



Einführung
Großsprachenmodelle (LLMs) trugen zum Fortschritt der natürlichen Sprachverarbeitung (NLP) bei, stellten jedoch auch einige wichtige Fragen zur Recheneffizienz auf. Diese Modelle sind zu groß geworden, sodass die Trainings- und Inferenzkosten nicht mehr innerhalb von angemessenen Grenzen liegen.
Um dies anzugehen, wurde das von Hoffmann et al. Im Jahr 2022 bietet ein bahnbrechender Rahmen für die Optimierung des Trainings von LLMs. Das Chinchilla Scaling Law bietet einen wesentlichen Leitfaden zur effizienten Skalierung von LLMs, ohne die Leistung zu beeinträchtigen, indem Beziehungen zwischen Modellgröße, Trainingsdaten und Rechenressourcen hergestellt werden. Wir werden es in diesem Artikel ausführlich besprechen.

Überblick
- Das Chinchilla Scaling Law optimiert das LLM -Training, indem das Modell der Modellgröße und des Datenvolumens für eine verbesserte Effizienz ausgeglichen wird.
- Neue skalierende Erkenntnisse deuten darauf hin, dass kleinere Sprachmodelle wie Chinchilla größere übertreffen können, wenn sie auf mehr Daten trainiert werden.
- Der Ansatz von Chinchilla fordert die traditionelle LLM -Skalierung durch, indem er die Datenmenge gegenüber der Modellgröße für die Berechnungseffizienz priorisiert.
- Das Chinchilla Scaling Law bietet eine neue Roadmap für NLP und leitet die Entwicklung leistungsfähiger, ressourceneffizienter Modelle.
- Das Chinchilla Scaling Law maximiert die Sprachmodellleistung mit minimalen Berechnungskosten, indem die Modellgröße und die Schulungsdaten verdoppelt werden.
Inhaltsverzeichnis
- Was ist Chinchilla Scaling Law?
- Eine Verschiebung im Fokus: von Modellgröße zu Daten
- Überblick über das Chinchilla Scaling Law
- Wichtige Ergebnisse des Chinchilla Scaling Law
- Berechnen optimales Training
- Empirische Beweise aus über 400 Modellen
- Überarbeitete Schätzungen und kontinuierliche Verbesserung
- Vorteile des Chinchilla -Ansatzes
- Verbesserte Leistung
- Niedrigere Rechenkosten
- Implikationen für zukünftige Forschungs- und Modellentwicklung
- Herausforderungen und Überlegungen
- Häufig gestellte Fragen
Was ist Chinchilla Scaling Law?
Das Papier „Trainingsberechnung optimale Großsprachenmodelle“, das 2022 veröffentlicht wurde, konzentriert sich auf die Identifizierung der Beziehung zwischen drei Schlüsselfaktoren: Modellgröße, Anzahl der Token und Berechnung des Budgets. Die Autoren fanden heraus, dass vorhandene Großsprachmodelle (LLMs) wie GPT-3 (175B-Parameter), Gopher (280b) und Megatron (530b) signifikant untergraben sind. Während diese Modelle an Größe zunahmen, blieb die Menge der Trainingsdaten weitgehend konstant, was zu einer suboptimalen Leistung führte. Die Autoren schlagen vor, dass die Modellgröße und die Anzahl der Trainingstoken gleichermaßen skaliert werden müssen, um rechenoptimal zu trainieren. Um dies zu beweisen, bildeten sie rund 400 Modelle aus, die zwischen 70 Millionen und über 16 Milliarden Parametern lagen und zwischen 5 und 500 Milliarden Token.
Basierend auf diesen Ergebnissen trainierten die Autoren ein neues Modell namens Chinchilla, das das gleiche Rechenbudget wie Gopher (280b) verwendet, jedoch nur 70B -Parameter und viermal mehr Trainingsdaten. Chinchilla übertraf mehrere bekannte LLMs, darunter Gopher (280b), GPT-3 (175b), Jurassic-1 (178b) und Megatron (530b). Dieses Ergebnis widerspricht den von OpenAI in „Skalierungsgesetzen für LLMs“ vorgeschlagenen Skalierungsgesetze, die darauf hinwiesen, dass größere Modelle immer besser abschneiden würden. Die Chinchilla -Skalierungsgesetze zeigen, dass kleinere Modelle, wenn sie auf mehr Daten geschult sind, eine überlegene Leistung erzielen können. Dieser Ansatz erleichtert auch kleinere Modelle, die eine Feinabstimmung leichter zu stimmen und die Inferenzlatenz zu verringern.
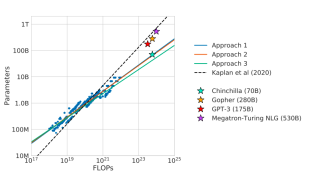
Die Grafik zeigt, dass Chinchilla (70B), obwohl er kleiner ist, einem anderen Verhältnis von Compute zu Parameter folgt und größere Modelle wie Gopher und GPT-3 übertrifft.
Die anderen Ansätze (1, 2 und 3) untersuchen verschiedene Möglichkeiten zur Optimierung der Modellleistung basierend auf der Rechenzuweisung.
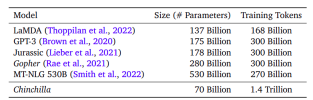
Aus dieser Abbildung können wir den Vorteil von Chinchilla sehen, obwohl Chinchilla kleiner ist (70B-Parameter), es wurde auf einem viel größeren Datensatz (1,4 Billionen Token) trainiert, was dem Prinzip folgt, das in den Chinchilla-Skalierungsgesetzen eingeführt wurde. wurden auf relativ weniger Token geschult, was darauf hindeutet, dass diese Modelle ihr Rechenpotential möglicherweise nicht vollständig optimiert haben.
Eine Verschiebung im Fokus: von Modellgröße zu Daten
In der Vergangenheit lag der Fokus auf die Verbesserung der LLM-Leistung auf der zunehmenden Modellgröße, wie in Modellen wie GPT-3 und Gopher zu sehen ist. Dies wurde durch die Forschung von Kaplan et al. (2020), die eine Potenzgesetzbeziehung zwischen Modellgröße und Leistung vorschlug. Als die Modelle jedoch größer wurden, wurde die Menge der Trainingsdaten nicht entsprechend skaliert, was zu einem nicht genutzten Berechnungspotential führte. Die Chinchilla Scaling Laws fordern dies in Frage, indem sie zeigen, dass eine ausgewogenere Allokation von Ressourcen, insbesondere in Bezug auf Daten und Modellgröße, zu rechenoptimalen Modellen führen kann, die besser abschneiden, ohne ihren niedrigsten Verlust zu erreichen.
Überblick über das Chinchilla Scaling Law
Der Kompromiss zwischen Modellgröße, Trainingstoken und Rechenkosten ist der Kern des Chinchilla-Skalierungsgesetzes. Das Gesetz legt ein rechenoptimales Gleichgewicht zwischen diesen drei Parametern fest:
- Modellgröße (N) : Die Anzahl der Parameter im Modell.
- Trainingstoken (D) : Die Gesamtzahl der während des Trainings verwendeten Token.
- Rechenkosten (C) : Die für das Training zugewiesenen Gesamtrechnung, die normalerweise in Flops gemessen wurden (schwimmende Punktvorgänge pro Sekunde).
Das Chinchilla Scaling Law legt nahe, dass sowohl die Modellgröße als auch die Anzahl der Trainingsdaten für eine optimale Leistung gleiche Raten skalieren sollten. Insbesondere sollte sich die Anzahl der Trainingstoken auch für jede Verdoppelung der Modellgröße verdoppeln. Dieser Ansatz kontrastiert frühere Methoden, die die zunehmende Modellgröße betonten, ohne die Trainingsdaten ausreichend zu erhöhen.
Diese Beziehung wird mathematisch ausgedrückt als:
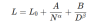
Wo:
- L ist der endgültige Verlust des Modells.
- L_0 ist der nicht reduzierbare Verlust, der die bestmögliche Leistung darstellt.
- A und B sind Konstanten, die die Unterperformance des Modells im Vergleich zu einem idealen generativen Prozess erfassen.
- α und β sind Exponenten, die beschreiben, wie Verlust in Bezug auf die Modellgröße bzw. der Datengröße skaliert werden.
Wichtige Ergebnisse des Chinchilla Scaling Law
Hier sind die wichtigsten Erkenntnisse des Chinchilla Scaling Law:
Berechnen optimales Training
Das Chinchilla Scaling Law beleuchtet ein optimales Gleichgewicht zwischen der Modellgröße und der Anzahl der Trainingsdaten. Insbesondere ergab die Studie, dass ein ungefähres Verhältnis von 20 Trainingstoken pro Modellparameter ideal ist, um die beste Leistung mit einem bestimmten Rechenbudget zu erzielen. Zum Beispiel wurde das Chinchilla -Modell mit 70 Milliarden Parametern auf 1,4 Billionen Token geschult - vier Mal mehr als Gopher, aber mit weitaus weniger Parametern. Dieses Gleichgewicht führte dazu, dass ein Modell größere Modelle an mehreren Benchmarks erheblich übertroffen hat.
Empirische Beweise aus über 400 Modellen
Hoffmann et al. über 400 Transformatormodelle mit einer Größe von 70 Millionen auf 16 Milliarden Parameter auf Datensätzen von bis zu 500 Milliarden Token. Die empirischen Erkenntnisse stützten die Hypothese stark, dass Modelle, die mit mehr Daten (bei einem festen Rechenbudget) trainiert wurden, besser abschneiden als nur die Modellgröße allein zu erhöhen.
Überarbeitete Schätzungen und kontinuierliche Verbesserung
Nachfolgende Untersuchungen haben versucht, die ersten Ergebnisse von Hoffmann et al. Zu verfeinern und mögliche Anpassungen in den Parameterschätzungen zu identifizieren. Einige Studien haben kleinere Inkonsistenzen in den ursprünglichen Ergebnissen vorgeschlagen und überarbeitete Schätzungen vorgeschlagen, um den beobachteten Daten besser anzupassen. Diese Anpassungen zeigen, dass weitere Untersuchungen erforderlich sind, um die Dynamik der Modellskalierung vollständig zu verstehen, aber die Kerneinsichten des Chinchilla -Skalierungsgesetzes bleiben eine wertvolle Richtlinie.
Vorteile des Chinchilla -Ansatzes
Hier sind die Vorteile des Chinchilla -Ansatzes:
Verbesserte Leistung
Chinchillas gleiche Skalierung der Modellgröße und der Trainingsdaten führte zu bemerkenswerten Ergebnissen. Obwohl Chinchilla kleiner als viele andere große Modelle war, übertraf es GPT-3, Gopher und sogar das massive Megatron-Turing-NLG-Modell (530 Milliarden Parameter) auf verschiedenen Benchmarks. Zum Beispiel erreichte Chinchilla nach dem massiven Multitasking Language -Verständnis (MMLU) eine durchschnittliche Genauigkeit von 67,5%, was eine signifikante Verbesserung gegenüber Gopher 60%.
Niedrigere Rechenkosten
Der Chinchilla -Ansatz optimiert die Leistung und reduziert die Rechen- und Energiekosten für Schulungen und Inferenz. Trainingsmodelle wie GPT-3 und Gopher erfordern enorme Rechenressourcen, wodurch ihre Verwendung in realen Anwendungen unerschwinglich teuer ist. Im Gegensatz dazu führen die kleinere Modellgröße von Chinchilla und umfangreichere Trainingsdaten zu geringeren Rechenanforderungen für Feinabstimmungen und Inferenz, was es für nachgeschaltete Anwendungen zugänglicher macht.
Implikationen für zukünftige Forschungs- und Modellentwicklung
Die Chinchilla Scaling -Gesetze bieten wertvolle Einblicke in die Zukunft der LLM -Entwicklung. Zu den wichtigsten Auswirkungen gehören:
- Anleitungsmodelldesign: Verstehen Sie, wie die Modellgröße und die Schulungsdaten für die Modellierung von Modell in Einklang gebracht werden können, ermöglicht es Forschern und Entwicklern, fundiertere Entscheidungen beim Entwerfen neuer Modelle zu treffen. Durch die Einhaltung der im Chinchilla-Skalierungsgesetz beschriebenen Prinzipien können Entwickler sicherstellen, dass ihre Modelle sowohl recheneffizient als auch leistungsstark sind.
- Leitmodelldesign : Wissen über die Optimierung des Volumens und damit die Schulungsdaten über die Forschung und das Design der Modelle informiert. Innerhalb dieser Richtlinienskala wird die Entwicklung ihrer Ideen innerhalb breiter Definitionen hoher Effizienz ohne übermäßigen Verbrauch von Computerressourcen funktionieren.
- Leistungsoptimierung : Das Chinchilla Scaling Law bietet eine Roadmap zur Optimierung von LLMs. Durch die Konzentration auf die gleiche Skalierung können Entwickler die Fallstricke von großen Modellen untergräben und sicherstellen, dass Modelle für Trainings- und Inferenzaufgaben optimiert werden.
- Erkundung jenseits von Chinchilla : Mit fortgesetzter Forschung entstehen neue Strategien, um die Ideen des Chinchilla -Skalierungsgesetzes zu erweitern. Zum Beispiel untersuchen einige Forscher Möglichkeiten, ähnliche Leistungsniveaus mit weniger Rechenressourcen zu erreichen oder die Modellleistung in datenbeschränkten Umgebungen weiter zu verbessern. Diese Erkundungen führen wahrscheinlich zu noch effizienteren Trainingspipelines.
Herausforderungen und Überlegungen
Während das Chinchilla Scaling Law einen bedeutenden Schritt nach vorne beim Verständnis von LLM -Skalierung markiert, wirft es auch neue Fragen und Herausforderungen auf:
- Datenerfassung: Wie bei Chinchilla impliziert das Training eines Modells mit 1,4 Billionen Token die Verfügbarkeit vieler hochwertiger Datensätze. Ein solches Ausmaß der Datenerfassung und -verarbeitung wirft jedoch organisatorische Probleme für Forscher und Entwickler sowie ethische Probleme wie Privatsphäre und Voreingenommenheit auf.
- Verzerrung und Toxizität: Die proportionale Verringerung der regelmäßigen Verzerrung und die Toxizität eines mit dem Chinchilla -Skalierungsgesetz geschultes Modells ist jedoch einfacher und effizienter als alle diese Ineffizienzprobleme. Wenn die LLM an Macht und Reichweite wächst, werden die Fairness und die mildernden schädlichen Ergebnisse entscheidende Fokusbereiche für zukünftige Forschungsergebnisse sein.
Abschluss
Das Chinchilla Scaling Law stellt einen entscheidenden Fortschritt in unserem Verständnis der Optimierung der Ausbildung von Großsprachenmodellen dar. Durch die Erstellung klarer Beziehungen zwischen Modellgröße, Trainingsdaten und Rechenkosten bietet das Gesetz einen rechenoptimalen Rahmen für effizient Skalierung von LLMs. Der Erfolg des Chinchilla -Modells zeigt die praktischen Vorteile dieses Ansatzes sowohl hinsichtlich der Leistung als auch der Ressourceneffizienz.
Während die Forschung in diesem Bereich weitergeht, werden die Prinzipien des Chinchilla -Skalierungsgesetzes wahrscheinlich die Zukunft der LLM -Entwicklung prägen und die Gestaltung von Modellen leiten, die die Grenzen dessen überschreiten, was in der Verarbeitung natürlicher Sprache möglich ist und gleichzeitig Nachhaltigkeit und Zugänglichkeit aufrechterhalten wird.
Wenn Sie online nach einem generativen KI -Kurs suchen, dann erkunden Sie: Das Genai Pinnacle -Programm!
Häufig gestellte Fragen
Q1. Was ist das Chinchilla Scaling Law?Ans. Das Chinchilla Scaling Law ist ein empirischer Rahmen, der die optimale Beziehung zwischen der Größe eines Sprachmodells (Anzahl der Parameter), der Anzahl der Trainingsdaten (Token) und den für das Training erforderlichen Rechenressourcen beschreibt. Ziel ist es, das Trainingsberechnung zu minimieren und gleichzeitig die Modellleistung zu maximieren.
Q2. Was sind die wichtigsten Parameter im Chinchilla -Skalierungsgesetz? Ans. Die wichtigsten Parameter umfassen:
1. N: Anzahl der Parameter im Modell.
2. D: Anzahl der Trainingstoken.
3. C: Gesamtberechnungskosten in Flops.
4. L: Durchschnittlicher Verlust des Modells in einem Testdatensatz.
5. A und B: Konstanten, die die Underperformance im Vergleich zu einem idealen generativen Prozess widerspiegeln.
6. α und β: Exponenten, die beschreiben, wie sich der Verlust in Bezug auf Modell und Datengröße skaliert.
Ans. Das Gesetz legt nahe, dass sowohl die Modellgröße als auch die Trainingstoken mit gleichen Raten für eine optimale Leistung skalieren sollten. Insbesondere für jede Verdoppelung der Modellgröße sollte die Anzahl der Trainingstoken auch verdoppeln, was typischerweise ein Verhältnis von etwa 20 Token pro Parameter anstrebt.
Q4. Was sind einige Kritikpunkte oder Einschränkungen des Chinchilla -Skalierungsgesetzes?Ans. Jüngste Studien haben potenzielle Probleme mit den ursprünglichen Schätzungen von Hoffmann et al. Angezeigt, einschließlich Inkonsistenzen in gemeldeten Daten und übermäßig engen Konfidenzintervallen. Einige Forscher argumentieren, dass das Skalierungsgesetz möglicherweise zu simpel ist und für verschiedene praktische Überlegungen in der Modelltraining nicht berücksichtigt wird.
Q5. Wie hat das Chinchilla Scaling Law die jüngste Sprachmodellentwicklung beeinflusst?Ans. Die Ergebnisse des Chinchilla Scaling Law haben mehrere bemerkenswerte Modelle Design- und Schulungsprozesse, einschließlich der Gemini Suite von Google, informiert. Es hat auch zu Diskussionen über „Beyond Chinchilla“ -Sstrategien geführt, bei denen Forscher nach den ursprünglichen Skalierungsgesetzen Trainingsmodelle untersuchen, die größer als optimal sind.
Das obige ist der detaillierte Inhalt vonWas ist das Chinchilla Scaling Law?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

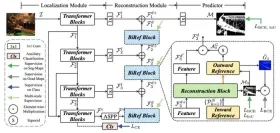
 RF-Detr: Überbrückungsgeschwindigkeit und Genauigkeit bei der ObjekterkennungApr 24, 2025 am 10:40 AM
RF-Detr: Überbrückungsgeschwindigkeit und Genauigkeit bei der ObjekterkennungApr 24, 2025 am 10:40 AMWillkommene Leser, die CV -Klasse ist wieder in der Sitzung! In meinem vorherigen Blog haben wir bisher 30 verschiedene Computer -Vision -Modelle untersucht, die jeweils ihre eigenen einzigartigen Stärken auf den Tisch bringen
 Agent SDK gegen Crewai vs Langchain: Welches zu verwenden, wann?Apr 24, 2025 am 10:39 AM
Agent SDK gegen Crewai vs Langchain: Welches zu verwenden, wann?Apr 24, 2025 am 10:39 AMDieser Artikel vergleicht drei beliebte Rahmenbedingungen zum Aufbau von AI -Agenten: OpenAIs Agent SDK, Langchain und Crewai. Jedes bietet einzigartige Stärken für die Automatisierung von Aufgaben und die Verbesserung der Entscheidungsfindung. Der Artikel führt Sie durch die Auswahl des besten Frams
 Aufbau eines strukturierten Forschungsautomationssystems mit PydanticApr 24, 2025 am 10:32 AM
Aufbau eines strukturierten Forschungsautomationssystems mit PydanticApr 24, 2025 am 10:32 AMIm dynamischen Bereich der akademischen Forschung sind effiziente Informationssammeln, Synthese und Präsentation von größter Bedeutung. Der manuelle Prozess der Literaturübersicht ist zeitaufwändig und behindert eine tiefere Analyse. Ein Multi-Agent-Forschungsassistenten-System Bui
 10 GPT-4O-Bildgenerierung Aufforderungen, heute auszuprobieren!Apr 24, 2025 am 10:26 AM
10 GPT-4O-Bildgenerierung Aufforderungen, heute auszuprobieren!Apr 24, 2025 am 10:26 AMIn der Welt der KI passiert absolut wildes Zeug. OpenAIs einheimische Bildgenerierung ist momentan verrückt. Wir sprechen über umwerfende Visuals, gruselige Details und Ausgänge, die so poliert sind, dass sie sich von einem Voll-On handgefertigt fühlen
 Leitfaden zur Vibe -Codierung mit WindsurfApr 24, 2025 am 10:25 AM
Leitfaden zur Vibe -Codierung mit WindsurfApr 24, 2025 am 10:25 AMMachen Sie Ihre Codierungsvisionen mühelos mit dem Windsurf von Codeium, Ihrem KI-betriebenen Codierungsbegleiter, zum Leben. Windsurf optimiert den gesamten Lebenszyklus der Softwareentwicklung, vom Codieren und Debuggen bis hin zur Optimierung, wobei der Prozess in eine Inu umgewandelt wird
 Erforschen der Bildhintergrundentfernung mit RMGB v2.0Apr 24, 2025 am 10:20 AM
Erforschen der Bildhintergrundentfernung mit RMGB v2.0Apr 24, 2025 am 10:20 AMBraiais RMGB V2.0: Ein leistungsstarkes Modell zur Entfernung von Open-Source-Hintergrund Bildsegmentierungsmodelle revolutionieren verschiedene Felder, und die Entfernung des Hintergrunds ist ein Schlüsselbereich des Fortschritts. Braiais RMGB v2.0 sticht als hochmoderne Open-Source-M aus
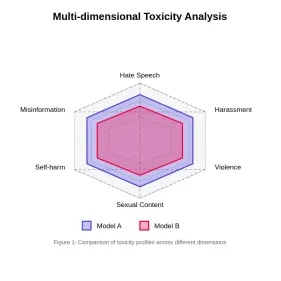 Bewertung der Toxizität in großen SprachmodellenApr 24, 2025 am 10:14 AM
Bewertung der Toxizität in großen SprachmodellenApr 24, 2025 am 10:14 AMIn diesem Artikel wird das entscheidende Problem der Toxizität in Großsprachenmodellen (LLMs) und die Methoden zur Bewertung und Minderung von Methoden untersucht. LLMs, die verschiedene Anwendungen von Chatbots bis hin zur Erzeugung von Inhalten betreiben, erfordert robuste Bewertungsmetriken, Witz
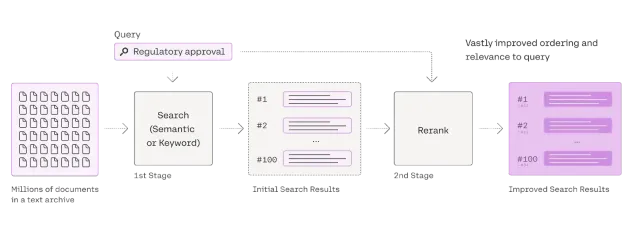 Umfassende Anleitung zum Reranker für LappenApr 24, 2025 am 10:10 AM
Umfassende Anleitung zum Reranker für LappenApr 24, 2025 am 10:10 AMRAG -Systeme (Abrufener Augmented Generation) transformieren den Zugang zum Informationen, ihre Effektivität hängt jedoch von der Qualität der abgerufenen Daten ab. Hier werden die Reranker entscheidend - als Qualitätsfilter für Suchergebnisse, um nur sicherzustellen, dass sie nur sicherstellen


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

