
Heim >Web-Frontend >js-Tutorial >js中查找最近的共有祖先元素的实现代码_javascript技巧
js中查找最近的共有祖先元素的实现代码_javascript技巧

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 18:12:561414Durchsuche
先来看概念,首先DOM是一棵树,其根节点是Document,大致可以用下图来表示: 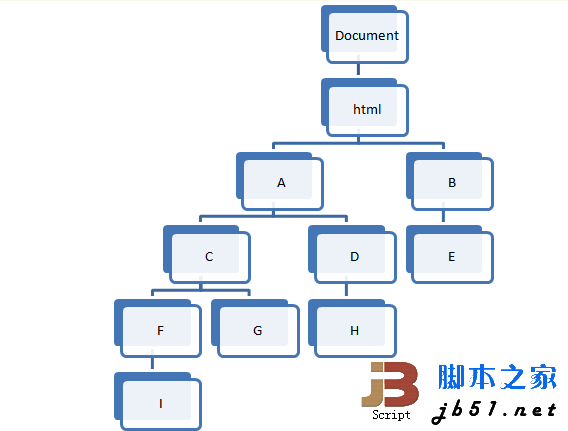
所谓“最近的共有祖先元素”,是指给定一系列元素,找出在树中深度最大的,但同时为所有这些元素的祖先元素的元素。
比如上图中,I和G的结果为C,G和H的结果为A,D和E的结果为html,C和B的结果为html等。
测试驱动
对于偏逻辑的题,并没有十足的把握函数是正确的,因此还是先构造测试的用命,力求让函数通过测试。
本次就以上图的结构作为DOM结构,A表示body,B表示head,其他节点均使用div元素,同时以上文中所说的作为测试的输入和输出,先构造一下测试:
复制代码 代码如下:
function test() {
var result;
result = find('i', 'g');
result.id !== 'c' && alert('fail (i, g)');
result = find('g', 'h');
result.id !== 'a' && alert('fail (g, h)');
result = find('d', 'e');
result.nodeName.toLowerCase() !== 'html' && alert('fail (d, e)');
result = find('c', 'b');
result.nodeName.toLowerCase() !== 'html' && alert('fail (c, b)');
}
基本逻辑
这次的逻辑大致是这样的:
1、针对每个给定的元素,从父元素到document依次向上遍历。
2、对遍历过程中经过的每个元素,保存到一个有序的map中,以元素为键,以遍历到的次数为值。
2、最后遍历map,找同第一个值与给定元素个数相同的项,就是第一个被所有元素的遍历都经过的元素,也即最近的共同祖先元素了。
细节问题
在实际过程中,对map的构建比较重要,这里涉及到2个问题:
1、map不能直接以元素作为键,必须转换为合适的基元类型(如number, string, Regex等)。
2、chrome对object中的键会有自动排序,因此尽量避免使用number类型作为键。
对于第一个问题,必须给元素绑定一个合适的字段,起到唯一性标识符的作用。好在HTML5提供了data-*属性,使DOM的元数据承载能力有了很大的提高,可以大胆地添加希望的属性了。
对于第二个问题,本身也不难,生成的标识符避开number就行了,方便的方法是加个下划线,或者使用String.fromCharCode转成字符,无论怎么样都无所谓。
实现代码
代码有点长,主要是个人比较喜欢偏JAVA的风格,每一个语句每一个分支都清清楚楚,不喜欢用&&或者||来处理条件分支,所以有很多行只有一个大括号之类的情况,其实真正有效的代码还是精简的。懒得装类似toggle之类的插件,也不想看到滚动条,就随便扔在这了。
复制代码 代码如下:
function find() {
var length = arguments.length,
i = 0,
node, //当前节点
parent, //父节点
counter = 0,
uuid, //给DOM的唯一标识符
hash = {}; //最后结果的map
//对每一个元素,向上遍历至document
//这个双层的循环是不可避免的
for (; i //获取node
node = arguments[i];
if (typeof node == 'string') {
node = document.getElementById(node);
}
//向上遍历
while (parent = node.parentElement || node.parentNode) {
//到document就停下来,不然就是死循环
if (parent.nodeType == 9) {
break;
}
//获取或添加一下标识符
uuid = parent.getAttribute('data-find');
if (!uuid) {
uuid = '_' + (++counter); //避免chrome对hash重排序
parent.setAttribute('data-find', uuid);
}
//增加计数
if (hash[uuid]) {
hash[uuid].count++;
}
else {
hash[uuid] = {node: parent, count: 1};
}
node = parent;
}
}
//hash中只存有各节点向上遍历经过的父节点,不应该很大
//因此这个循环是比较快的
for (i in hash) {
if (hash[i].count == length) {
return hash[i].node;
}
}
};
点评
测试没问题,但测试用例是否完善实在不好说,期待网友帮我找出问题来,对于逻辑型的实在是没啥自信说100%没问题。
对于取父元素,习惯性兼容IE写成parentElement || parentNode,这是因为IE的一个BUG,当一个元素刚被创建出来但未进入DOM时,parentNode是不存在的。不过本次函数保证节点在DOM树中,其实parentElement就没有必要了。所以有时候习惯性的兼容代码也不见得就一定是好事,最适合当前环境的代码才是好代码。
虽然说2重循环不可避免,但总隐隐感觉循环还是有办法在特定情况下少做点事,比如向上遍历的时候发现某个元素已经不可能是所有元素的共有祖先了,那么就不要再去递增count值了。
最后的for..in循环有没有办法省掉呢?在上面的2重循环中有没有办法实时地就通过一个变量始终保存最合适的节点呢?
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:javascript 闭包疑问_javascript技巧Nächster Artikel:javascript数字数组去重复项的实现代码_javascript技巧
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse