
Heim >Java >javaLernprogramm >Anmerkungen zur Java-NIO-Pufferstudie
Anmerkungen zur Java-NIO-Pufferstudie

- 黄舟Original
- 2017-02-20 10:02:101454Durchsuche
Puffer ist eigentlich ein Containerobjekt, das einige Daten enthält, die geschrieben oder einfach gelesen werden sollen. Das Hinzufügen des Buffer-Objekts zu NIO spiegelt einen wichtigen Unterschied zwischen der neuen Bibliothek und dem ursprünglichen I/O wider. Bei streamorientierter E/A schreiben oder lesen Sie Daten direkt in ein Stream-Objekt.
In der NIO-Bibliothek werden alle Daten mithilfe von Puffern verarbeitet. Beim Lesen von Daten werden diese direkt in den Puffer eingelesen. Wenn Daten geschrieben werden, werden sie in einen Puffer geschrieben. Jedes Mal, wenn Sie in NIO auf Daten zugreifen, legen Sie diese in einen Puffer.
Ein Puffer ist im Wesentlichen ein Array. Normalerweise handelt es sich um ein Byte-Array, es können jedoch auch andere Arten von Arrays verwendet werden. Aber ein Puffer ist mehr als nur ein Array. Puffer ermöglichen einen strukturierten Zugriff auf Daten und können außerdem die Lese-/Schreibvorgänge des Systems verfolgen.
Der am häufigsten verwendete Puffertyp ist ByteBuffer. Ein ByteBuffer kann Get/Set-Vorgänge (d. h. Byte-Erfassung und -Festlegung) für sein zugrunde liegendes Byte-Array ausführen.
ByteBuffer ist nicht der einzige Puffertyp in NIO. Tatsächlich gibt es für jeden grundlegenden Java-Typ einen Puffertyp (nur der boolesche Typ hat keine entsprechende Pufferklasse):
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
Jede Buffer-Klasse ist eine Instanz der Buffer-Schnittstelle. Mit Ausnahme von ByteBuffer hat jede Buffer-Klasse genau die gleichen Operationen, aber die Datentypen, die sie verarbeiten, sind unterschiedlich. Da die meisten Standard-E/A-Operationen ByteBuffer verwenden, verfügt es über alle gemeinsam genutzten Pufferoperationen sowie einige einzigartige Operationen. Werfen wir einen Blick auf das Klassenhierarchiediagramm von Buffer: 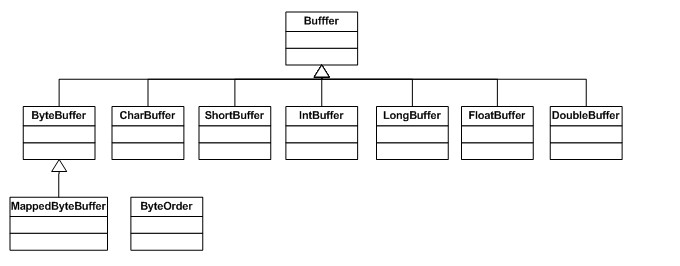
Jeder Buffer hat die folgenden Attribute:
Kapazität
Die maximale Datenmenge, die dieser Puffer aufnehmen kann. Die Kapazität wird normalerweise beim Erstellen des Puffers angegeben.
Limit
Auf dem Puffer ausgeführte Lese- und Schreibvorgänge dürfen diesen Index nicht überschreiten. Beim Schreiben von Daten in den Puffer entspricht das Limit im Allgemeinen der Kapazität. Beim Lesen von Daten stellt das Limit die Länge der gültigen Daten im Puffer dar.
Position
Die Positionsvariable verfolgt, wie viele Daten in den Puffer geschrieben oder daraus gelesen werden.
Genauer gesagt: Wenn Sie Daten aus dem Kanal in den Puffer lesen, zeigt dies an, in welches Element des Arrays die nächsten Daten eingefügt werden. Wenn Sie beispielsweise drei Bytes aus dem Kanal in einen Puffer lesen, wird die Position des Puffers auf 3 gesetzt und zeigt auf das 4. Element im Array. Wenn Sie umgekehrt Daten aus einem Puffer für einen Schreibkanal erhalten, zeigt dies an, von welchem Element des Arrays die nächsten Daten stammen. Wenn Sie beispielsweise 5 Bytes vom Puffer in den Kanal schreiben, wird die Position des Puffers auf 5 gesetzt und zeigt auf das sechste Element des Arrays.
Markierung
Ein temporärer Speicherortindex. Durch den Aufruf von mark() wird mark auf den Wert der aktuellen Position gesetzt, und durch den späteren Aufruf von reset() wird die Positionseigenschaft auf den Wert von mark gesetzt. Der Wert von mark ist immer kleiner oder gleich dem Wert von position. Wenn der Wert von position kleiner als mark ist, wird der aktuelle Markenwert verworfen.
Diese Eigenschaften erfüllen immer die folgenden Bedingungen:
0 <= mark <= position <= limit <= capacity
Der interne Implementierungsmechanismus des Puffers:
Nachfolgend nehmen wir das Beispiel des Kopierens von Daten von einem Eingabekanal in einen Ausgabekanal, um jede Variable im Detail zu analysieren. und Erklären Sie, wie sie zusammenarbeiten:
Anfangsvariablen:
Wir beobachten zunächst einen neu erstellten Puffer, nehmen als Beispiel ByteBuffer und gehen davon aus, dass die Größe des Puffers 8 Byte beträgt. ByteBuffer Der Anfangszustand lautet wie folgt: 
Denken Sie daran, dass der Grenzwert niemals größer als die Kapazität sein kann und beide Werte in diesem Beispiel auf 8 gesetzt sind. Wir veranschaulichen dies, indem wir sie auf das Ende des Arrays (Steckplatz 8) richten. 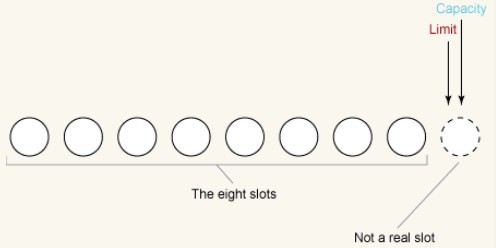
Wir setzen die Position wieder auf 0. Zeigt an, dass, wenn wir einige Daten in den Puffer lesen, die nächsten gelesenen Daten in Steckplatz 0 eingehen. Wenn wir einige Daten aus dem Puffer schreiben, kommt das nächste aus dem Puffer gelesene Byte aus Steckplatz 0. Die Positionseinstellung ist wie folgt: 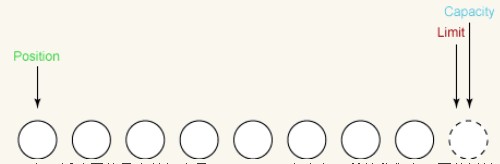
Da sich die maximale Datenkapazität des Puffers nicht ändert, können wir sie in der folgenden Diskussion ignorieren.
Erster Lesevorgang:
Jetzt können wir mit Lese-/Schreibvorgängen für den neu erstellten Puffer beginnen. Lesen Sie zunächst einige Daten vom Eingangskanal in den Puffer. Der erste Lesevorgang erhält drei Bytes. Sie werden im Array beginnend an der Position platziert, die auf 0 gesetzt ist. Nach dem Lesen hat sich die Position auf 3 erhöht, wie unten gezeigt, und der Grenzwert hat sich nicht geändert. 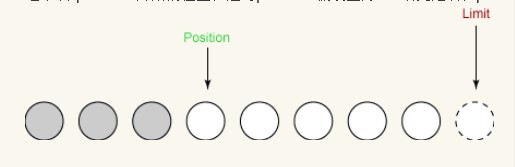
Zweiter Lesevorgang:
Beim zweiten Lesevorgang lesen wir weitere zwei Bytes aus dem Eingangskanal in den Puffer. Diese beiden Bytes werden an der durch Position angegebenen Stelle gespeichert, die Position wird somit um 2 erhöht und der Grenzwert bleibt unverändert. 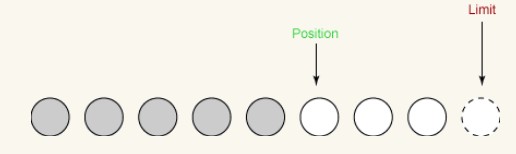
flip:
Jetzt wollen wir die Daten in den Ausgabekanal schreiben. Zuvor müssen wir die Methode flip() aufrufen. Der Quellcode lautet wie folgt:
public final Buffer flip()
{
limit = position;
position = 0;
mark = -1;
return this;
}
这个方法做两件非常重要的事:
i 它将limit设置为当前position。
ii 它将position设置为0。Das vorherige Bild zeigt den Puffer vor dem Umdrehen. Hier ist der Puffer nach dem Flip: 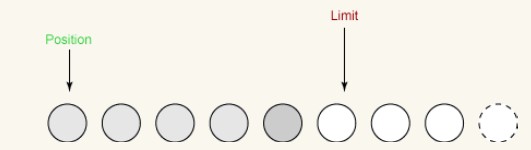
Wir können jetzt Daten aus dem Puffer in den Kanal schreiben. Position ist auf 0 gesetzt, was bedeutet, dass das nächste Byte, das wir erhalten, das erste Byte ist. Das Limit wurde auf die ursprüngliche Position gesetzt, was bedeutet, dass es alle zuvor gelesenen Bytes umfasst und kein einziges Byte mehr.
Erster Schreibvorgang:
Beim ersten Schreibvorgang nehmen wir vier Bytes aus dem Puffer und schreiben sie in den Ausgabekanal. Dadurch erhöht sich die Position auf 4, während das Limit unverändert bleibt, wie folgt: 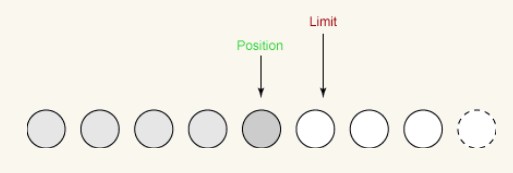
Zweiter Schreibvorgang:
Es bleibt nur noch ein Byte übrig, das geschrieben werden kann. Das Limit wird auf 5 gesetzt, wenn wir flip() aufrufen, und die Position darf das Limit nicht überschreiten. Der letzte Schreibvorgang entnimmt also ein Byte aus dem Puffer und schreibt es in den Ausgabekanal. Dadurch wird die Position auf 5 erhöht und das Limit wie folgt unverändert gelassen: 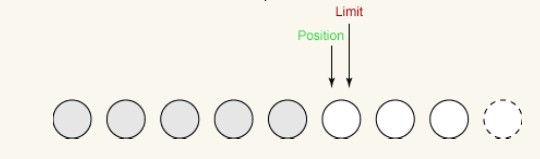
clear:
Der letzte Schritt besteht darin, die Methode „clear()“ des Puffers aufzurufen. Diese Methode setzt den Puffer zurück, um mehr Bytes zu empfangen. Der Quellcode lautet wie folgt:
public final Buffer clear()
{
osition = 0;
limit = capacity;
mark = -1;
return this;
}clear führt zwei sehr wichtige Dinge aus:
i Es setzt den Grenzwert auf denselben Wert wie die Kapazität.
ii Es setzt die Position auf 0.
Die folgende Abbildung zeigt den Status des Puffers nach dem Aufruf von clear(). Der Puffer ist nun bereit, neue Daten zu empfangen. 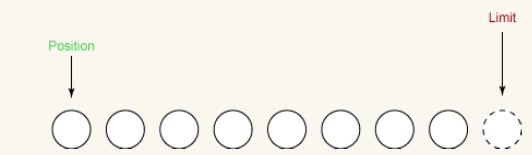
Bisher haben wir nur Puffer verwendet, um Daten von einem Kanal zum anderen zu übertragen. Allerdings müssen Programme Daten oft direkt verarbeiten. Beispielsweise müssen Sie möglicherweise Benutzerdaten auf der Festplatte speichern. In diesem Fall müssen Sie diese Daten direkt in einen Puffer legen und dann einen Kanal verwenden, um den Puffer auf die Festplatte zu schreiben. Alternativ möchten Sie möglicherweise Benutzerdaten von der Festplatte lesen. In diesem Fall lesen Sie die Daten aus dem Kanal in einen Puffer und überprüfen dann den Puffer auf die Daten. Tatsächlich bietet uns jeder grundlegende Puffertyp eine Methode für den direkten Zugriff auf die Daten im Puffer. Nehmen wir ByteBuffer als Beispiel, um zu analysieren, wie die bereitgestellten Methoden get() und put() verwendet werden, um direkt auf die Daten im Puffer zuzugreifen die Pufferdaten.
a) get()
Es gibt vier get()-Methoden in der ByteBuffer-Klasse:
byte get(); ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length ); byte get( int index );
第一个方法获取单个字节。第二和第三个方法将一组字节读到一个数组中。第四个方法从缓冲区中的特定位置获取字节。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 此外,我们认为前三个get()方法是相对的,而最后一个方法是绝对的。“相对”意味着get()操作服从limit和position值,更明确地说, 字节是从当前position读取的,而position在get之后会增加。另一方面,一个“绝对”方法会忽略limit和position值,也不会 影响它们。事实上,它完全绕过了缓冲区的统计方法。 上面列出的方法对应于ByteBuffer类。其他类有等价的get()方法,这些方法除了不是处理字节外,其它方面是是完全一样的,它们处理的是与该缓冲区类相适应的类型。
注:这里我们着重看一下第二和第三这两个方法
ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length );
这两个get()主要用来进行批量的移动数据,可供从缓冲区到数组进行的数据复制使用。第一种形式只将一个数组 作为参数,将一个缓冲区释放到给定的数组。第二种形式使用 offset 和 length 参数来指 定目标数组的子区间。这些批量移动的合成效果与前文所讨论的循环是相同的,但是这些方法 可能高效得多,因为这种缓冲区实现能够利用本地代码或其他的优化来移动数据。
buffer.get(myArray)
等价于:
buffer.get(myArray,0,myArray.length);
注:如果您所要求的数量的数据不能被传送,那么不会有数据被传递,缓冲区的状态保持不 变,同时抛出 BufferUnderflowException 异常。因此当您传入一个数组并且没有指定长度,您就相当于要求整个数组被填充。如果缓冲区中的数据不够完全填满数组,您会得到一个 异常。这意味着如果您想将一个小型缓冲区传入一个大数组,您需要明确地指定缓冲区中剩 余的数据长度。上面的第一个例子不会如您第一眼所推出的结论那样,将缓冲区内剩余的数据 元素复制到数组的底部。例如下面的代码:
String str = "com.xiaoluo.nio.MultipartTransfer";
ByteBuffer buffer = ByteBuffer.allocate(50);
for(int i = 0; i < str.length(); i++)
{
buffer.put(str.getBytes()[i]);
}
buffer.flip();byte[] buffer2 = new byte[100];
buffer.get(buffer2);
buffer.get(buffer2, 0, length);
System.out.println(new String(buffer2));这里就会抛出java.nio.BufferUnderflowException异常,因为数组希望缓存区的数据能将其填满,如果填不满,就会抛出异常,所以代码应该改成下面这样:
//得到缓冲区未读数据的长度
int length = buffer.remaining();
byte[] buffer2 = new byte[100];
buffer.get(buffer2, 0, length);
b) put()ByteBuffer类中有五个put()方法:
ByteBuffer put( byte b );
ByteBuffer put( byte src[] );
ByteBuffer put( byte src[], int offset, int length );
ByteBuffer put( ByteBuffer src );
ByteBuffer put( int index, byte b );第一个方法 写入(put)单个字节。第二和第三个方法写入来自一个数组的一组字节。第四个方法将数据从一个给定的源ByteBuffer写入这个 ByteBuffer。第五个方法将字节写入缓冲区中特定的 位置 。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 与get()方法一样,我们将把put()方法划分为“相对”或者“绝对”的。前四个方法是相对的,而第五个方法是绝对的。上面显示的方法对应于ByteBuffer类。其他类有等价的put()方法,这些方法除了不是处理字节之外,其它方面是完全一样的。它们处理的是与该缓冲区类相适应的类型。
c) 类型化的 get() 和 put() 方法
除了前些小节中描述的get()和put()方法, ByteBuffer还有用于读写不同类型的值的其他方法,如下所示:
getByte()
getChar()
getShort()
getInt()
getLong()
getFloat()
getDouble()
putByte()
putChar()
putShort()
putInt()
putLong()
putFloat()
putDouble()
事实上,这其中的每个方法都有两种类型:一种是相对的,另一种是绝对的。它们对于读取格式化的二进制数据(如图像文件的头部)很有用。
下面的内部循环概括了使用缓冲区将数据从输入通道拷贝到输出通道的过程。
while(true)
{
//clear方法重设缓冲区,可以读新内容到buffer里
buffer.clear();
int val = inChannel.read(buffer);
if(val == -1)
{
break;
}
//flip方法让缓冲区的数据输出到新的通道里面
buffer.flip();
outChannel.write(buffer);
}read()和write()调用得到了极大的简化,因为许多工作细节都由缓冲区完成了。clear()和flip()方法用于让缓冲区在读和写之间切换。
好了,缓冲区的内容就暂且写到这里,下一篇我们将继续NIO的学习–通道(Channel).
以上就是Java NIO 缓冲区学习笔记 的内容,更多相关内容请关注PHP中文网(www.php.cn)!