
 Technologie-PeripheriegeräteKIErstellen eines QA -Modells mit universellem Satz Encoder und Wikiqa
Technologie-PeripheriegeräteKIErstellen eines QA -Modells mit universellem Satz Encoder und Wikiqa
Nutzung der Macht der Einbettung von Modellen für die Beantwortung fortgeschrittener Frage
In der heutigen informationsreichen Welt ist die Fähigkeit, genaue Antworten sofort zu erhalten, von größter Bedeutung. Dieser Artikel zeigt, dass das Erstellen eines robusten Fragen-Answering-Modells (QA) unter Verwendung des Universal-Satz-Encoders (Verwendung) und des Wikiqa-Datensatzes erstellt wird. Wir nutzen fortgeschrittene Einbettungstechniken, um die Lücke zwischen menschlicher Untersuchung und Maschinenverständnis zu überbrücken und eine intuitivere Informationsabruferfahrung zu schaffen.
Wichtige Lernergebnisse:
- Beherrschen Sie die Anwendung von Einbettungsmodellen wie verwendet, um Textdaten in hochdimensionale Vektordarstellungen umzuwandeln.
- Navigieren Sie durch die Komplexität der Auswahl und Feinabstimmung vorgebliebene Modelle für eine optimale Leistung.
- Implementieren Sie ein funktionales QA -System unter Verwendung von Einbettungsmodellen und Cosinus -Ähnlichkeit anhand praktischer Codierungsbeispiele.
- Erfassen Sie die zugrunde liegenden Prinzipien der Ähnlichkeit der Cosinus und ihre Rolle beim Vergleich des vektorisierten Textes.
(Dieser Artikel ist Teil des Data Science -Blogathons.)
Inhaltsverzeichnis:
- Einbetten von Modellen in NLP
- Verständnis der Einbettung von Darstellungen
- Semantische Ähnlichkeit: Erfassen von Textbedeutungen
- Nutzung des universellen Satz Encoder
- Aufbau eines Frage-Antwort-Generators
- Vorteile von Einbettungsmodellen in NLP
- Herausforderungen in der Entwicklung des QA -Systems
- Häufig gestellte Fragen
Einbetten von Modellen in die natürliche Sprachverarbeitung
Wir verwenden Einbettungsmodelle, einen Eckpfeiler des modernen NLP. Diese Modelle übersetzen Text in numerische Formate, die die semantische Bedeutung widerspiegeln. Wörter, Phrasen oder Sätze werden in numerische Vektoren (Einbettungen) umgewandelt, um Algorithmen auf raffinierte Weise zu verarbeiten und zu verstehen.
Verständnis der Einbettungsmodelle
Worteinbettungen repräsentieren Wörter als dichte numerische Vektoren, bei denen semantisch ähnliche Wörter ähnliche Vektor -Darstellungen aufweisen. Anstatt diese Codierungen manuell zuzuweisen, lernt das Modell sie während des Trainings als trainierbare Parameter. Die Einbettungsdimensionen variieren (z. B. 300 bis 1024), wobei höhere Dimensionen nuanciertere semantische Beziehungen aufnehmen. Stellen Sie sich Einbettungen als "Lookup -Tabelle" vor, die den Vektor jedes Wortes für effiziente Codierung und Abruf speichert.

Semantische Ähnlichkeit: Bedeutung quantifizieren
Die semantische Ähnlichkeit misst, wie eng zwei Textsegmente die gleiche Bedeutung vermitteln. Diese Fähigkeit ermöglicht es Systemen, verschiedene sprachliche Ausdrücke desselben Konzepts ohne explizite Definitionen für jede Variation zu verstehen.

Universeller Satzcodierer für eine verbesserte Textverarbeitung
Dieses Projekt verwendet den Universal Sätze Encoder (Verwendung), das hochdimensionale Vektoren aus Text erzeugt, ideal für Aufgaben wie semantische Ähnlichkeit und Textklassifizierung. Optimiert für längere Textsequenzen wird die Verwendung auf verschiedenen Datensätzen geschult und passt gut an verschiedene NLP -Aufgaben an. Es gibt für jeden Eingangssatz einen 512-dimensionalen Vektor aus.
Beispiel für die Einbettung der Generierung verwendet: Verwendung:
! PIP Installieren Sie TensorFlow Tensorflow-Hub
Tensorflow als TF importieren
TensorFlow_Hub als Hub importieren
Einbett = hub.load ("https://tfhub.dev/google/universal-stence-coder/4")
Sätze = [
"Der schnelle braune Fuchs springt über den faulen Hund."
"Ich bin ein Satz, für den ich seine Einbettung bekommen möchte"
]
Einbettungen = Einbettung (Sätze)
drucken (Einbettung)
drucken (embettdings.numpy ())
Ausgabe:

Verwendung verwendet eine tiefgründige Mittelwerte (Dan) -Architektur, die sich eher auf Satzebene als auf einzelne Wörter konzentriert. Ausführliche Informationen finden Sie in der Einbettungsdokumentation von Papier und TensorFlow. Das Modul behandelt die Vorverarbeitung und beseitigt die Bedarf an manueller Datenvorbereitung.


Das Verwendungsmodell ist teilweise für die Textklassifizierung vorbereitet, wodurch es mit minimal beschrifteten Daten an verschiedene Klassifizierungsaufgaben anpassbar ist.
Implementierung eines Fragen-Antworter-Generators
Wir verwenden den Wikiqa -Datensatz für diese Implementierung.
Pandas als PD importieren
TensorFlow_Hub als Hub importieren
Numph als NP importieren
von sklearn.metrics
# Dataset laden (Pfad nach Bedarf anpassen)
df = pd.read_csv ('/content/train.csv')
Fragen = df ['Frage']. Tolist ()
Antworten = df ['Antwort']. Tolist ()
# Universal -Satz -Encoder laden
Einbett = hub.load ("https://tfhub.dev/google/universal-stence-coder/4")
# Einbettungen berechnen
FRAGE_EMBEDDINGS = Einbettung (Fragen)
Antwort_embeddings = Einbett (Antworten)
# Ähnlichkeitswerte berechnen
Ähnlichkeit_Scores = Cosine_similarity (Frage_embeding, Antwort_embeddings)
# Antworten vorhersagen
Predicted_indices = np.argmax (Ähnlichkeit_Scores, Axis = 1)
Vorhersagen = [Antworten [IDX] für IDX in Predicted_indices]
# Fragen und vorhergesagte Antworten drucken
Für mich, Frage in Aufzählung (Fragen):
print (f "Frage: {Frage}")
print (f "vorhergesagte Antwort: {Vorhersagen [i]} \ n")

Der Code wird geändert, um benutzerdefinierte Fragen zu bearbeiten, die ähnlichste Frage aus dem Datensatz zu identifizieren und seine entsprechende Antwort zurückzugeben.
Def Ask_Question (New_Question):
new_question_embedding = einbett ([new_question])
yesineity_scores = Cosine_similarity (new_question_embedding, Frage_embeddings)
Most_simailar_Question_idx = np.argmax (Ähnlichkeit_Scores)
meist_simailar_Question = Fragen [Most_similar_Question_idx]
Predicted_answer = Answers [Most_simailar_Question_idx]
RECHT MELD_SIMILILE_QUESTION, PHODICATED_ANSWER
# Beispielnutzung
new_question = "Wann wurde Apple Computer gegründet?"
meist_simailar_Question, vorhergesagt_answer = Ask_Question (new_question)
print (f "neue Frage: {new_question}")
print (f "die ähnliche Frage: {Most_similar_Question}")
print (f "vorhergesagte Antwort: {Predicated_answer}"))
Ausgabe:

Vorteile von Einbettungsmodellen in NLP
- Vorausgebildete Modelle wie Verwendung reduzieren die Trainingszeit und Rechenressourcen.
- Erfassen Sie semantische Ähnlichkeit, passende Paraphrasen und Synonyme.
- Unterstützen Sie mehrsprachige Fähigkeiten.
- Vereinfachen Sie Feature Engineering für maschinelles Lernen.
Herausforderungen in der Entwicklung des QA -Systems
- Modellauswahl und Parameterabstimmung.
- Effizienter Umgang mit großen Datensätzen.
- Nuancen und kontextbezogene Unklarheiten in der Sprache.
Abschluss
Die Einbettungsmodelle verbessern die QA -Systeme erheblich, indem genaue Identifizierung und Abrufen relevanter Antworten ermöglicht werden. Dieser Ansatz zeigt die Kraft, Modelle bei der Verbesserung der Human-Computer-Wechselwirkung innerhalb von NLP-Aufgaben einzubetten.
Wichtigste Imbiss:
- Einbettungsmodelle bieten leistungsstarke Tools für die numerischste Darstellung von Text.
- Einbettungsbasierte QA-Systeme verbessern die Benutzererfahrung durch genaue Antworten.
- Die Herausforderungen sind semantische Mehrdeutigkeit, vielfältige Abfragetypen und Recheneffizienz.
Häufig gestellte Fragen
F1: Welche Rolle spielt die Einbettungsmodelle in QA -Systeme? A1: Das Einbetten von Modellen verwandeln Text in numerische Darstellungen und ermöglicht es, Systeme genau zu verstehen und auf Fragen zu reagieren.
F2: Wie gehen Einbettungssysteme mit mehreren Sprachen um? A2: Viele Einbettungsmodelle unterstützen mehrere Sprachen und erleichtern die Entwicklung mehrsprachiger QA -Systeme.
F3: Warum sind die Einbettungssysteme den traditionellen Methoden für die QA überlegen? A3: Einbettungssysteme zeichnen sich aus, um semantische Ähnlichkeit zu erfassen und verschiedene sprachliche Ausdrücke zu bewältigen.
F4: Welche Herausforderungen bestehen bei der Einbettungsbasis QA-Systeme? A4: Optimale Modellauswahl, Parameterabstimmung und effiziente groß angelegte Datenbearbeitung stellen erhebliche Herausforderungen dar.
F5: Wie verbessern die Einbettungsmodelle die Benutzerinteraktion in QA -Systemen? A5: Durch genaue Anpassung von Fragen zu Antworten, die auf semantischer Ähnlichkeit basieren, bieten Einbettungsmodelle relevantere und zufriedenstellendere Benutzererfahrungen.
(Hinweis: Die verwendeten Bilder sind nicht im Besitz des Autors und werden mit Genehmigung verwendet.)
Das obige ist der detaillierte Inhalt vonErstellen eines QA -Modells mit universellem Satz Encoder und Wikiqa. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

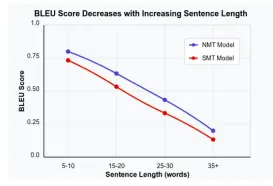 Bewertung von Sprachmodellen mit BLEU -MetrikApr 23, 2025 am 11:05 AM
Bewertung von Sprachmodellen mit BLEU -MetrikApr 23, 2025 am 11:05 AMBewertung von Sprachmodellen: Ein tiefes Eintauchen in die Bleu -Metrik und darüber hinaus Im Bereich der künstlichen Intelligenz stellt die Beurteilung der Leistung von Sprachmodellen eine einzigartige Herausforderung. Im Gegensatz zu Aufgaben wie Bilderkennung oder numerischen Vorhersage, ev
 Erforschen der Autogen -Framework von Microsoft für den Agenten -WorkflowApr 23, 2025 am 10:59 AM
Erforschen der Autogen -Framework von Microsoft für den Agenten -WorkflowApr 23, 2025 am 10:59 AMDer schnelle Fortschritt von Generative AI erfordert eine Verschiebung von menschlichgetriebenen Aufforderung zur autonomen Aufgabenausführung. Hier kommen agierische Workflows und KI
 Bauen Sie einen Audio-Lappen mit Assemblyai, Qdrant & Deepseek-R1Apr 23, 2025 am 10:48 AM
Bauen Sie einen Audio-Lappen mit Assemblyai, Qdrant & Deepseek-R1Apr 23, 2025 am 10:48 AMDieser Leitfaden zeigt, dass ein KI-angetanter Chatbot erstellt wird, der Audioaufnahmen (Besprechungen, Podcasts, Interviews) in interaktive Gespräche verwandelt. Es nutzt Assemblyai für Transkription, QDrant für eine effiziente Datenspeicherung und Deepseek-R1 VI
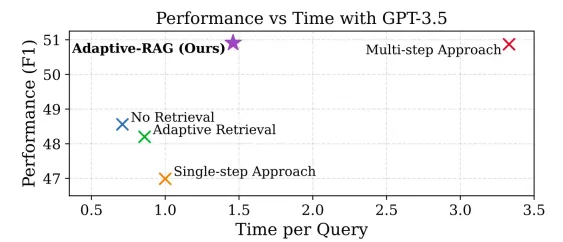 Leitfaden für adaptive Lappensysteme mit LanggraphApr 23, 2025 am 10:45 AM
Leitfaden für adaptive Lappensysteme mit LanggraphApr 23, 2025 am 10:45 AMAdaptiver Lappen: Ein klügerer Ansatz zur Beantwortung der Frage Großsprachige Modelle (LLMs) zeichnen sich durch die Beantwortung von Fragen anhand ihrer Schulungsdaten aus. Diese festgelegte Wissensbasis begrenzt jedoch ihre Fähigkeit, aktuelle oder hochspezifische Informationen bereitzustellen. Retri
 Top 5 RAG -Frameworks für AI -AnwendungenApr 23, 2025 am 10:39 AM
Top 5 RAG -Frameworks für AI -AnwendungenApr 23, 2025 am 10:39 AMRag ist im Jahr 2025 zu einer beliebten Technologie geworden. Sie vermeidet die Feinabstimmung des Modells, das sowohl teuer als auch zeitaufwändig ist. Im aktuellen Szenario gibt es eine erhöhte Nachfrage nach RAG -Frameworks. Lassen Sie uns verstehen, was th ist
 Rolle vollständig Faltungsnetzwerke in der semantischen SegmentierungApr 23, 2025 am 10:37 AM
Rolle vollständig Faltungsnetzwerke in der semantischen SegmentierungApr 23, 2025 am 10:37 AMVollständige Faltungsnetzwerke (FCNs): Ein tiefes Eintauchen in die semantische Segmentierung Die semantische Segmentierung, die pixelweise Klassifizierung von Bildern, ist ein Eckpfeiler des Computer Vision. 2015 ein bahnbrechendes Papier von Jonathan Long, Evan Shelhamer und Tr
 OpenAI -Audiomodelle: Sozugriff, Anwendungen und mehrApr 23, 2025 am 10:34 AM
OpenAI -Audiomodelle: Sozugriff, Anwendungen und mehrApr 23, 2025 am 10:34 AMOpenAIs Audiomodelle der nächsten Generation: revolutionäre sprachfähige Anwendungen OpenAI hat eine neue Generation von Audiomodellen auf den Markt gebracht und die Fähigkeiten von Sprachanwendungen erheblich gesteigert. Diese Suite beinhaltet erweiterte Sprache zu Text (STT)
 Wie man einen Dream11 -Agenten für IPL 2025 bautApr 23, 2025 am 10:33 AM
Wie man einen Dream11 -Agenten für IPL 2025 bautApr 23, 2025 am 10:33 AMDie indische Premier League (IPL) ist mehr als ein Turnier; Es ist ein High-Stakes-Cricket-Spektakel! Dream11 verstärkt die Aufregung und ermöglicht es Ihnen, Ihr ultimatives Fantasy -Team herzustellen. Eine einzige schlechte Wahl kann jedoch Ihre Bestrebungen schnell entgleisen.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

