
Heim >Datenbank >MySQL-Tutorial >Einige Gedanken und Entwürfe zur Migration von Daten von MySQL nach HBase
Einige Gedanken und Entwürfe zur Migration von Daten von MySQL nach HBase

- 黄舟Original
- 2017-03-02 16:45:521486Durchsuche
1. Gründe für die Migration
Aufgrund der Geschäftsentwicklung hat die Verwendung von MySQL zum Erstellen von Indizes und zur Suche dazu geführt, dass der Datenfluss in der Datenbank stecken bleibt Wenn die Tabelle gelöscht wird, wird der Druck zu groß, was dazu führt, dass es lange dauert, und das aktuelle Datenvolumen hat im Grunde 100 Millionen Ebenen erreicht. Wenn Sie möchten, dass MySQL bessere Dienste bietet, muss der nächste Schritt darin bestehen, sub in Betracht zu ziehen -Datenbanken und Tabellen; auf dieser Grundlage sollten Sie in diesem Fall die Verwendung von hbase für die Datenspeicherung in Betracht ziehen, da die Datenmenge, die hbase verarbeiten kann, viel größer ist als die von MySQL und die Erweiterung von Spalten ebenfalls sehr praktisch ist
2 . Einige Unterschiede zwischen relationalen Datenbanken und Nosql
(1) Unterschiede in den Speichermethoden
In relationalen Datenbanken wie MySQL, SQLServer, Oracle werden Daten nach Zeilen gespeichert, wie im Folgenden gezeigt Abbildung:
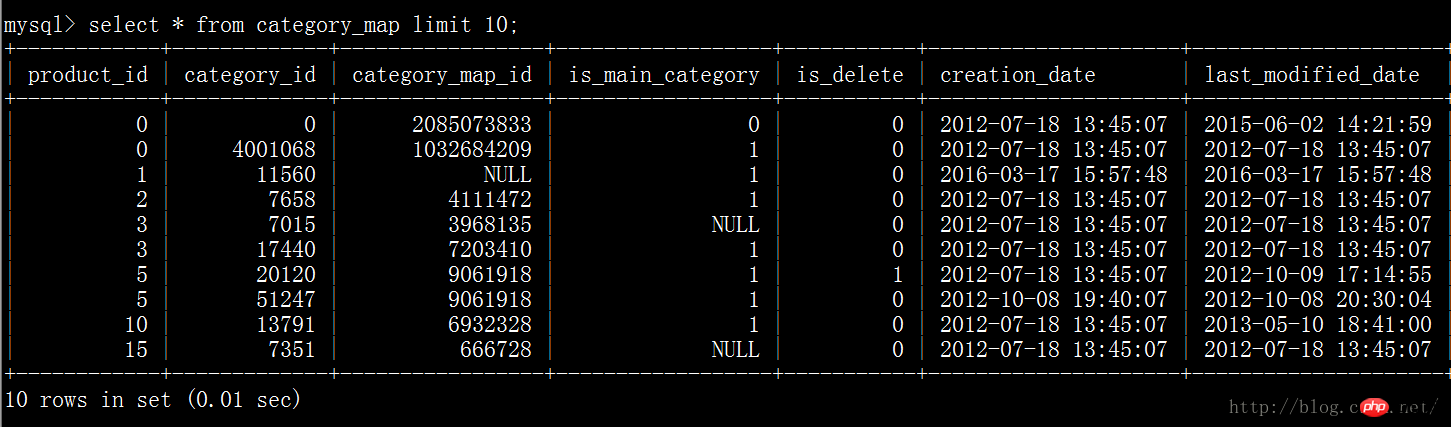
Aber in hbase werden alle Daten basierend auf Spalten gespeichert, wie unten gezeigt:

Das logische Modell von hbase lautet wie folgt:
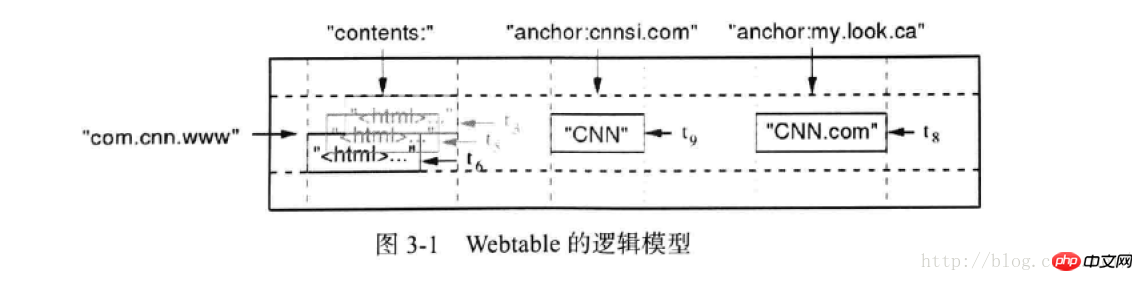
Darunter: com.cnn.ww entspricht rowkey, was dem Konzept von entspricht MySQL-Primärschlüssel
Inhalt, Anker: Diese beiden entsprechen dem Konzept der Spaltenfamilie. In Bezug auf die physische Speicherung werden Daten derselben Spaltenfamilie in derselben Datei gespeichert
cnnsi.com , mylook.ca: entspricht den Spalten unter der Spaltenfamilie, die dynamisch in hbase hinzugefügt werden können
Die entsprechenden Rasterdaten stellen die Einheitsdaten dar, die dem Zeilenschlüssel entsprechen, vgl.: der spezifische Wert unter der Spalte
Darunter stellt tn: den Zeitstempel dar.
haben eine Speicherstruktur wie folgt:
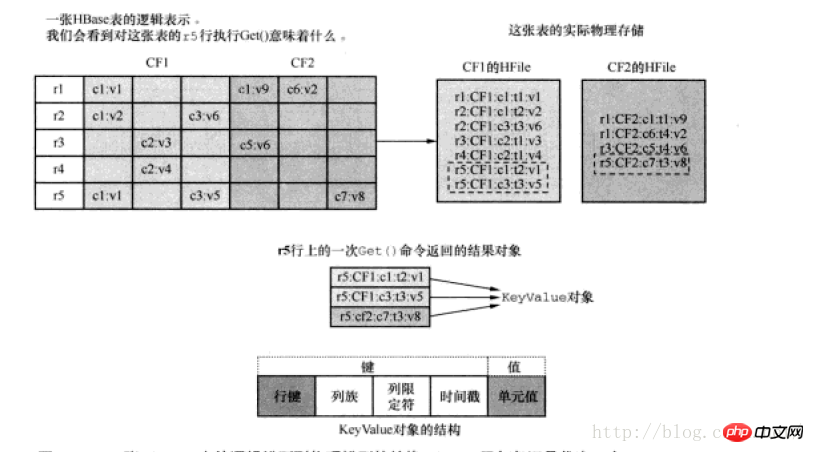
(2) Einige Unterschiede zwischen CRUD
CRUD ist die grundlegendste und am häufigsten verwendete Operation der Datenbank. Es gibt auch entsprechende Befehle in hbase. Zum Beispiel die Tabellenerstellungsanweisung MySQL wird hier nicht detailliert beschrieben. Für die hbase-Shell wird wie folgt erstellt:
Erstellen Sie „Tabelle“, „Spaltenfamilie“
, um eine Tabelle mit dem Namen „Tabelle“ zu erstellen. Die Spaltenfamilie lautet „Spaltenfamilie“ und einige andere Blockgrößen- und Versionsdaten sind Standard.
Verwenden Sie beim Lesen von Daten hbase-Anweisungen wie: get 'table', 'row', 'cf:column', um die entsprechenden Daten abzurufen.
Beim Aktualisieren data, use hbase Es gibt kein Konzept für entsprechende Updates, aber es wird eine neue Version geben, die sich aus dem Zeitstempel ableiten lässt. Die verwendeten Anweisungen sind
put 'table', 'row', 'cf: name', 'value '
kann den Wert von value der entsprechenden CF-Spaltenfamilie zuweisen. Der Unterschied zum Löschen von Daten in der Namensspalte
besteht darin, dass das Löschen von Daten in MySQL nur direkt gelöscht werden kann eine Zeile oder ändern Sie eine bestimmte Spalte. Setzen Sie sie auf leer, und Sie können eine bestimmte Spalte in hbase direkt löschen
(3) Unterschiede in Indizes
In MySQL können Sie Indizes erstellen oder filtern Abfragen, aber in hbase wird nur rowkey unterstützt. Die schnellste Abfragegeschwindigkeit
(4) Gedanken zur Entwicklung von MySQL zu NoSQL
Relationale Datenbanken haben eine lange Geschichte, aber wenn die Datenmenge zunimmt, beispielsweise bei der MySQL-Datenbank, wenn die Datenmenge Hunderte erreicht von Millionen oder mehr Wenn Sie eine Abfrage basierend auf dem Index durchführen, ist der Effekt möglicherweise nicht besonders offensichtlich. Am Ende können Sie nur eine Abfrage basierend auf dem Primärschlüssel durchführen oder sich schrittweise zu einem Unterdatenbank- und Untertabellenmodell entwickeln. Da die Unterdatenbank und die Untertabelle jedoch große Probleme beim Betrieb, der Wartung und der Verwendung mit sich bringen, wird die Entwicklung und Erweiterung des Primärschlüssels der Nosql-Datenbank, abgekürzt als Nosql, schrittweise durchgeführt Die Datenmenge hat sich dramatisch erhöht. Am Beispiel von hbase werden TB- und PB-Daten sowie Spalten unterstützt.
(5) Warum kann hbase riesige Datenmengen speichern?
Tatsächlich kann hbase als Ergebnis der MySQL-Subdatenbank und der Tabellenpartitionierung betrachtet werden. Der Unterschied besteht jedoch darin, dass die MySQL-Subdatenbank in unterteilt ist. Die Tabelle unterstützt Indizes usw., hbase unterstützt jedoch nur den Zeilenschlüssel als primären Schlüsselindex. Aus dem Buch können wir ersehen, dass hbase-Daten nach Spalten gespeichert werden. Wenn die Daten zu groß sind, werden sie nach Zeilen aufgeteilt, wie unten gezeigt: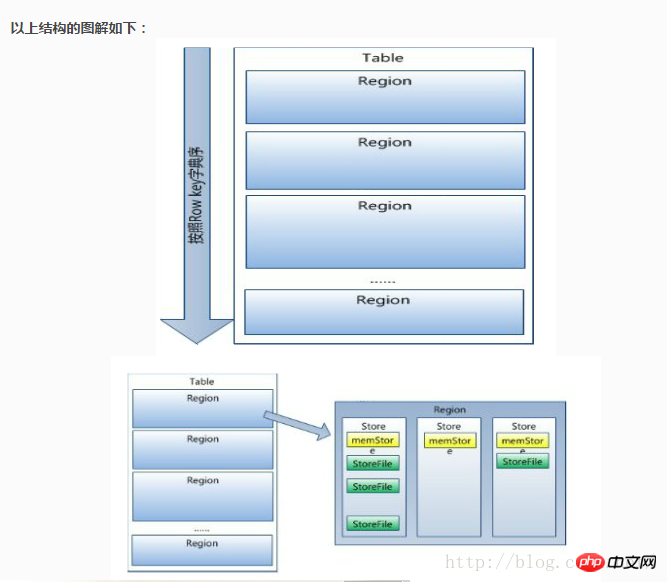


Im Folgenden finden Sie einige Gedanken und Entwürfe zur Migration von Daten von MySQL nach Hbase. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (www.php.org). php.cn)!