


前面each方法中掉了一个方面没有说,就是源码中的$break和$continue。这两个变量是预定义的,其作用相当于普通循环里面的break和continue语句的作用。出于效率的考虑,在某些操作中并不需要完全遍历一个集合(不局限于一个数组),所以break和continue还是很必要的。
对于一个循环来说,对比下面几种退出循环的方式:
var array_1 = [1,2,3];
var array_2 = ['a','b','c'];
(function(){
for(var i = 0, len = array_1.length; i for(var j = 0, len_j = array_1.length; i if('c' === array_2[j]){
break;
}
console.log(array_2[j]);
}
}
})();//a,b,a,b,a,b
(function(){
for(var i = 0, len = array_1.length; i try{
for(var j = 0, len_j = array_1.length; i if('c' === array_2[j]){
throw new Error();
}
console.log(array_2[j]);
}
}catch(e){
console.log('退出一层循环');
}
}
})();//a,b,'退出一层循环',a,b,'退出一层循环',a,b,'退出一层循环'
(function(){
try{
for(var i = 0, len = array_1.length; i for(var j = 0, len_j = array_1.length; i if('c' === array_2[j]){
throw new Error();
}
console.log(array_2[j]);
}
}
}catch(e){
console.log('退出一层循环');
}
})();//a,b,'退出一层循环'
当我们把错误捕获放在相应的循环层面时,就可以中断相应的循环。可以实现break和break label的作用(goto)。这样的一个应用需求就是可以把中断挪到外部去,恰好符合Enumerable处的需求。
回到Enumerable上来,由于each(each = function(iterator, context){})方法的本质就是一个循环,对于其第一个参数iterator,并不包含循环,因此直接调用break语句会报语法错误,于是Prototype源码中采用上面的第二种方法。
Enumerable.each = function(iterator, context) {
var index = 0;
try{
this._each(function(value){
iterator.call(context, value, index++);
});
}catch(e){
if(e != $break){
throw e;
}
}
return this;
};
一旦iterator执行中抛出一个$break,那么循环就中断。如果不是$break,那么就抛出相应错误,程序也稳定点。这里的$break的定义并没有特殊要求,可以按照自己的喜好随便更改,不过意义不大。
Enumerable中的某些方法在一些现代浏览器里面已经实现了(参见chrome原生方法之数组),下面是一张对比图:
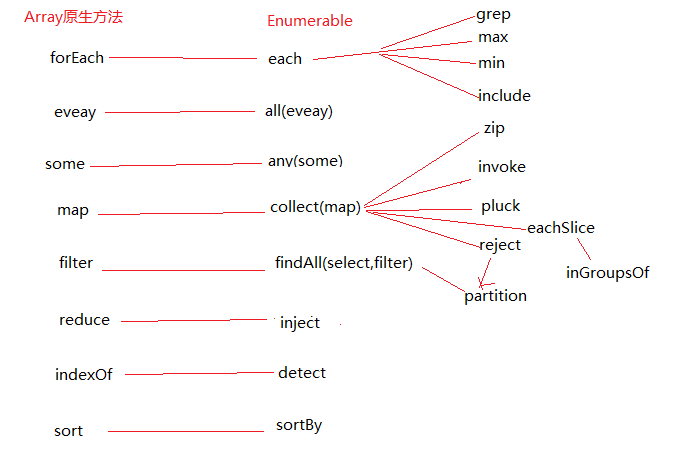
在实现这些方法时,可以借用原生方法,从而提高效率。不过源码中并没有借用原生的部分,大概是因为Enumerable除了混入Array部分外,还需要混入其他的对象中。
看上面的图示明显可以看得出,each和map 的重要性,map其实本质还是each,只不过each是依次处理集合的每一项,map是在each的基础上,还把处理后的结果返回来。在Enumerable内部,map是collect方法的一个别名,另一个别名是select,其内部全部使用的是collect这个名字。
检测:all | any | include
这三个方法不涉及对原集合的处理,返回值均是boolean类型。
all : 若 Enumerable 中的元素全部等价于 true,则返回 true,否则返回 false
function all(iterator, context) {
var result = true;
this.each(function(value, index) {
result = result && !!iterator.call(context, value, index);
});
return result;
}
对于all方法来说,里面的两个参数都不是必须的,所以,内部提供了一个函数,以代替没有实参时的iterator,直接返回原值,名字叫做Prototype.K。Prototype.K的定义在库的开头,是一个返回参数值的函数Prototype.K = function(x){return x;}。另外,在all方法中,只要有一个项的处理结果为false,整个过程就可以放弃(break)了,于是用到了本文开头的中断循环的方法。最后的形式就是:
Prototype.K = function(){};
Enumerable.all = function(iterator, context) {
iterator = iterator || Prototype.K;
var result = true;
this.each(function(value, index) {
result = result && !!iterator.call(context, value, index);
if (!result) throw $break;
});
return result;
}
最后返回的result是一个boolean型,偏离一下all,我们改一下result:
function collect(iterator, context) {
iterator = iterator || Prototype.K;
var results = [];
this.each(function(value, index) {
results.push(iterator.call(context, value, index));
});
return results;
}
此时results是一个数组,我们不中断处理过程,保存所有的结果并返回,恩,这就是collect方法,或者叫做map方法。
any:若 Enumerable 中的元素有一个或多个等价于 true,则返回 true,否则返回 false,其原理和all差不多,all是发现false就收工,any是发现true就收工。
function any(iterator, context) {
iterator = iterator || Prototype.K;
var result = false;
this.each(function(value, index) {
if (result = !!iterator.call(context, value, index))
throw $break;
});
return result;
}
include:判断 Enumerable 中是否存在指定的对象,基于 == 操作符进行比较 这个方法有一步优化,就是调用了indexOf方法,对于数组来说,indexOf返回-1就不可以知道相应元素不存在了,如果集合没有indexOf方法,就只能查找比对了。这里的查找和没有任何算法,一个个遍历而已,如果要改写也容易,不过平时应用不多,因此估计也没有花这个精力去优化这个。所以如果结果为true的时候效率比结果为false的时候要高一些,看运气了。
function include(object) {
if (Object.isFunction(this.indexOf))//这个判定函数应该很熟悉了
if (this.indexOf(object) != -1) return true;//有indexOf就直接调用
var found = false;
this.each(function(value) {//这里的效率问题
if (value == object) {
found = true;
throw $break;
}
});
return found;
}
下面是一组过滤数据的方法:返回单个元素:max | min | detect返回一个数组:grep | findAll | reject | partition 其中max和min并不局限于数字的比较,字符的比较一样可以。max(iterator, context)依旧可以带有两个参数,可以先用iterator处理之后再来比较值,这样的好处就是不必局限于特定的数据类型,比如,对象数组按照一定规则取最大值:
console.dir([{value : 3},{value : 1},{value : 2}].max(function(item){
return item.value;
}));//3
因此源码的实现方式可以想象,直接比较的时候,实现方式可以如下:
function max() {
var result;
this.each(function(value) {
if (result == null || value >= result) //result==null是第一次比较
result = value;
});
return result;
}
扩展之后,value要进一步变为value = (iterator处理后的返回值):
function max(iterator, context) {
iterator = iterator || Prototype.K;
var result;
this.each(function(value, index) {
value = iterator.call(context, value, index);
if (result == null || value >= result)
result = value;
});
return result;
}
min的原理也一样。detect和any的原理和接近,any是找到一个true就返回true,detect是找到一个true就返回满足true条件的那个值。源码就不贴了。grep 这个很眼熟啊,一个unix/linux工具,其作用也很眼熟——就是返回所有和指定的正则表达式匹配的元素。只不过unix/linux只能处理字符串,这里扩展了范围,但是基本形式还是没有变。如果集合的每一项都是字符串,那么实现起来回事这样:
Enumerable.grep = function(filter) {
if(typeof filter == 'string'){
filter = new RegExp(filter);
}
var results = [];
this.each(function(value,index){
if(value.match(filter)){
results.push(value);
}
})
return results;
};
但是有一现在要处理的集合可能并都是字符串,为了达到更广泛的应用,首先要考虑的就是调用形式。看上面的实现,注意这么一句:
if(value.match(filter))
其中value是个字符串,match是String的方法,现在要扩展所支持的类型,要么给每一个value都加上match方法,要么转换形式。显然第一种巨响太大,作者转换了思路:
if (filter.match(value))
这么一来,不论value为何值,只要filter有对应的match方法即可,上面对于RegExp对象,是没有match方法的,于是在源码中,作者扩展了RegExp对象:
RegExp.prototype.match = RegExp.prototype.test;
注意上面的match和String的match有本质区别。这么一来,如果value是对象,我们的filter只需要提供相应的检测对象的match方法即可。于是就有:
function grep(filter, iterator, context) {
iterator = iterator || Prototype.K;
var results = [];
if (Object.isString(filter))
filter = new RegExp(RegExp.escape(filter));
this.each(function(value, index) {
if (filter.match(value))//原生filter是没有match方法的。
results.push(iterator.call(context, value, index));
});
return results;
}
对于匹配的结果,可以处理之后再返回,这就是iterator参数的作用。不同于max方法,grep是进行主要操作时候再用iterator来处理结果,max是用iterator处理源数据之后再来进行主要操作。因为grep中的filter代替了max中iterator的作用。至于findAll,是grep的加强版,看过grep,findAll就很简单了。reject就是findAll的双子版本,作用正好相反。partition就是findAll + reject,组合亲子版本。转载请注明来自小西山子【http://www.cnblogs.com/xesam/】

 Jenseits des Browsers: JavaScript in der realen WeltApr 12, 2025 am 12:06 AM
Jenseits des Browsers: JavaScript in der realen WeltApr 12, 2025 am 12:06 AMZu den Anwendungen von JavaScript in der realen Welt gehören die serverseitige Programmierung, die Entwicklung mobiler Anwendungen und das Internet der Dinge. Die serverseitige Programmierung wird über node.js realisiert, die für die hohe gleichzeitige Anfrageverarbeitung geeignet sind. 2. Die Entwicklung der mobilen Anwendungen erfolgt durch reaktnative und unterstützt die plattformübergreifende Bereitstellung. 3.. Wird für die Steuerung von IoT-Geräten über die Johnny-Five-Bibliothek verwendet, geeignet für Hardware-Interaktion.
 Erstellen einer SaaS-Anwendung mit mehreren Mietern mit Next.js (Backend Integration)Apr 11, 2025 am 08:23 AM
Erstellen einer SaaS-Anwendung mit mehreren Mietern mit Next.js (Backend Integration)Apr 11, 2025 am 08:23 AMIch habe eine funktionale SaaS-Anwendung mit mehreren Mandanten (eine EdTech-App) mit Ihrem täglichen Tech-Tool erstellt und Sie können dasselbe tun. Was ist eine SaaS-Anwendung mit mehreren Mietern? Mit Multi-Tenant-SaaS-Anwendungen können Sie mehrere Kunden aus einem Sing bedienen
 So erstellen Sie eine SaaS-Anwendung mit mehreren Mietern mit Next.js (Frontend Integration)Apr 11, 2025 am 08:22 AM
So erstellen Sie eine SaaS-Anwendung mit mehreren Mietern mit Next.js (Frontend Integration)Apr 11, 2025 am 08:22 AMDieser Artikel zeigt die Frontend -Integration mit einem Backend, das durch die Genehmigung gesichert ist und eine funktionale edtech SaaS -Anwendung unter Verwendung von Next.js. erstellt. Die Frontend erfasst Benutzerberechtigungen zur Steuerung der UI-Sichtbarkeit und stellt sicher, dass API-Anfragen die Rollenbasis einhalten
 JavaScript: Erforschung der Vielseitigkeit einer WebspracheApr 11, 2025 am 12:01 AM
JavaScript: Erforschung der Vielseitigkeit einer WebspracheApr 11, 2025 am 12:01 AMJavaScript ist die Kernsprache der modernen Webentwicklung und wird für seine Vielfalt und Flexibilität häufig verwendet. 1) Front-End-Entwicklung: Erstellen Sie dynamische Webseiten und einseitige Anwendungen durch DOM-Operationen und moderne Rahmenbedingungen (wie React, Vue.js, Angular). 2) Serverseitige Entwicklung: Node.js verwendet ein nicht blockierendes E/A-Modell, um hohe Parallelitäts- und Echtzeitanwendungen zu verarbeiten. 3) Entwicklung von Mobil- und Desktop-Anwendungen: Die plattformübergreifende Entwicklung wird durch reaktnative und elektronen zur Verbesserung der Entwicklungseffizienz realisiert.
 Die Entwicklung von JavaScript: Aktuelle Trends und ZukunftsaussichtenApr 10, 2025 am 09:33 AM
Die Entwicklung von JavaScript: Aktuelle Trends und ZukunftsaussichtenApr 10, 2025 am 09:33 AMZu den neuesten Trends im JavaScript gehören der Aufstieg von Typenkripten, die Popularität moderner Frameworks und Bibliotheken und die Anwendung der WebAssembly. Zukunftsaussichten umfassen leistungsfähigere Typsysteme, die Entwicklung des serverseitigen JavaScript, die Erweiterung der künstlichen Intelligenz und des maschinellen Lernens sowie das Potenzial von IoT und Edge Computing.
 Entmystifizieren JavaScript: Was es tut und warum es wichtig istApr 09, 2025 am 12:07 AM
Entmystifizieren JavaScript: Was es tut und warum es wichtig istApr 09, 2025 am 12:07 AMJavaScript ist der Eckpfeiler der modernen Webentwicklung. Zu den Hauptfunktionen gehören eine ereignisorientierte Programmierung, die Erzeugung der dynamischen Inhalte und die asynchrone Programmierung. 1) Ereignisgesteuerte Programmierung ermöglicht es Webseiten, sich dynamisch entsprechend den Benutzeroperationen zu ändern. 2) Die dynamische Inhaltsgenerierung ermöglicht die Anpassung der Seiteninhalte gemäß den Bedingungen. 3) Asynchrone Programmierung stellt sicher, dass die Benutzeroberfläche nicht blockiert ist. JavaScript wird häufig in der Webinteraktion, der einseitigen Anwendung und der serverseitigen Entwicklung verwendet, wodurch die Flexibilität der Benutzererfahrung und die plattformübergreifende Entwicklung erheblich verbessert wird.
 Ist Python oder JavaScript besser?Apr 06, 2025 am 12:14 AM
Ist Python oder JavaScript besser?Apr 06, 2025 am 12:14 AMPython eignet sich besser für Datenwissenschaft und maschinelles Lernen, während JavaScript besser für die Entwicklung von Front-End- und Vollstapel geeignet ist. 1. Python ist bekannt für seine prägnante Syntax- und Rich -Bibliotheks -Ökosystems und ist für die Datenanalyse und die Webentwicklung geeignet. 2. JavaScript ist der Kern der Front-End-Entwicklung. Node.js unterstützt die serverseitige Programmierung und eignet sich für die Entwicklung der Vollstapel.
 Wie installiere ich JavaScript?Apr 05, 2025 am 12:16 AM
Wie installiere ich JavaScript?Apr 05, 2025 am 12:16 AMJavaScript erfordert keine Installation, da es bereits in moderne Browser integriert ist. Sie benötigen nur einen Texteditor und einen Browser, um loszulegen. 1) Führen Sie sie in der Browser -Umgebung durch, indem Sie die HTML -Datei durch Tags einbetten. 2) Führen Sie die JavaScript -Datei nach dem Herunterladen und Installieren von node.js nach dem Herunterladen und Installieren der Befehlszeile aus.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

