
Heim >Backend-Entwicklung >PHP-Tutorial >爬虫如何获得biilbili播放数?
爬虫如何获得biilbili播放数?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-06-17 08:32:021934Durchsuche
<i id="dianji" title="播放"></i><i id="dm_count" title="弹幕"></i><i id="stow_count" title="收藏"></i><i id="pt"><span class="v_ctimes" title="硬币数量"></span></i>
回复内容:
用av2047063举例,访问下面的网址:【网址已隐去】@妹空酱 提醒我才想起来。。。。
先去自己申请一个appkey。。。在这里:
bilibili - 提示
然后就可以对bilibiliapi为所欲为了。。。。
B站第三方客户端就是这么开发出来的。。。


可以看到最后两个参数id=av号&page=分p
play后面的18253即为播放数。
==============================
b站有公开api啊。。。。。。。那么麻烦干嘛。。。 答主的第一次就就交在这里了,,,
———————————————————————————————————————
前不久学习了python,正好复习一下
代码如下:
import re,urllib
page=urllib.urlopen('http://m.acg.tv/video/av2046040.html')
HTML=page.read()
re_times=r'
result = re.findall(re_times,HTML)
re_title=r'
(.*)
'title=re.findall(re_title,HTML)
print title[0],'的播放次数为',result[0]
下面以av2046040为例:http://www.bilibili.com/video/av2046040/
可以看到
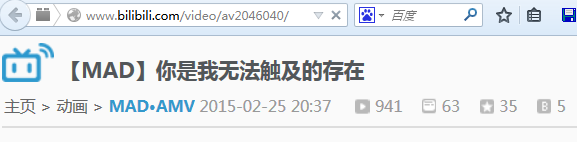 使用火狐查看选中部分源代码,如下
使用火狐查看选中部分源代码,如下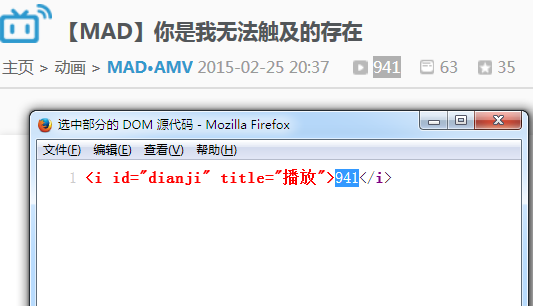 但是我通过python的urllib模块并没有获取到页面内容:
但是我通过python的urllib模块并没有获取到页面内容:page=urllib.urlopen('http://www.bilibili.com/video/av2046040/')
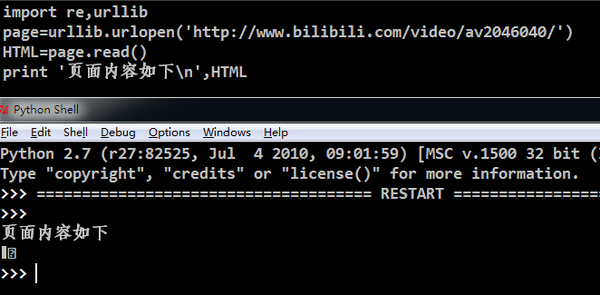 于是我转换思路,貌似B站的手机版网页可以,
于是我转换思路,貌似B站的手机版网页可以,然后使用火狐的User-Agent Overrider修改浏览器UA为Android FireFox/29
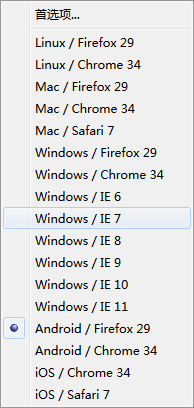 既可以获得如下界面:
既可以获得如下界面: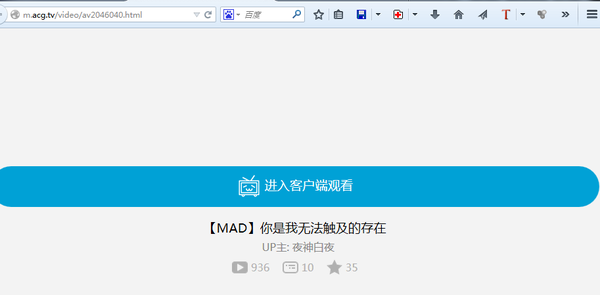 获取到页面实际地址后,就可以再次使用火狐查看源代码
获取到页面实际地址后,就可以再次使用火狐查看源代码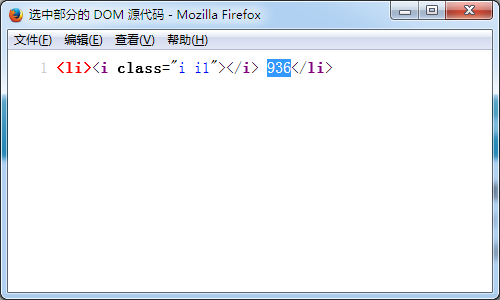 既可以写出正则表达式:
既可以写出正则表达式:re_times=r'
然后正则匹配就好了。
<code class="language-python"><span class="c"># encoding=utf8</span>
<span class="c"># author:shell-von</span>
<span class="kn">import</span> <span class="nn">requests</span>
<span class="kn">import</span> <span class="nn">re</span>
<span class="n">aid</span> <span class="o">=</span> <span class="s">'3210612'</span>
<span class="n">api_key</span> <span class="o">=</span> <span class="s">"http://interface.bilibili.com/count?key=27f582250563d5d6b11d6833&aid=</span><span class="si">%s</span><span class="s">"</span>
<span class="n">data</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">api_key</span> <span class="o">%</span> <span class="n">aid</span><span class="p">)</span><span class="o">.</span><span class="n">content</span>
<span class="n">regex</span> <span class="o">=</span> <span class="s">r"\('(?:.|#)([\w_]+)'\)\.html\('?(\d+)'?\)"</span>
<span class="k">print</span> <span class="nb">dict</span><span class="p">(</span><span class="n">re</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="n">regex</span><span class="p">,</span> <span class="n">data</span><span class="p">))</span>
</code>
以前写过一个。。。。 haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:
haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:<code class="language-matlab"><span class="n">aid</span> <span class="p">=</span> <span class="mi">3295561</span><span class="p">;</span>
<span class="n">api</span> <span class="p">=</span> <span class="s">'http://interface.bilibili.com/count?key=b9415053057bb00966665eaa'</span><span class="p">;</span>
<span class="n">data</span> <span class="p">=</span> <span class="n">regexp</span><span class="p">(</span><span class="n">webread</span><span class="p">(</span><span class="n">api</span><span class="p">,</span><span class="s">'aid'</span><span class="p">,</span><span class="n">aid</span><span class="p">),</span><span class="s">'#(\w)+\D*(\d)+'</span><span class="p">,</span><span class="s">'tokens'</span><span class="p">);</span>
<span class="n">data</span> <span class="p">=</span> <span class="p">[</span><span class="n">data</span><span class="p">{:}]</span>
</code>
说下大概的思路。0、打开特定的av页面,通过这条语句来找到CID和AID。注意:ctrl + u中能看到的源代码就是能匹配的源代码。
1、发送请求到interface.bilibili.com/player?id=cid:(匹配的CID,要前面的冒号)&aid=(匹配的AID)
2、从获取的xml文件中找到
=====================================================
实际上,我们ctrl + u看到的页面是网站发给我们的其中一个包而已,而最终的结果页面是网站发给我们的多个包组合的结果。
有时候,网站会将数据封装在json或者xml中,然后通过多个请求获取数据,最后在本地用js来进行最后的构建。
因此,页面上看到的内容是最后的结果,如果你要判断这个结果来自于源页面还是json还是xml,就需要通过开发者工具抓抓包,然后自己分析。
总之,逻辑就是:
0、这个数据哪来的? —— 通过抓包分析
1、模拟获取这个数据的过程。 —— 直接访问该数据的来源url
当然还要注意你要传的参数。这个参数从哪些地方获取也需要自己分析。
====================================================
还是举个例子吧。
注意:B站发回的数据是gzip,然而urllib2的urlopen不会自动解压,需要手动处理。
可以参考这个回答:
Does python urllib2 automatically uncompress gzip data fetched from webpage?
随便在首页找了个页面,地址如下:
【爱深黑切】路人女主的玩坏方法~第一弹
<code class="language-text">import urllib2
import re
from StringIO import StringIO
import gzip
def find_cid_aid(html):
target = re.compile('EmbedPlayer(?P<args>.*?)',re.DOTALL)
cidaid = target.search(html)
cidaid = html[cidaid.start('args'):cidaid.end('args')]
cid = cidaid.find('cid=')
aid = cidaid.find('&aid=')
index = aid
while cidaid[index] != '"':
index += 1
return (cidaid[cid + 4:aid],cidaid[aid + 5:index])
def find_how_many(cid_aid):
target = re.compile(r'<click>(?P<result>.*?)</result></click>',re.DOTALL)
cid = cid_aid[0]
aid = cid_aid[1]
addr = r'http://interface.bilibili.com/player?id=cid:' + cid + '&aid=' + aid
f = urllib2.urlopen(addr)
res = f.read()
target = target.search(res)
return res[target.start('result'):target.end('result')]
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', \
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3', \
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:28.0) Gecko/20100101 Firefox/28.0',\
'Host':'www.bilibili.com', \
'Accept-Encoding':'gzip, deflate', \
'Cache-Control':'max-age=0', \
'Connection':'keep-alive'}
request = urllib2.Request(r'http://www.bilibili.com/video/av2046145/', headers=headers)
html = urllib2.urlopen(request)
if html.info().get('Content-Encoding') == 'gzip':
buf = StringIO(html.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
cid_aid = find_cid_aid(html)
print find_how_many(cid_aid)
</args></code>
获取cid aid请求http://interface.bilibili.com/player什么东西抓抓包就知道了
比如说如图一样的懒人眼镜,你懂的~~这里的源码直接可以直接用正则匹配到cid和aid,
cid=1511100&aid=1044050
然后请求
http://interface.bilibili.com/player?id=cid:1511100&aid=1044050
然后被
<code class="language-text"><click>4611</click>
</code>
你在电脑屏幕上面看到的一切都是数据来着啊。B站的网页也只不过是一堆代码而已。稍微获取一下源代码,解gzip压缩,转换一下编码,正则表达式搜索一下,就能出来了,很简单的。
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:用vim打开后中文乱码怎么办?Nächster Artikel:有没有轻量的、基础的 PHP 框架?
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)