
Heim >Backend-Entwicklung >XML/RSS-Tutorial >XML-Programmierung-DOM
XML-Programmierung-DOM

- 黄舟Original
- 2017-02-20 15:08:131470Durchsuche
XMLProgrammierung-DOM
XML Parsing-Technologie
Es gibt zwei häufig verwendete Arten von XMLParsing-Technologie: dom Parsing und Sax Parsing.
dom: (Dokumentobjektmodell, d. h. Dokumentobjektmodell ) istW3C empfiehlt einen Weg zum Umgang mit XML.
sax: (Simple API for XML) ist kein offizieller Standard, aber es ist XMLDer De-facto-Standard in der Community, fast alle XML-Parser unterstützen ihn.
JaxpEinführung
Jaxp (Java API für XML-Verarbeitung)istJavaEin Entwicklungspaket für die Programmierung von XML, bestehend aus javax.xml, org. Es besteht aus den Paketen w3c.dom , org.xml.sax und deren Unterpaketen.
Im Paketjavax.xml.parsers sind mehrere Factory-Klassen definiert. Wenn Programmierer diese Factory-Klassen aufrufen, können sie die abrufen xml Dokument analysiertes DOM oder SAX Parserobjekt.
DOMGrundlegende Übersicht
DOM (Document Object Model Document Object Model), ja W3C Eine Standardprogrammierschnittstelle für den Umgang mit erweiterbaren Auszeichnungssprachen, die von der Organisation empfohlen werden. XML DOM definiert die Objekte und Attribute aller XML -Elemente sowie die Methoden (Schnittstellen), um auf sie zuzugreifen.
Schema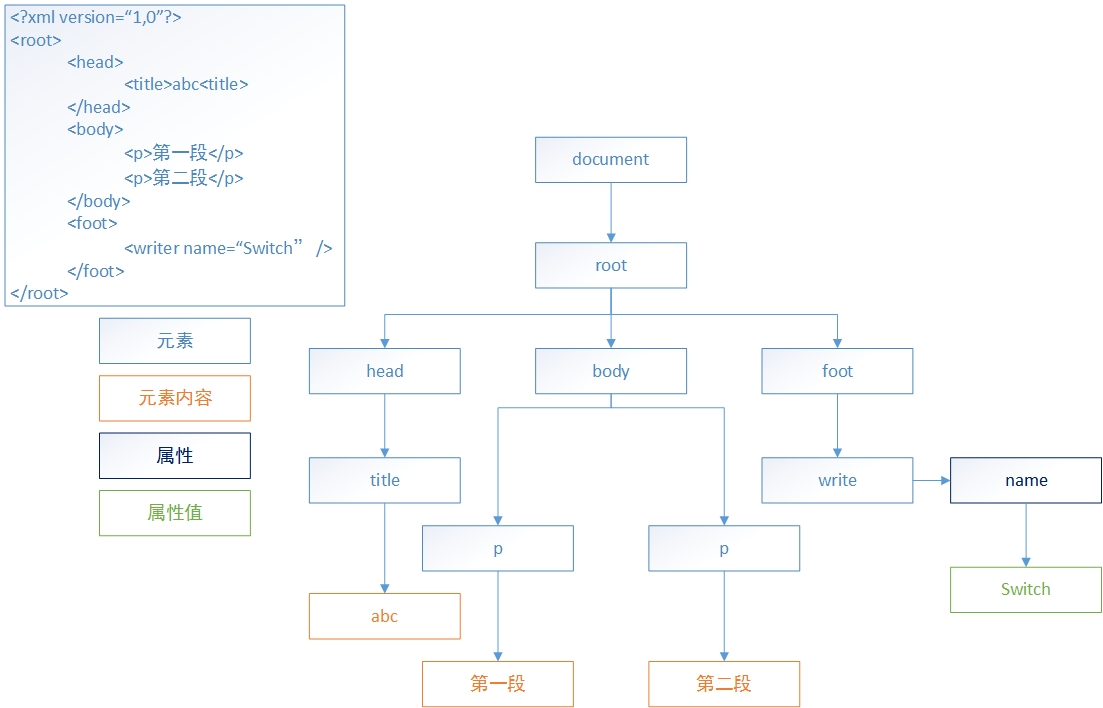
DOM
Modell(Dokumentobjektmodell)
-Parser das XML-Dokument analysiert, analysiert er alle Elemente im Dokument in einzelne KnotenObjekt(Knoten).
Indom ist die Beziehung zwischen Knoten wie folgt:
1, liegen auf einem Knoten Der Knoten ist der übergeordnete Knoten des Knotens (parent)
2, Der Knoten unter einem Knoten ist der untergeordnete Knoten des Knotens (untergeordnete Elemente). )
3, Knoten auf derselben Ebene und mit demselben übergeordneten Knoten sind Geschwisterknoten (Geschwisterknoten)
4 ,Die Menge der Knoten auf der nächsten Ebene eines Knotens sind die Knotennachkommen (Nachkommen)
5, Eltern-, Großelternknoten und alle lokalisierten Knoten Über dem Knoten befinden sich Vorfahren des Knotens (Ancestor)
Node-Objekt
Node-Objekt, das a bereitstellt Reihe von Konstanten zur Darstellung des Knotentyps. Wenn Entwickler einen bestimmten Node-Typ erhalten, können sie den Node-Knoten in den umwandeln entsprechendes Knotenobjekt. (Knotens Unterklassenobjekt ), um den Aufruf seiner eindeutigen Methoden zu erleichtern. (Siehe API-Dokumentation)
Das Node-Objekt stellt entsprechende Methoden zum Abrufen seines übergeordneten oder untergeordneten Knotens bereit. Mit diesen Methoden können Programmierer den Inhalt des gesamten XML-Dokuments lesen oder den Inhalt des XML Dokument.
PS: Seine Unterschnittstelle Element hat mehr Funktionen.
Holen Sie sich denDOM-ParserJaxp 🎜 >1
, rufen Sie die MethodeDocumentBuilderFactory.newInstance() auf, um die Factory des DOM-Parsers zu erstellen. 2
, rufen Sie die MethodenewDocumentBuilder() des Objekts DocumentBuilderFactory auf, um DOMParser-Objekt,, das das Objekt von DocumentBuilder ist. 3, rufen Sie die Methode
parse() des DocumentBuilder-Objekts auf 🎜>XML-Dokument, rufen Sie das Document-Objekt ab, das das gesamte Dokument darstellt. 4 über Document
-Objekte und einige verwandte Klassen und Methoden bis hin zu XML Dokument zum Betrieb. Aktualisiertes XML
Dokument
javax.xml.transform im Paket Das Die Klasse Transformer
wird verwendet, um das Objekt Document, das die Datei XML darstellt, in ein bestimmtes Format zu konvertieren . Für die Ausgabe wenden Sie beispielsweise ein Stylesheet auf die xml-Datei an und konvertieren Sie diese in ein html-Dokument. Mit diesem Objekt können Sie natürlich auch das Document-Objekt in eine XML-Datei umschreiben.
Die Klasse Transformer schließt den Transformationsvorgang über die Methode transform ab, die eine Quelle und ein Ziel empfängt. Wir können das zu konvertierende Objekt
documentverknüpfen über: javax.xml.transform.dom.DOMSource Klasse,
Verwenden Sie das Objekt javax.xml.transform.stream.StreamResult , um das Ziel der Daten darzustellen. Das
Transformer-Objekt wird über TransformerFactory abgerufen.
Fall:
XML5.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?><班级 班次="1班" 编号="C1"> <学生 地址="湖南" 学号="n1" 性别="男" 授课方式="面授" 朋友="n2" 班级编号="C1"> <名字>张三</名字> <年龄>20</年龄> <介绍>不错</介绍> </学生> <学生 学号="n2" 性别="女" 授课方式="面授" 朋友="n1 n3" 班级编号="C1"> <名字>李四</名字> <年龄>18</年龄> <介绍>很好</介绍> </学生> <学生 学号="n3" 性别="男" 授课方式="面授" 朋友="n2" 班级编号="C1"> <名字>王五</名字> <年龄>22</年龄> <介绍>非常好</介绍> </学生> <学生 性别="男"> <名字>小明</名字> <年龄>30</年龄> <介绍>好</介绍> </学生> </班级>
package com.pc;
import java.awt.List;
import java.util.ArrayList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerFactoryConfigurationError;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
*
* @author Switch
* @function Java解析XML
*
*/
public class XML5 {
// 使用dom技术对xml文件进行操作
public static void main(String[] args) throws Exception {
// 1.创建一个DocumentBuilderFactory对象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory
.newInstance();
// 2.通过DocumentBuilderFactory,得到一个DocumentBuilder对象
DocumentBuilder documentBuilder = documentBuilderFactory
.newDocumentBuilder();
// 3.指定解析哪个xml文件
Document document = documentBuilder.parse("src/com/pc/XML5.xml");
// 4.对XML文档操作
// System.out.println(document);
// list(document);
// read(document);
// add(document);
// delete(document, "小明");
update(document, "小明", "30");
}
// 更新一个元素(通过名字更新一个学生的年龄)
public static void update(Document doc, String name, String age)
throws Exception {
NodeList nodes = doc.getElementsByTagName("名字");
for (int i = 0; i < nodes.getLength(); i++) {
Element nameE = (Element) nodes.item(i);
if (nameE.getTextContent().equals(name)) {
Node prNode = nameE.getParentNode();
NodeList stuAttributes = prNode.getChildNodes();
for (int j = 0; j < stuAttributes.getLength(); j++) {
Node stuAttribute = stuAttributes.item(j);
if (stuAttribute.getNodeName().equals("年龄")) {
stuAttribute.setTextContent(age);
}
}
}
}
updateToXML(doc);
}
// 删除一个元素(通过名字删除一个学生)
public static void delete(Document doc, String name) throws Exception {
// 找到第一个学生
NodeList nodes = doc.getElementsByTagName("名字");
for (int i = 0; i < nodes.getLength(); i++) {
Node node = nodes.item(i);
if (node.getTextContent().equals(name)) {
Node prNode = node.getParentNode();
prNode.getParentNode().removeChild(prNode);
}
}
// 更新到XML
updateToXML(doc);
}
// 添加一个学生到XML文件
public static void add(Document doc) throws Exception {
// 创建一个新的学生节点
Element newStu = doc.createElement("学生");
newStu.setAttribute("性别", "男");
Element newStu_name = doc.createElement("名字");
newStu_name.setTextContent("小明");
Element newStu_age = doc.createElement("年龄");
newStu_age.setTextContent("21");
Element newStu_intro = doc.createElement("介绍");
newStu_intro.setTextContent("好");
newStu.appendChild(newStu_name);
newStu.appendChild(newStu_age);
newStu.appendChild(newStu_intro);
// 把新的学生节点添加到根元素
doc.getDocumentElement().appendChild(newStu);
// 更新到XML
updateToXML(doc);
}
// 更新到XML
private static void updateToXML(Document doc)
throws TransformerFactoryConfigurationError,
TransformerConfigurationException, TransformerException {
// 得到TransformerFactory对象
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
// 通过TransformerFactory对象得到一个转换器
Transformer transformer = transformerFactory.newTransformer();
transformer.transform(new DOMSource(doc), new StreamResult(
"src/com/pc/XML5.xml"));
}
// 具体查询某个学生的信息(小时第一个学生的所有)
public static void read(Document doc) {
NodeList nodes = doc.getElementsByTagName("学生");
// 取出第一个学生
Element stu1 = (Element) nodes.item(0);
Element name = (Element) stu1.getElementsByTagName("名字").item(0);
System.out.println("姓名:" + name.getTextContent() + " 性别:"
+ stu1.getAttribute("性别"));
}
// 遍历该XML文件
public static void list(Node node) {
if (node.getNodeType() == node.ELEMENT_NODE) {
System.out.println("名字:" + node.getNodeName());
}
// 取出node的子节点
NodeList nodes = node.getChildNodes();
for (int i = 0; i < nodes.getLength(); i++) {
// 显示所有子节点
Node n = nodes.item(i);
list(n);
}
}
} Das Obige ist der Inhalt des XML-Programmierdoms. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (www.php.cn).
In Verbindung stehende Artikel
Mehr sehen- Verwenden von dom4j zum Parsen von XML in Java (Beispielcode)
- Wie liest Java XML-Dateien? Spezifische Implementierung
- Java-Beispielcode zum Generieren und Parsen von Dateien und Zeichenfolgen im XML-Format
- Lösung für die Verwendung von Sax zum Parsen von XML in Java
- Java verwendet XPath, um die gemeinsame Nutzung von XML-Beispielen zu analysieren