugriffsanfragen usw.), um den sicheren Betrieb des Serversystems sicherzustellen, und stellen Sie einen Ausnahmebenachrichtigungsmechanismus bereit, damit Systemadministratoren verschiedene Probleme schnell lokalisieren/lösen können bestehende Probleme.
2. Serverüberwachung
Die Serverüberwachung dient hauptsächlich dazu, zu überwachen, ob die Anforderungsantworten jedes Servers, Netzwerkknotens, Gateways und anderer Netzwerkgeräte normal sind. Durch den geplanten Dienst wird jedes Netzwerkknotengerät regelmäßig angepingt, um zu bestätigen, ob jedes Netzwerkgerät normal ist. Wenn ein Netzwerkgerät abnormal ist, wird eine Nachrichtenerinnerung ausgegeben.
3. Serviceüberwachung
Die Dienstüberwachung bezieht sich darauf, ob die Dienste verschiedener Webdienste und anderer Plattformsysteme normal ausgeführt werden. Mithilfe geplanter Dienste können Sie in regelmäßigen Abständen verwandte Dienste anfordern, um sicherzustellen, dass die Dienste der Plattform normal ausgeführt werden.
4. Überwachung von Anwendungsausnahmen
Dazu gehören hauptsächlich abnormale Zeitüberschreitungsprotokolle, Datenformatfehler usw.
5. Überwachung der Anwendungsleistung
Überwachen Sie, ob die Reaktionszeitindikatoren des Hauptgeschäfts normal sind, zeigen Sie den Leistungskurventrend des Hauptgeschäfts an und erkennen und prognostizieren Sie mögliche Probleme rechtzeitig.
6. Ausnahmeverfolgungssystem
Das Ausnahmeverfolgungssystem überwacht hauptsächlich die Ressourcen, auf die das gesamte System vor- und nachgelagert ist, indem es den Gesundheitszustand abhängiger Ressourcen überwacht, z. B. Änderungen in der Antwortzeit, Änderungen in der Timeout-Rate usw., und kann so frühzeitige Entscheidungen treffen und damit umgehen mögliche Risiken im gesamten System. Es kann auch aufgetretene Fehler schnell lokalisieren, um festzustellen, ob sie durch ein abhängiges Ressourcenproblem verursacht werden, und so den Fehler schnell beheben.
Die wichtigsten Überwachungssysteme, die wir derzeit online nutzen, sind folgende:
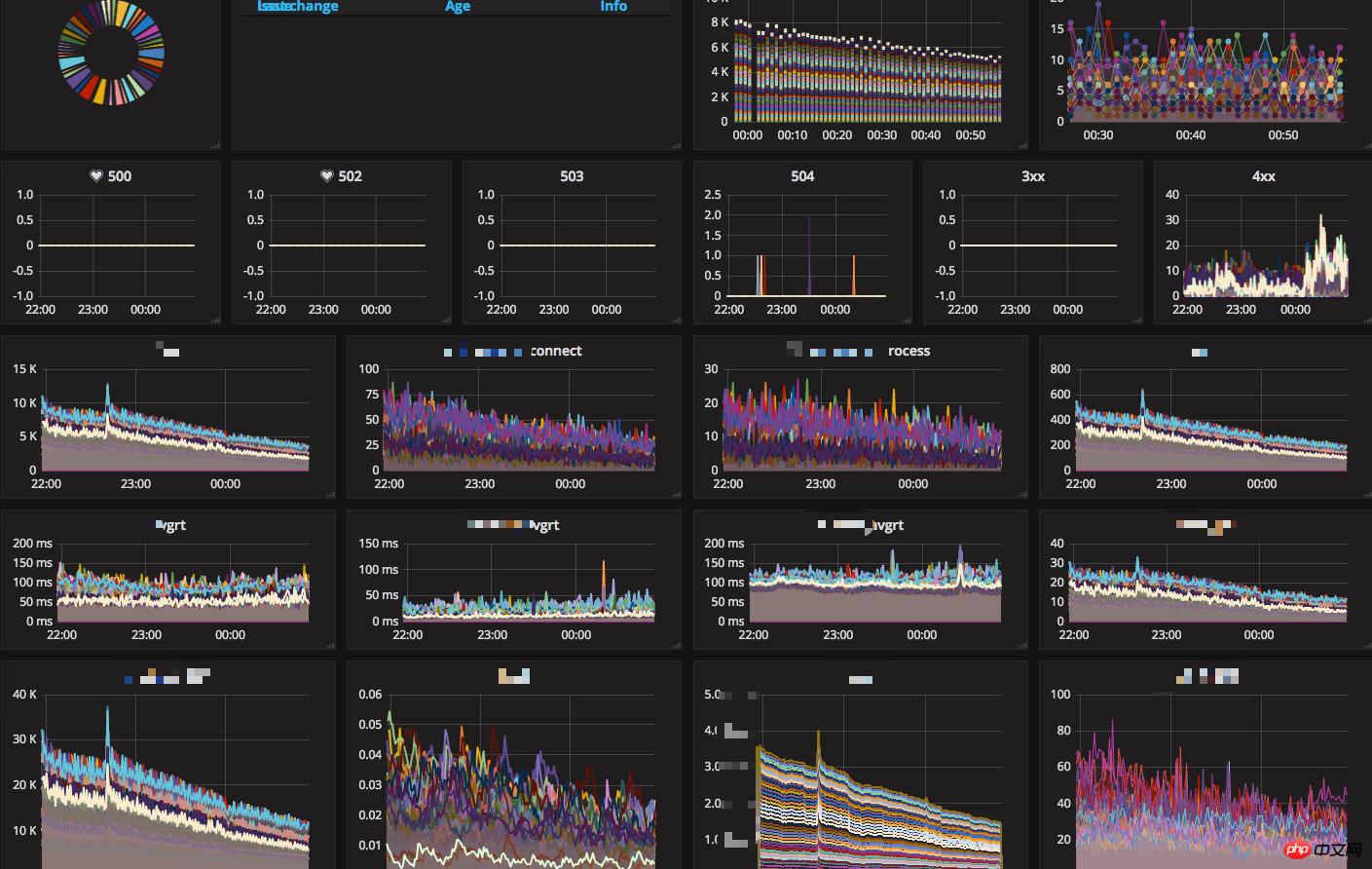 Dashboard
Dashboard
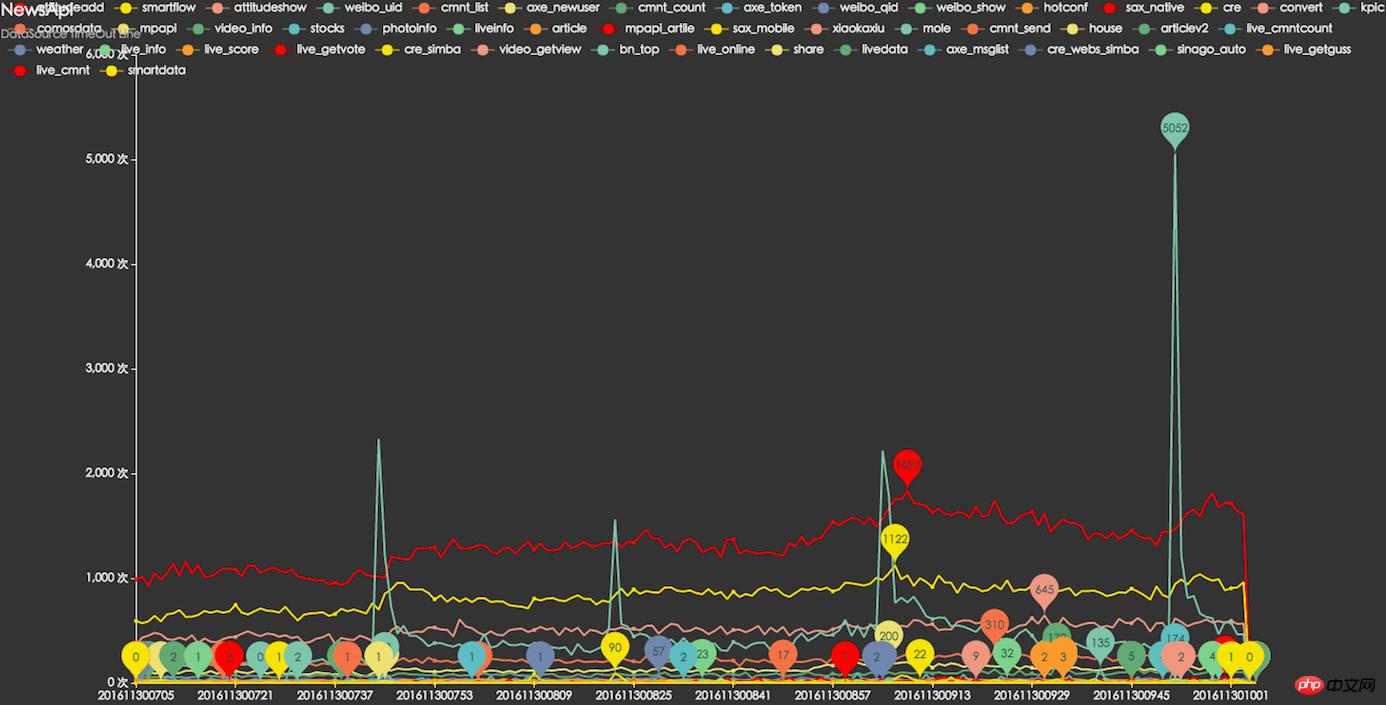 Abhängige Ressourcen-Timeout-Überwachung
Abhängige Ressourcen-Timeout-Überwachung
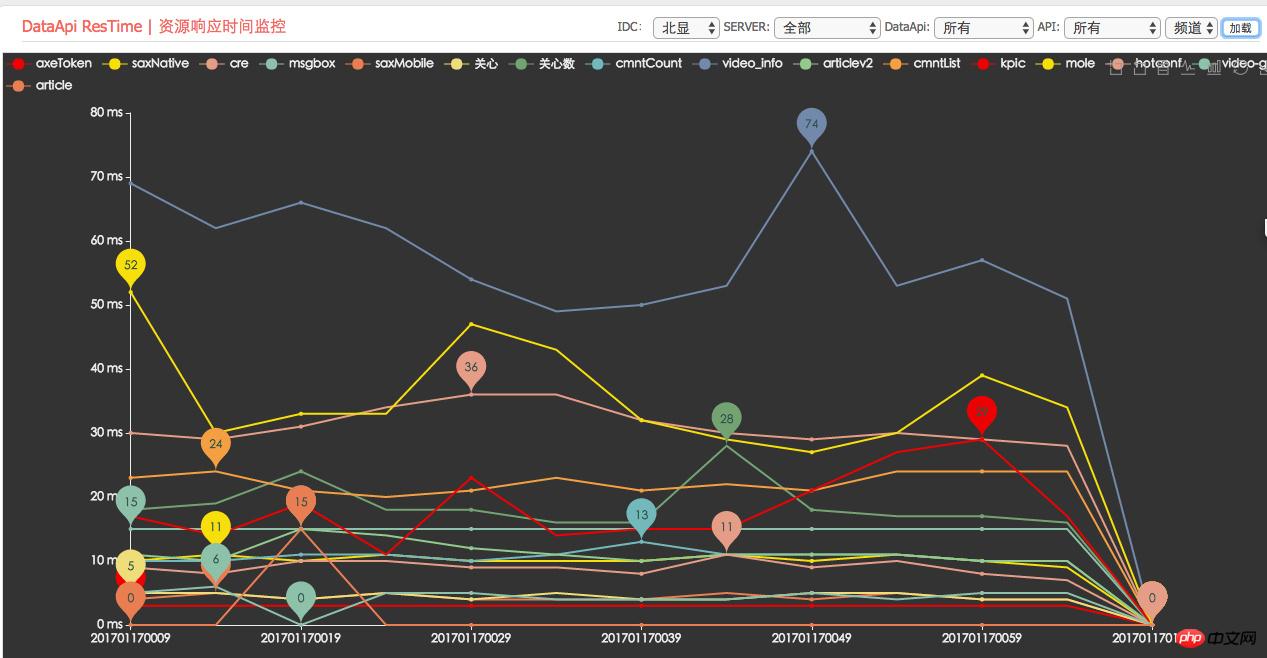 Überwachung der durchschnittlichen Antwortzeit abhängiger Ressourcen
Überwachung der durchschnittlichen Antwortzeit abhängiger Ressourcen
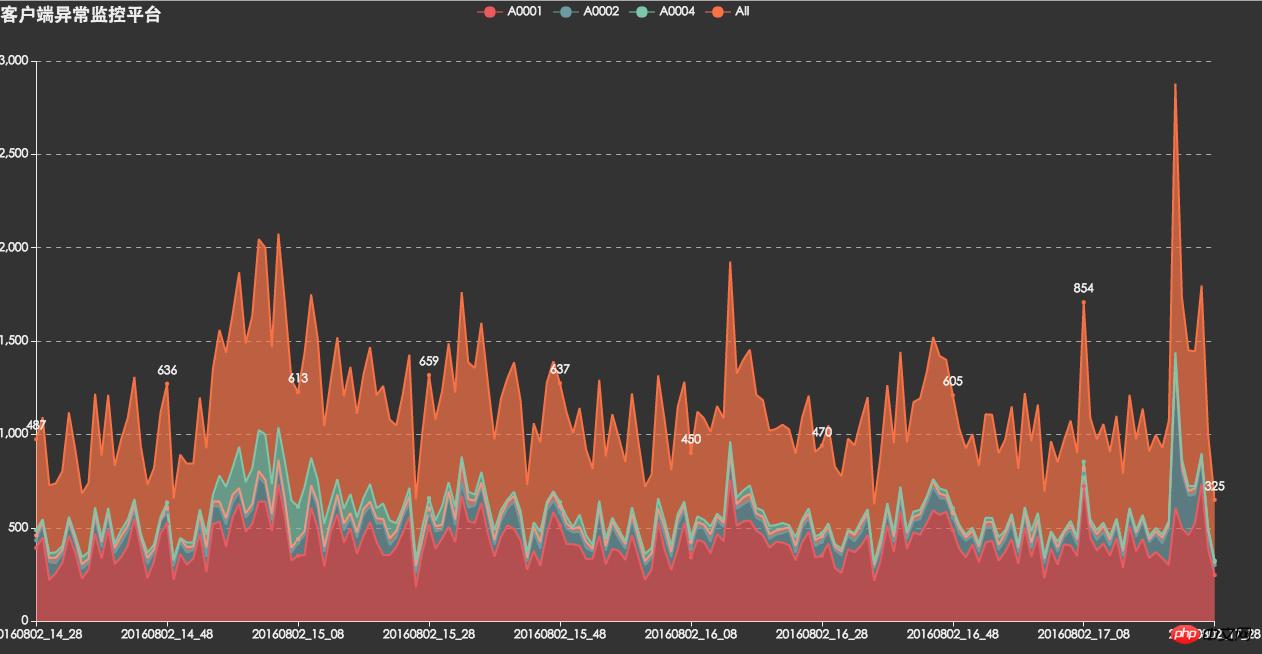 API-Fehlerüberwachung
API-Fehlerüberwachung
Hinweis: [Zitat, Studie] Es gibt zwei Hauptpunkte, um die Qualität eines Überwachungssystems zu beurteilen: 1. sorgfältig, 2. auf einen Blick klar. Diese beiden scheinen im Widerspruch zueinander zu stehen, da es viele, viele Überwachungsprojekte im Detail geben muss, sie dürfen nicht auf den ersten Blick klar sein, aber das ist nicht der Fall. Auf einen Blick klar zu sein, dient vor allem dazu, Probleme rechtzeitig zu erkennen, denn es ist unmöglich, so viel Zeit und Energie zu haben, um ständig auf Hunderte von Überwachungsdiagrammen zu starren. Dann benötigen Sie ein vollständiges Dashboard, um zusammenzufassen, ob verschiedene Indikatoren normal sind, und um abnormale Indikatoren aufzulisten, um Probleme auf einen Blick zu identifizieren. Akribie bedeutet vor allem, sich auf die Fehlerbehebung vorzubereiten, nachdem ein Problem aufgetreten ist. Sie können überprüfen, ob verschiedene Überwachungsdatenpunkte normal sind, um das Problem schnell zu lokalisieren.
8. Höhenflug: hohe Verfügbarkeit für den Kunden
[Wichtiges Ziel im Jahr 2017, hohe Verfügbarkeit für den Kunden]
In letzter Zeit gab es in den Internetmedien viele Artikel über HTTPS. Einer der Gründe dafür ist, dass das Endergebnis des bösen Verhaltens der Betreiber immer geringer wird und vor ein paar Tagen Werbung eingefügt wird. Mehrere Internetunternehmen gaben gemeinsam eine gemeinsame Erklärung zum Widerstand gegen illegale Aktivitäten wie Traffic-Hijacking ab und verurteilten einige Betreiber. Andererseits wird es auch durch die ATS-Richtlinie von Apple stark gefördert, die alle dazu zwingt, in allen Apps HTTPS-Kommunikation zu verwenden. Die Verwendung von HTTPS bietet viele Vorteile: Schutz von Benutzerdaten vor Lecks, Verhinderung der Manipulation von Daten durch Zwischenhändler und Authentifizierung von Unternehmensinformationen.
Obwohl die HTTPS-Technologie verwendet wird, blockieren einige bösartige Betreiber HTTPS und nutzen die DNS-Verschmutzungstechnologie, um Domänennamen auf ihre eigenen Server zu verweisen, um DNS-Hijacking durchzuführen.
Wenn dieses Problem nicht gelöst wird, kann auch HTTPS das Problem nicht grundsätzlich lösen und viele Benutzer werden immer noch Zugriffsprobleme haben. Dies kann zumindest zu Misstrauen gegenüber dem Produkt führen, im schlimmsten Fall jedoch direkt dazu führen, dass Benutzer das Produkt nicht verwenden können, was zu Benutzerverlusten führt.
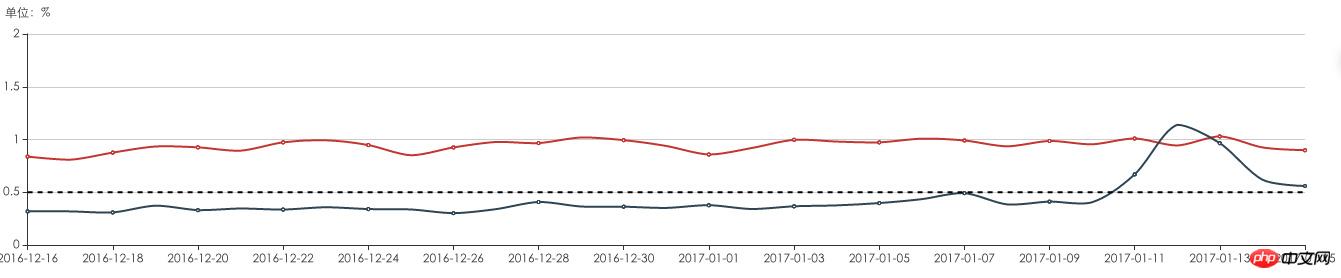
Wie schwerwiegend ist die Anomalie bei der Auflösung von Domainnamen für Internetunternehmen wie Gouchang nach Angaben Dritter? Das verteilte System zur Überwachung der Domainnamenauflösung von Gouchang erkennt jeden Tag kontinuierlich alle wichtigen LocalDNS im ganzen Land. Die Zahl der täglichen Auflösungsausnahmen für Gouchangs Domainnamen im ganzen Land hat 800.000 überschritten. Dies führte zu enormen Verlusten für das Unternehmen.
Die Betreiber werden alles tun, um mit Werbung Geld zu verdienen und bei der Abrechnung zwischen den Netzwerken Geld zu sparen. Eine häufige Hijacking-Methode besteht darin, gefälschte DNS-Domänennamen über ISPs bereitzustellen.
„Tatsächlich stehen auch wir vor dem gleichen ernsten Problem“
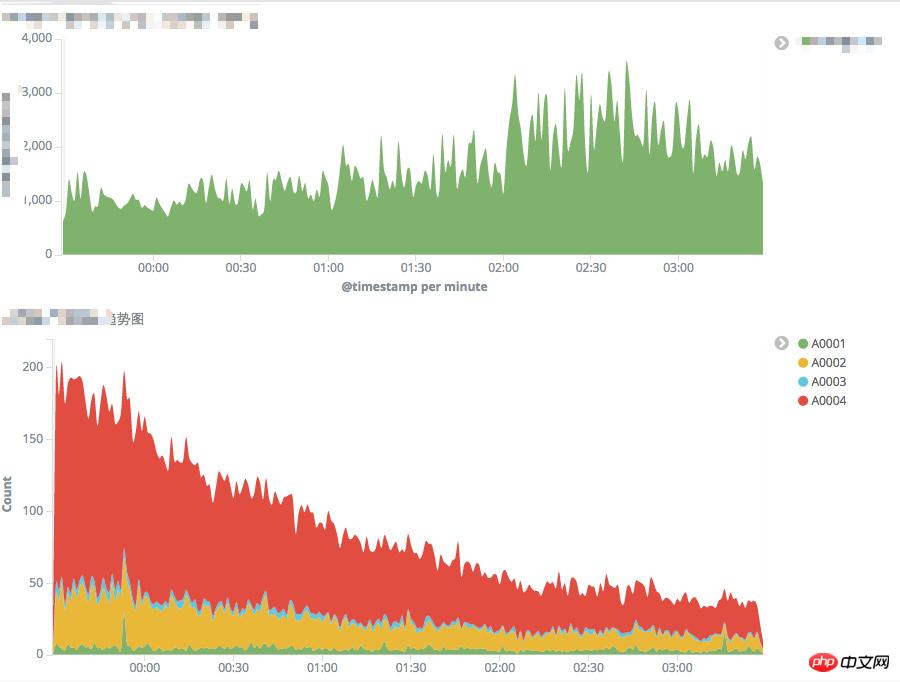
Durch Protokollüberwachung und -analyse in der Nachrichten-App wurde festgestellt, dass 1–2 % der Benutzer DNS-Auflösungsanomalien und Probleme beim Schnittstellenzugriff haben.
DNS-Ausnahme und Unfähigkeit, auf die Schnittstelle zuzugreifen
Es verursachte unsichtbar viele Benutzerverluste, insbesondere in der Zeit der schnellen Geschäftsentwicklung, und verursachte großen Schaden für das Geschäftserlebnis.
Gibt es also eine technische Lösung, die die Grundursache von Anomalien bei der Auflösung von Domainnamen, Problemen beim Benutzerzugriff über Netzwerke und DNS-Hijacking beheben kann?
Die Branche hat eine Lösung, um diese Art von Szenario zu lösen, nämlich HTTP DNS.
Was ist HttpDNS?
HttpDNS sendet eine Domänennamen-Auflösungsanforderung basierend auf dem HTTP-Protokoll an den DNS-Server und ersetzt die herkömmliche Methode, eine Auflösungsanforderung an das LocalDNS des Betreibers basierend auf dem DNS-Protokoll zu initiieren. Dadurch können Domänennamen-Hijacking und netzwerkübergreifende Zugriffsprobleme vermieden werden LocalDNS und löst das Problem der abnormalen Auflösung von Domänennamen bei mobilen Internetdiensten.
Welche Probleme löst HttpDNS?
HttpDNS löst hauptsächlich drei Arten von Problemen: Behebung von DNS-Auflösungsanomalien und der Entführung von LocalDNS-Domänennamen im mobilen Internet, die durchschnittliche Antwortzeit erhöht sich und die Fehlerquote bei Benutzerverbindungen bleibt bestehen hoch
1. DNS-Auflösungsausnahme und LocalDNS-Hijacking:
Die aktuelle Situation des mobilen DNS: Der LocalDNS-Export des Betreibers führt NAT basierend auf der autorisierenden DNS-Ziel-IP-Adresse durch oder leitet die Auflösungsanforderung an andere DNS-Server weiter, was dazu führt, dass das autorisierende DNS die LocalDNS-IP des Betreibers nicht korrekt identifizieren kann, was zu einem Domänennamen führt Auflösungsfehler und Verkehr über das Netzwerk.
Folgen des Domainnamen-Hijackings: Unzugänglichkeit der Website (keine Verbindung zum Server möglich), Popup-Werbung, Zugriff auf Phishing-Websites usw.
Die Folgen von domänen-, provinz-, betreiber- und länderübergreifenden Parsing-Ergebnissen: Der Website-Zugriff ist langsam oder sogar nicht möglich.
Da HttpDNS http direkt anfordert, die Server-A-Eintragsadresse über IP zu erhalten, besteht keine Notwendigkeit, den lokalen Betreiber nach dem Domänenauflösungsprozess zu fragen, sodass das Hijacking-Problem grundsätzlich vermieden wird.
2. Die durchschnittliche Zugriffsantwortzeit erhöht sich: Da direkt auf die IP zugegriffen wird, entfällt ein Domänenauflösungsprozess und der schnellste Knoten wird nach der Sortierung durch intelligente Algorithmen für den Zugriff gefunden.
3. Reduzierte Benutzerverbindungsfehlerrate: Reduzieren Sie die Rangfolge von Servern mit übermäßigen Ausfallraten in der Vergangenheit durch Algorithmen, verbessern Sie die Serverrangfolge durch kürzlich aufgerufene Daten und verbessern Sie Server durch historische Zugriffserfolge Datensätze. Sortieren. Wenn ein Zugriffsfehler auf ip(a) auftritt, werden beim nächsten Mal die sortierten Datensätze von ip(b) oder ip(c) zurückgegeben. (LocalDNS gibt wahrscheinlich Datensätze
innerhalb eines TTL (oder mehrerer TTL) zurück.) HTTPS kann Betreiber weitestgehend davon abhalten, den Datenverkehr zu kapern, einschließlich der Manipulation der Inhaltssicherheit.
HTTP-DNS kann das Problem des Client-DNS lösen und sicherstellen, dass Benutzeranfragen direkt an den Server mit der schnellsten Antwort weitergeleitet werden.
Das Prinzip der HttpDNS-Implementierung
Das Prinzip von HTTP DNS ist sehr einfach. Es wandelt DNS, ein Protokoll, das leicht gekapert werden kann, in HTTP-Protokollanfragen um
DomainIP-Zuordnung. Nachdem der Client die richtige IP erhalten hat, stellt er das HTTP-Protokoll selbst zusammen, um zu verhindern, dass der ISP die Daten manipuliert.
Der Client greift direkt auf die HTTPDNS-Schnittstelle zu, um die optimale IP des Domänennamens zu erhalten. (Aufgrund von Überlegungen zur Notfallwiederherstellung ist die Methode der Verwendung des LocalDNS des Betreibers zum Auflösen von Domänennamen als Alternative vorbehalten.)
Nachdem der Client die Geschäfts-IP erhalten hat, sendet er eine Geschäftsprotokollanforderung direkt an diese IP. Am Beispiel der HTTP-Anfrage können Sie eine Standard-HTTP-Anfrage an die von HTTPDNS zurückgegebene IP senden, indem Sie das Hostfeld im Header angeben.
Wenn Sie eine hohe Verfügbarkeit auf der Clientseite erreichen möchten, müssen Sie dieses Problem zunächst lösen. Wir haben mit unseren APP-Entwicklungsstudenten und Betriebs- und Wartungsstudenten mit den Vorbereitungen begonnen und streben danach, HTTPDNS so schnell wie möglich einzuführen, um eine hohe Verfügbarkeit für den APP-Client zu erreichen und eine zuverlässige Garantie für die schnelle Entwicklung des Geschäfts zu bieten!
Nach einem Jahr harter Arbeit hat sich das gesamte APP-Back-End-System im Grunde genommen von der barbarischen Ära zum aktuellen Stand der Perfektion entwickelt. Ich habe auch durch ein wenig Erkundung viel Wissen gelernt, und ich denke, ich habe es auch erreicht Großes Wachstum, aber gleichzeitig stehen wir vor vielen, vielen Problemen: Mit der rasanten Geschäftsentwicklung werden die Anforderungen an Back-End-Dienste immer höher. Es gibt auch in Zukunft noch viele Probleme, die gelöst werden müssen. Wir werden uns auch an höhere Standards halten und uns auf die Größe von Hunderten Millionen Benutzern vorbereiten.
www.php.cn)!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)