
Heim >Web-Frontend >js-Tutorial >Prototype源码浅析 String部分(二)_prototype
Prototype源码浅析 String部分(二)_prototype

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 17:57:111034Durchsuche
| 格式 | camelize | capitalize | underscore | dasherize | inspect |
| 变形 | toArray | succ | times |
既然涉及到需要转义的字符,我们自然要一份转义字符信息,下面直接给出:
复制代码 代码如下:
String.specialChar = {
'\b': '\\b',
'\t': '\\t',
'\n': '\\n',
'\f': '\\f',
'\r': '\\r',
'\\': '\\\\'
}
【在JSON.js里面,多了一个'"',因为JSON里面string里面是不能出现"的,所以需要转义】
第一步,当然是要替换特殊的转义字符,初始版本:
复制代码 代码如下:
function inspect() {
return this.replace(/[\b\t\n\f\r\\]/,function(a){
return String.specialChar[a];
});
}
对于JSON形式来说,双引号是必须的,因此,我们应该可以选择自己的返回形式,所以,给inspect一个参数useDoubleQuotes,默认是用单引号返回字符串的。
复制代码 代码如下:
function inspect(useDoubleQuotes) {
var escapedString = this.replace(/[\b\t\n\f\r\\]/,function(a){
return String.specialChar[a];
});
if (useDoubleQuotes){
return '"' + escapedString.replace(/"/g, '\\"') + '"';
}
return "'" + escapedString.replace(/'/g, '\\\'') + "'";
}
现在这跟源码中的功能差不多,不过Prototype源码中的实现方式并不是这样的,主要区别在于escapedString这一段。源码中直接列出来所有的控制字符,表示为[\x00-\x1f],外加'\'就是[\x00-\x1f\\],因此改造上面的初始版本就是:
复制代码 代码如下:
function inspect(useDoubleQuotes) {
var escapedString = this.replace(/[\x00-\x1f\\]/g, function(character) {
if (character in String.specialChar) {
return String.specialChar[character];
}
return character ;
});
if (useDoubleQuotes) return '"' + escapedString.replace(/"/g, '\\"') + '"';
return "'" + escapedString.replace(/'/g, '\\\'') + "'";
}
[html]
附,ASCII控制字符编码表,对应\x00-\x1f:
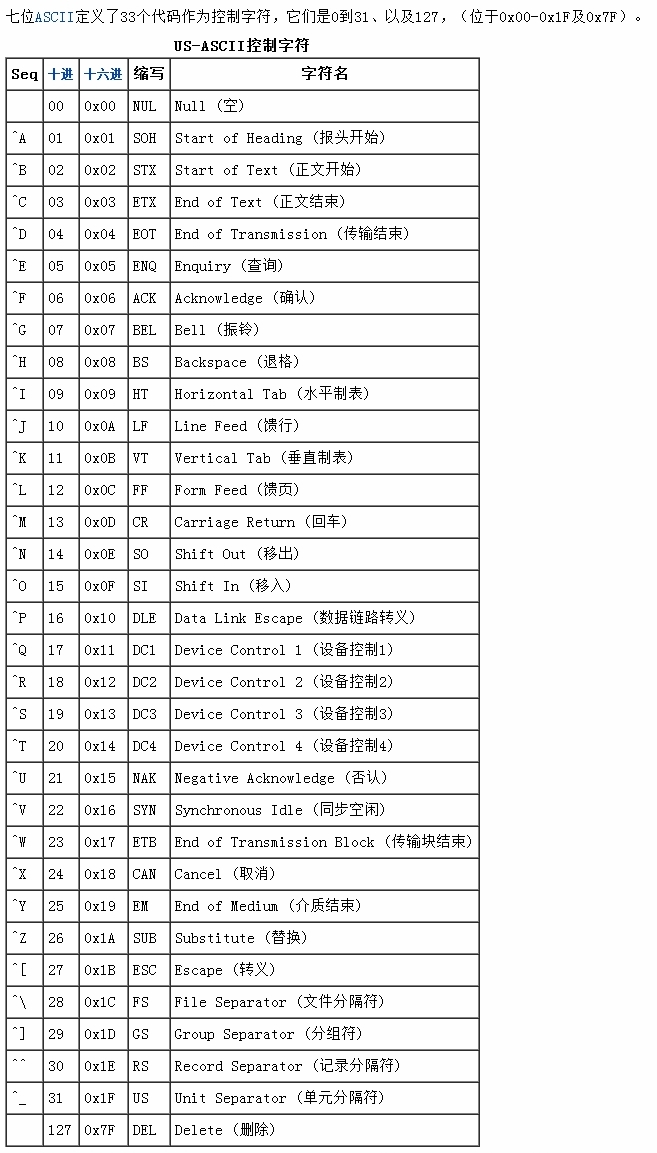
如果发现除了String.specialChar中的字符,还有其他的控制字符,源码中也有一步处理,就是将控制字符转变为unicode的表示形式,因为这个方法本身就是要获得字符串的形式。
比如垂直制表符'\v'。'\v'.inspect() -->'\u000b'
完整版本:
[code]
function inspect(useDoubleQuotes) {
var escapedString = this.replace(/[\x00-\x1f\\]/g, function(character) {
if (character in String.specialChar) {
return String.specialChar[character];
}
return '\\u00' + character.charCodeAt().toPaddedString(2, 16);
});
if (useDoubleQuotes) return '"' + escapedString.replace(/"/g, '\\"') + '"';
return "'" + escapedString.replace(/'/g, '\\\'') + "'";
}
其中toPaddedString(length[, radix])将当前 Number 对象转换为字符串,如果转换后的字符串长度小于 length 指定的值,则用 0 在左边补足其余的位数。可选的参数 radix 用于指定转换时所使用的进制。这是Prototype中Number的一个扩展,暂时知道即可。
因此'\v'.charCodeAt().toPaddedString(2, 16)就是将'\v'的字符编码转换成16进制的两位编码符[操作字符不会范围有限制,因此不会超出],最后冠以'\u00'开头即可。
方法说明:
toArray:将字符串拆分为字符数组。
succ:根据 Unicode 字母表转换字符串最后的字符为后续的字符
times:将字符串重复。
对应具体的实现也很简单,String部分的重要之处在于后面的脚本,JSON和替换处理,其他都是增强性质的。
复制代码 代码如下:
function toArray() {
return this.split('');
}
其中split('')就将字符串打撒为单个字符,并以数组形式返回,如果还要再增强,可以给一个参数给toArray来指定分隔符。
复制代码 代码如下:
function toArray(pattern) {
return this.split(pattern);
}
console.log(toArray.call('my name is xesam',' '));//["my", "name", "is", "xesam"]
就是对split的使用而已,不过源码中并没有这么做,因为并没有这个必要。
复制代码 代码如下:
function succ() {
return this.slice(0, this.length - 1) + String.fromCharCode(this.charCodeAt(this.length - 1) + 1);
}
这里主要的就是fromCharCode和charCodeAt方法的使用。从代码中也可以看出,两者的明显区别是fromCharCode是String的静态方法,而charCodeAt是字符串的方法(挂在String.prototype上面)。然后两者的作用正好相反,下面是http://www.w3school.com.cn给出的解释:
fromCharCode() 可接受一个指定的 Unicode 值,然后返回一个字符串。
charCodeAt() 方法可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数。
具体到succ,以字符串‘hello xesam'为例,先获取除结尾字符外的所有字符‘hello xesa',然后加上Unicode表中‘m'后面的一个字符‘n',因此结果就是‘hello xesan'
以此为基础,我们要打印从‘a'到‘z'的所有字母,可以用以下的函数:
复制代码 代码如下:
function printChar(start,end){
var s = (start + '').charCodeAt()
var e = (end + '').charCodeAt();
if(s > e){
s = [e,e=s][0];
}
for(var i = s ;i console.log(String.fromCharCode(i));
}
}
printChar('a','z');
复制代码 代码如下:
function times(count) {
return count }
times作用是重复整个字符串,其主要思想就是将当前字符作为数组的连接符调用join来获得预期结果。当然用循环添加也可以,不过没这么简洁。
如果要重复字符串里面的每个字符,可以用相同的思想:
复制代码 代码如下:
String.prototype.letterTimes = function(count){
var arr = [];
arr.length = count + 1;
return this.replace(/\w/g,function(a){
return arr.join(a);
})
}
console.log('xesam'.letterTimes(3));//xxxeeesssaaammm
camelize | capitalize | underscore | dasherize这四个主要是关于变量名转换的。
camelize : 将一个用横线分隔的字符串转换为 Camel 形式
capitalize :将一个字符串的首字母转换为大写,其它的字母全部转为小写。
underscore :将一个 Camel 形式的字符串转换为以下划线("_")分隔的一系列单词。
dasherize :将字符串中的下划线全部替换为横线("_" 替换为 "-")。
最明显的,可以用在CSS属性与DOM的style属性的相互转换中【class与float不属于此范畴】。对应到上面的方法中,将CSS属性转换为对应的DOM的style属性可以使用camelize 方法,但是反过来却没有这个方法,因此必须连续调用underscore -> dasherize 方法才行。
复制代码 代码如下:
function camelize() {
return this.replace(/-+(.)?/g, function(match, chr) {
return chr ? chr.toUpperCase() : '';
});
}
核心是replace方法的使用,其他挺简单,参见《浅析字符串的replace方法应用》
复制代码 代码如下:
function capitalize() {
return this.charAt(0).toUpperCase() + this.substring(1).toLowerCase();
}
这里注意charAt(charAt() 方法可返回指定位置的字符。)与charCodeAt的区别就可以了。
复制代码 代码如下:
function underscore() {
return this.replace(/::/g, '/')
.replace(/([A-Z]+)([A-Z][a-z])/g, '$1_$2')
.replace(/([a-z\d])([A-Z])/g, '$1_$2')
.replace(/-/g, '_')
.toLowerCase();
}
实例来说明步骤:
复制代码 代码如下:
'helloWorld::ABCDefg'.underscore()
//'helloWorld::ABCDefg'
.replace(/::/g, '/') //'helloWorld/ABCDefg'
.replace(/([A-Z]+)([A-Z][a-z])/g, '$1_$2')//helloWorld/ABC_Defg
.replace(/([a-z\d])([A-Z])/g, '$1_$2') //hello_World/ABC_Defg
.replace(/-/g, '_') //hello_World/ABC_Defg
.toLowerCase(); //hello_world/abc_defg
这个方法只适合Camel 形式的,就是得有‘峰'。
复制代码 代码如下:
function dasherize() {
return this.replace(/_/g, '-');
}
这个就是单纯的字符替换而已。
来自小西山子
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:深入理解JavaScript系列(3) 全面解析Module模式_javascript技巧Nächster Artikel:深入理解JavaScript系列(2) 揭秘命名函数表达式_javascript技巧
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse