
Heim >Datenbank >MySQL-Tutorial >【MySQL】Logische MySQL-Architektur
【MySQL】Logische MySQL-Architektur

- 黄舟Original
- 2017-02-25 10:26:211693Durchsuche
Wenn Sie in Ihrem Kopf ein Architekturdiagramm erstellen können, das zeigt, wie die verschiedenen Komponenten von MySQL zusammenarbeiten, wird Ihnen das dabei helfen, den MySQL-Server besser zu verstehen.
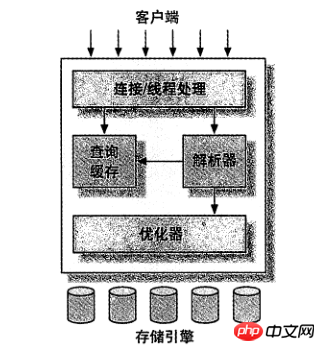
Der Top-Level-Dienst gibt es nicht nur bei MySQL, die meisten netzwerkbasierten Client/Server-Tools haben eine ähnliche Architektur. Wie Verbindungsverarbeitung, Autorisierungsauthentifizierung, Sicherheit usw.
Die Second-Layer-Architektur ist der interessantere Teil von MySQL. Die meisten Kerndienstfunktionen von MySQL befinden sich in dieser Ebene, einschließlich Abfrageanalyse, Analyse, Optimierung, Caching und allen integrierten Funktionen (z. B. Datum, Uhrzeit, Mathematik und Verschlüsselungsfunktionen). Alle speicherübergreifenden Engine-Funktionen sind vorhanden diese Ebene Implementierung: gespeicherte Prozeduren, Trigger, Ansichten usw.
Die dritte Schicht enthält die Speicher-Engine. Die Speicher-Engine ist für das Speichern und Abrufen von Daten in MySQL verantwortlich. Wie verschiedene Dateisysteme unter GNU/Linux hat jede Speicher-Engine ihre Vor- und Nachteile. Der Server kommuniziert über APIs mit der Speicher-Engine. Diese Schnittstellen schirmen die Unterschiede zwischen verschiedenen Speicher-Engines ab und machen diese Unterschiede für den Abfrageprozess der oberen Ebene transparent. Die Storage-Engine-API enthält mehr als ein Dutzend Low-Level-Funktionen zum Ausführen von Vorgängen wie „Starten einer Transaktion“ oder „Extrahieren einer Datensatzzeile basierend auf dem Primärschlüssel“. Aber die Speicher-Engine analysiert SQL nicht (Hinweis: InnoDB ist eine Ausnahme, es analysiert Fremdschlüsseldefinitionen, da der MySQL-Server selbst diese Funktion nicht implementiert), und verschiedene Speicher-Engines kommunizieren nicht miteinander, sondern antworten einfach an die Serveranforderung der oberen Schicht.
Verbindungsverwaltung und -sicherheit
Jede Client-Verbindung verfügt über einen Thread im Serverprozess. Die Abfrage für diese Verbindung wird nur in diesem separaten Thread ausgeführt, der nur abwechselnd ausgeführt werden kann ein bestimmter CPU-Kern oder eine bestimmte CPU. Der Server ist für das Zwischenspeichern von Threads verantwortlich, sodass nicht für jede neue Verbindung Threads erstellt oder zerstört werden müssen. (Hinweis: MySQL 5.5 oder höher bietet eine API, die das Thread-Pool-Plug-in unterstützt, das eine kleine Anzahl von Threads im Pool verwenden kann, um eine große Anzahl von Verbindungen zu bedienen.)
Wenn ein Client (Anwendung) eine Verbindung zum MySQL-Server herstellt, muss der Server ihn authentifizieren. Die Authentifizierung basiert auf Benutzername, ursprünglichen Hostinformationen und Passwort. Wenn Sie eine Secure Socket (SSL)-Verbindung verwenden, können Sie auch die X.509-Zertifikatauthentifizierung verwenden. Sobald der Client erfolgreich eine Verbindung hergestellt hat, überprüft der Server weiterhin, ob der Client über die Berechtigung für eine bestimmte Abfrage verfügt (z. B. ob der Client eine SELECT-Anweisung für die Ländertabelle der Weltdatenbank ausführen darf).
Optimierung und Ausführung
MySQL analysiert die Abfrage und erstellt eine interne Datenstruktur (Analysebaum) und führt dann verschiedene Optimierungen daran durch, einschließlich des Umschreibens der Abfrage und der Bestimmung der Lesereihenfolge der Tabelle sowie die Auswahl geeigneter Indizes usw. Durch spezielle Keyword-Hinweise können Nutzer Einfluss auf die Entscheidungsfindung des Optimierers nehmen. Sie können den Optimierer auch auffordern, verschiedene Faktoren im Optimierungsprozess zu erläutern, damit Benutzer wissen, wie der Server Optimierungsentscheidungen trifft, und eine Referenzbasislinie bereitstellen, um Benutzern die Rekonstruktion von Abfragen und Schemata sowie die Änderung zugehöriger Konfigurationen zu erleichtern, um die Anwendung zu erstellen möglichst effizient laufen.
Dem Optimierer ist es egal, welche Speicher-Engine verwendet wird, aber die Speicher-Engine hat Einfluss auf die Optimierung von Abfragen. Der Optimierer fordert die Speicher-Engine auf, Kapazitäts- oder Kosteninformationen zu einem bestimmten Vorgang sowie statistische Informationen zu Tabellendaten usw. bereitzustellen. Beispielsweise können bestimmte Indizes bestimmter Speicher-Engines für bestimmte Abfragen optimiert werden.
Bei SELECT-Anweisungen überprüft der Server vor dem Parsen der Abfrage zunächst den Abfragecache (Abfragecache). Wenn die entsprechende Abfrage darin gefunden werden kann, muss der Server nicht den gesamten Abfragevorgang durchführen Beim Parsen, Optimieren und Ausführen wird die Ergebnismenge im Abfragecache direkt zurückgegeben.
Wenn Sie in Ihrem Kopf ein Architekturdiagramm erstellen können, das zeigt, wie die verschiedenen Komponenten von MySQL zusammenarbeiten, wird es Ihnen helfen, den MySQL-Server tiefgreifend zu verstehen.
Der Top-Level-Dienst gibt es nicht nur bei MySQL, die meisten netzwerkbasierten Client/Server-Tools haben eine ähnliche Architektur. Wie Verbindungsverarbeitung, Autorisierungsauthentifizierung, Sicherheit usw.
Die Second-Layer-Architektur ist der interessantere Teil von MySQL. Die meisten Kerndienstfunktionen von MySQL befinden sich in dieser Ebene, einschließlich Abfrageanalyse, Analyse, Optimierung, Caching und allen integrierten Funktionen (z. B. Datum, Uhrzeit, Mathematik und Verschlüsselungsfunktionen). Alle speicherübergreifenden Engine-Funktionen sind vorhanden diese Ebene Implementierung: gespeicherte Prozeduren, Trigger, Ansichten usw.
Die dritte Schicht enthält die Speicher-Engine. Die Speicher-Engine ist für das Speichern und Abrufen von Daten in MySQL verantwortlich. Wie verschiedene Dateisysteme unter GNU/Linux hat jede Speicher-Engine ihre Vor- und Nachteile. Der Server kommuniziert über APIs mit der Speicher-Engine. Diese Schnittstellen schirmen die Unterschiede zwischen verschiedenen Speicher-Engines ab und machen diese Unterschiede für den Abfrageprozess der oberen Ebene transparent. Die Storage-Engine-API enthält mehr als ein Dutzend Low-Level-Funktionen zum Ausführen von Vorgängen wie „Starten einer Transaktion“ oder „Extrahieren einer Datensatzzeile basierend auf dem Primärschlüssel“. Aber die Speicher-Engine analysiert SQL nicht (Hinweis: InnoDB ist eine Ausnahme, es analysiert Fremdschlüsseldefinitionen, da der MySQL-Server selbst diese Funktion nicht implementiert), und verschiedene Speicher-Engines kommunizieren nicht miteinander, sondern antworten einfach an die Serveranfrage der oberen Schicht.
Verbindungsverwaltung und -sicherheit
Jede Client-Verbindung verfügt über einen Thread im Serverprozess. Die Abfrage für diese Verbindung wird nur in diesem separaten Thread ausgeführt, der nur abwechselnd ausgeführt werden kann ein bestimmter CPU-Kern oder eine bestimmte CPU. Der Server ist für das Zwischenspeichern von Threads verantwortlich, sodass nicht für jede neue Verbindung Threads erstellt oder zerstört werden müssen. (Hinweis: MySQL 5.5 oder höher bietet eine API, die das Thread-Pool-Plug-in unterstützt, das eine kleine Anzahl von Threads im Pool verwenden kann, um eine große Anzahl von Verbindungen zu bedienen.)
Wenn ein Client (eine Anwendung) eine Verbindung zum MySQL-Server herstellt, muss der Server ihn authentifizieren. Die Authentifizierung basiert auf Benutzername, ursprünglichen Hostinformationen und Passwort. Wenn Sie eine Secure Socket (SSL)-Verbindung verwenden, können Sie auch die X.509-Zertifikatauthentifizierung verwenden. Sobald der Client erfolgreich eine Verbindung hergestellt hat, überprüft der Server weiterhin, ob der Client über die Berechtigung für eine bestimmte Abfrage verfügt (z. B. ob der Client eine SELECT-Anweisung für die Ländertabelle der Weltdatenbank ausführen darf).
Optimierung und Ausführung
MySQL analysiert die Abfrage und erstellt eine interne Datenstruktur (Analysebaum) und führt dann verschiedene Optimierungen daran durch, einschließlich des Umschreibens der Abfrage und der Bestimmung der Lesereihenfolge der Tabelle sowie die Auswahl geeigneter Indizes usw. Durch spezielle Keyword-Hinweise können Nutzer Einfluss auf die Entscheidungsfindung des Optimierers nehmen. Sie können den Optimierer auch auffordern, verschiedene Faktoren im Optimierungsprozess zu erläutern, damit Benutzer wissen, wie der Server Optimierungsentscheidungen trifft, und eine Referenzbasislinie bereitstellen, um Benutzern die Rekonstruktion von Abfragen und Schemata sowie die Änderung zugehöriger Konfigurationen zu erleichtern, um die Anwendung zu erstellen möglichst effizient laufen.
Dem Optimierer ist es egal, welche Speicher-Engine verwendet wird, aber die Speicher-Engine hat einen Einfluss auf die Optimierung von Abfragen. Der Optimierer fordert die Speicher-Engine auf, Kapazitäts- oder Kosteninformationen zu einem bestimmten Vorgang sowie statistische Informationen zu Tabellendaten usw. bereitzustellen. Beispielsweise können bestimmte Indizes bestimmter Speicher-Engines für bestimmte Abfragen optimiert werden.
Bei SELECT-Anweisungen überprüft der Server vor dem Parsen der Abfrage zunächst den Abfragecache (Abfragecache). Wenn die entsprechende Abfrage darin gefunden werden kann, muss der Server nicht den gesamten Abfragevorgang durchführen Beim Parsen, Optimieren und Ausführen wird die Ergebnismenge im Abfragecache direkt zurückgegeben.
Das Obige ist der Inhalt der logischen Architektur von [MySQL] MySQL. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (www.php.cn).