



Machine Learning (ML) ist jetzt ein Eckpfeiler der modernen Technologie, die Unternehmen und Forscher befähigen, genauere datengesteuerte Entscheidungen zu treffen. auf individuelle Bedürfnisse zugeschnitten.

Inhaltsverzeichnis
- Modellauswahldefinition
- Die Bedeutung der Modellauswahl
- Wie wähle ich den anfänglichen Modellsatz aus?
- Wie wähle ich das beste Modell aus dem ausgewählten Modell (Modellauswahltechnik) aus?
- abschließend
- Häufig gestellte Fragen
Modellauswahldefinition
Die Modellauswahl bezieht sich auf den Prozess der Identifizierung des am besten geeigneten Modells für maschinelles Lernen für eine bestimmte Aufgabe, indem verschiedene Optionen basierend auf der Leistung des Modells und der Konsistenz mit den Problemanforderungen bewertet werden. Dazu gehören Faktoren wie Problemtyp (z. B. Klassifizierung oder Regression), Merkmale der Daten, relevante Leistungsmetriken und Kompromisse zwischen Unteranpassung und Überanpassung. Praktische Einschränkungen wie Computerressourcen und die Notwendigkeit von Interpretierbarkeit können auch die Entscheidungen beeinflussen. Ziel ist es, ein Modell auszuwählen, das die beste Leistung liefert und Projektziele und Einschränkungen erreicht.
Die Bedeutung der Modellauswahl
Die Auswahl des richtigen maschinellen Lernmodells (ML) ist ein kritischer Schritt bei der Entwicklung einer erfolgreichen KI -Lösung. Die Bedeutung der Modellauswahl liegt in ihren Auswirkungen auf die Leistung, Effizienz und Machbarkeit von ML -Anwendungen. Hier sind die Gründe für seine Bedeutung:
1. Genauigkeit und Leistung
Unterschiedliche Modelle sind bei verschiedenen Aufgabentypen gut. Beispielsweise kann ein Entscheidungsbaum für klassifizierte Daten geeignet sein, während ein Faltungsnetz (CNN) gut in der Bilderkennung ist. Die Auswahl des falschen Modells kann zu suboptimalen Vorhersagen oder hohen Fehlerraten führen, wodurch die Zuverlässigkeit der Lösung verringert wird.
2. Effizienz und Skalierbarkeit
Die rechnerische Komplexität eines ML -Modells beeinflusst seine Trainings- und Inferenzzeit. Bei groß angelegten oder in Echtzeitanwendungen, leichten Modelle wie lineare Regression oder zufällige Wälder können angemessener sein als rechnerisch intensive neuronale Netze.
Modelle, die nicht effektiv skaliert werden können, wenn Datenerhöhungen zu Engpässen führen.
3. Interpretierbarkeit
Abhängig von der Anwendung kann die Interpretierbarkeit Priorität haben. Zum Beispiel müssen die Stakeholder im Bereich des Gesundheitswesens oder im Finanzbereich häufig klare Gründe für Vorhersagen haben. Einfache Modelle (z. B. logistische Regression) können Black -Box -Modellen (z. B. tiefe neuronale Netzwerke) vorzuziehen sein.
4. Feldanwendbarkeit
Einige Modelle sind für bestimmte Datentypen oder Felder ausgelegt. Die Zeitreihenvorhersage profitiert von Modellen wie ARIMA oder LSTM, während natürliche Sprachverarbeitungsaufgaben häufig konverterbasierte Architekturen verwenden.
5. Ressourcenbeschränkungen
Nicht alle Unternehmen verfügen über die Rechenleistung, um komplexe Modelle auszuführen. Einfachere Modelle, die in Ressourcenbeschränkungen gut abschneiden, können dazu beitragen, Leistung und Machbarkeit auszugleichen.
6. Überanpassung und Verallgemeinerung
Komplexe Modelle mit vielen Parametern können leicht zu übertragen werden, wodurch Rauschen und nicht latente Muster erfasst werden. Durch die Auswahl eines Modells, das gut auf neue Daten verallgemeinert wird, wird eine bessere tatsächliche Leistung gewährleistet.
7. Anpassungsfähigkeit
Die Fähigkeit von Modellen, sich an sich ändernde Datenverteilungen oder -anforderungen anzupassen, ist in dynamischen Umgebungen von entscheidender Bedeutung. Zum Beispiel eignen sich Online-Lernalgorithmen besser für die Echtzeitentwicklung von Daten.
8. Kosten- und Entwicklungszeit
Einige Modelle erfordern eine Menge Hyperparameteranpassungen, Feature -Engineering oder Kennzeichnungsdaten, wodurch die Entwicklungskosten und die Zeit erhöht werden. Durch die Auswahl des richtigen Modells kann die Entwicklung und Bereitstellung vereinfacht werden.
Wie wähle ich den anfänglichen Modellsatz aus?
Zunächst müssen Sie eine Reihe von Modellen basierend auf den Daten und den Aufgaben, die Sie ausführen möchten, auswählen. Dies spart Ihnen Zeit im Vergleich zum Testen jedes ML -Modells.

1. Basierend auf Aufgabe:
- Klassifizierung: Wenn das Ziel darin besteht, Kategorien (z. B. "Spam" gegen "Nicht-Spam") vorherzusagen, sollte das Klassifizierungsmodell verwendet werden.
- Modellbeispiele: Logistische Regression, Entscheidungsbaum, Zufallswald, Unterstützungsvektormaschine (SVM), K-Nearest Neighbor (K-NN), neuronales Netzwerk.
- Regression: Wenn das Ziel darin besteht, kontinuierliche Werte (z. B. Immobilienpreise, Aktienkurse) vorherzusagen, sollte ein Regressionsmodell verwendet werden.
- Modellbeispiele: Lineare Regression, Entscheidungsbaum, Zufallswaldregression, Unterstützung der Vektorregression, neuronales Netzwerk.
- Clustering: Wenn das Ziel darin besteht, Daten in einen Cluster ohne vorherige Tags zu gruppieren, wird ein Clustering -Modell verwendet.
- Modellbeispiele: K-Mean, DBSCAN, hierarchisches Clustering, Gaußsche Hybridmodell.
- Anomalie -Erkennung: Wenn das Ziel seltene Ereignisse oder Ausreißer identifiziert wird, verwenden Sie den Anomalie -Erkennungsalgorithmus.
- Modellbeispiele: isolierter Wald, Einzelklassen -SVM und Autocoder.
- Zeitreihenvorhersage: Wenn das Ziel es ist, zukünftige Werte basierend auf Zeitdaten vorherzusagen.
- Modellbeispiele: Arima, exponentielle Glättung, LSTM, Prophet.
2. basierend auf Daten
Typ
- Strukturierte Daten (Tabellendaten): Verwenden Sie Modelle wie Entscheidungsbäume, zufällige Wälder, Xgboost oder logistische Regression.
- Unstrukturierte Daten (Text, Bilder, Audio usw.): Verwenden Sie Modelle wie CNN (für Bilder), RNN oder Konverter (für Text) oder Audio -Verarbeitungsmodelle.
Größe
- Kleine Datensätze: Einfache Modelle (z. B. logistische Regression oder Entscheidungsbäume) funktionieren in der Regel gut, da komplexe Modelle möglicherweise übermäßig sind.
- Große Datensätze: Deep Learning -Modelle (wie neuronale Netze, CNNs, RNNs) eignen sich besser für die Verarbeitung großer Datenmengen.
Qualität
- Fehlende Werte: Einige Modelle (z. B. zufällige Wälder) können fehlende Werte bewältigen, während andere (z. B. SVM) unterstellt werden müssen.
- Rauschen und Ausreißer: Robuste Modelle (z. B. zufällige Wälder) oder Modelle mit Regularisierung (wie Lasso) sind eine gute Wahl für die Verarbeitung von Rauschdaten.
Wie wähle ich das beste Modell aus dem ausgewählten Modell (Modellauswahltechnik) aus?
Die Modellauswahl ist ein wichtiger Aspekt des maschinellen Lernens, mit dem die besten Modelle in einem bestimmten Datensatz und Problem ermittelt werden können. Die beiden Haupttechniken sind Resampling -Methoden und Wahrscheinlichkeitsmessungen, die jeweils eine eindeutige Modellbewertungsmethode haben.
1. Ressampling -Methode
Die Resampling -Methode umfasst die Umordnung und Wiederverwendung von Daten von Daten, um die Leistung des Modells auf unsichtbaren Proben zu testen. Dies hilft, die Fähigkeit des Modells zu bewerten, neue Daten zu verallgemeinern. Die beiden Hauptresampling -Techniken sind:
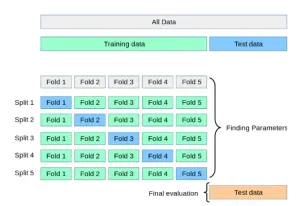
Kreuzvalidierung
Kreuzvalidierung ist ein systematisches Resampling-Verfahren zur Bewertung der Modellleistung. In dieser Methode:
- Der Datensatz ist in Gruppen oder Falten unterteilt.
- Eine Gruppe wird als Testdaten verwendet und der Rest wird für das Training verwendet.
- Das Modell wird trainiert und iterativ über alle Falten bewertet.
- Berechnen Sie die durchschnittliche Leistung aller Iterationen, um zuverlässige Genauigkeitsmetriken bereitzustellen.
Kreuzvalidierung ist besonders nützlich, wenn Sie Modelle wie Support Vector Machines (SVMs) und logistische Regression vergleichen, um zu bestimmen, welches Modell für ein bestimmtes Problem besser geeignet ist.
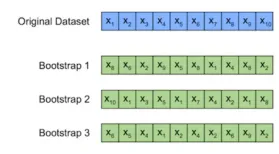
Bootstrap -Methode
Bootstrap ist eine Stichprobentechnik, bei der Daten nach dem Zufallsprinzip auf alternative Weise zur Schätzung der Leistung des Modells probiert werden.
Hauptmerkmale
- Hauptsächlich in kleineren Datensätzen verwendet.
- Die Größe der Beispiel- und Testdaten entspricht dem ursprünglichen Datensatz.
- Proben, die die höchste Punktzahl erzeugen, werden normalerweise verwendet.
Der Prozess beinhaltet zufällig die Auswahl eines Beobachtungswerts, die Aufzeichnung, das Zurücksetzen in den Datensatz und die Wiederholung des Vorgangs n -mal. Die generierten Startproben liefern Einblicke in die Modell -Robustheit.
2. Wahrscheinlichkeitsmessung
Wahrscheinlichkeitsmetriken bewerten die Leistung des Modells basierend auf statistischen Metriken und Komplexität. Diese Ansätze konzentrieren sich darauf, Leistung und Einfachheit auszugleichen. Im Gegensatz zum Resampling erfordern sie keine separaten Testsätze, da die Leistung unter Verwendung von Trainingsdaten berechnet wird.
AKAGI -Informationsrichtlinien (AIC)
AIC bewertet das Modell, indem er die Güte der Passform und seine Komplexität ausgleichen. Es stammt aus der Informationstheorie und bestraft die Anzahl der Parameter im Modell, um eine Überanpassung zu vermeiden.
Formel:

- Güte der Passform: Höhere Wahrscheinlichkeit bedeutet eine bessere Anpassung der Daten.
- Komplexitätsstrafe: Der Begriff 2K bestraft Modelle mit mehr Parametern, um eine Überanpassung zu vermeiden.
- Erläuterung: Je niedriger der AIC -Wert ist, desto besser das Modell. AICs können jedoch manchmal zu übermäßig komplexen Modellen verdrängen, da sie Anpassung und Komplexität ausgleichen und weniger streng sind als andere Standards.
Bayes'sche Informationskriterien (BIC)
BIC ähnelt AIC, aber die Bestrafung für die Modellkomplexität ist stärker und macht es konservativer. Es ist besonders nützlich bei der Modellauswahl für Zeitreihen und Regressionsmodelle, bei denen Überanpassung ein Problem ist.
Formel:

- Güte der Passform: Wie AIC verbessern höhere Wahrscheinlichkeiten die Werte.
- Komplexitätsstrafe: Dieser Begriff bestraft Modelle mit mehr Parametern, und die Strafe steigt mit zunehmender Probengröße N.
- Erläuterung: BICs sind tendenziell simpelere Modelle als AICs, da dies strengere Strafen für zusätzliche Parameter bedeutet.
Mindestbeschreibungslänge (MDL)
MDL ist ein Prinzip, das das Modell auswählt, das Daten am effizientesten komprimiert. Es ist in der Informationstheorie verwurzelt und zielt darauf ab, die Gesamtkosten für die Beschreibung von Modellen und Daten zu minimieren.
Formel:

- Einfachheit und Effizienz: MDL neigt dazu zu modellieren, dass das Beste zwischen Einfachheit (kürzerer Modellbeschreibung) und Genauigkeit (die Fähigkeit, die Daten darzustellen) auszugleichen.
- Komprimierung: Ein gutes Modell liefert eine kurze Zusammenfassung der Daten, wodurch die Beschreibungslänge effektiv verringert wird.
- Erläuterung: Das Modell mit dem niedrigsten MDL wird bevorzugt.
abschließend
Die Auswahl des besten maschinelles Lernenmodells für einen bestimmten Anwendungsfall erfordert einen systematischen Ansatz, einen Ausgleich von Problemanforderungen, Datenmerkmalen und praktische Einschränkungen. Durch das Verständnis der Art der Aufgabe, der Struktur der Daten und der Kompromisse, die an der Modellkomplexität, Genauigkeit und Interpretierbarkeit beteiligt sind, können Sie die Kandidatenmodelle eingrenzen. Technologien wie Quervalidierung und Wahrscheinlichkeitsmetriken (AIC, BIC, MDL) stellen sicher, dass diese Kandidaten streng bewertet werden, sodass Sie ein Modell auswählen können, das gut verallgemeinert und Ihre Ziele erreicht.
Letztendlich ist der Modellauswahlprozess iterativ und kontextgetrieben. Es ist wichtig, Problembereiche, Ressourcenbeschränkungen und ein Gleichgewicht zwischen Leistung und Durchführbarkeit zu berücksichtigen. Durch die sorgfältige Integration von Domänenkompetenz, Experimentieren und Bewertungsmetriken können Sie ein ML -Modell auswählen, das nicht nur die besten Ergebnisse liefert, sondern auch den praktischen und operativen Anforderungen Ihrer Anwendung entspricht.
Wenn Sie nach Online -KI/ML -Kursen suchen
Häufig gestellte Fragen
Q1. Woher weiß ich, welches ML -Modell das Beste ist?
A: Die Auswahl des besten ML -Modells hängt von der Art des Problems (Kategorisierung, Regression, Clusterbildung usw.), der Größe und Qualität der Daten und den Kompromisse zwischen Genauigkeit, Interpretierbarkeit und Recheneffizienz ab. Bestimmen Sie zunächst Ihren Problemtyp (z. B. Regression, die zur Vorhersage von Zahlen oder Klassifikationen zur Klassifizierung von Daten verwendet werden). Verwenden Sie für kleinere Datensätze oder wenn die Interpretierbarkeit kritisch ist, und verwenden Sie einfache Modelle wie lineare Regression oder Entscheidungsbäume. Verwenden Sie für größere Datensätze, die eine höhere Genauigkeit erfordern, komplexere Modelle wie zufällige Wälder oder neuronale Netzwerke. Bewerten Sie das Modell immer mithilfe von Metriken im Zusammenhang mit Ihren Zielen (z. B. Genauigkeit, Genauigkeit und RMSE) und testen Sie mehrere Algorithmen, um die beste Anpassung zu finden.
F2.
A: Um zwei ML -Modelle zu vergleichen, bewerten Sie ihre Leistung im selben Datensatz mithilfe konsistenter Bewertungsmetriken. Teilen Sie die Daten in Trainings- und Testsätze auf (oder verwenden Sie eine Kreuzvalidierung), um Fairness zu gewährleisten, und bewerten Sie jedes Modell mithilfe von Metriken, die sich auf Ihre Frage beziehen, z. B. Genauigkeit, Genauigkeit oder RMSE. Die Ergebnisse werden analysiert, um zu bestimmen, welches Modell bessere Leistungen erbringt, aber auch Kompromisse wie Interpretierbarkeit, Schulungszeit und Skalierbarkeit berücksichtigen. Wenn die Leistungsunterschiede gering sind, verwenden Sie statistische Tests, um die Signifikanz zu bestätigen. Letztendlich wird ein Modell ausgewählt, das die Leistung mit den tatsächlichen Anforderungen des Anwendungsfalls ausgleichen.
F3.
A: Das beste ML -Modell für die Vorhersage von Verkäufen hängt von Ihrem Datensatz und Ihren Anforderungen ab. Zu den häufig verwendeten Modellen gehören jedoch Gradienten -Boosting -Algorithmen wie lineare Regression, Entscheidungsbäume oder Xgboost. Lineare Regression eignet sich gut für einfache Datensätze mit klaren linearen Trends. Für komplexere Beziehungen oder Interaktionen bieten Gradientensteigerungen oder zufällige Wälder häufig eine höhere Genauigkeit. Wenn die Daten Zeitreihenmuster beinhalten, sind Modelle wie Arima, Sarima oder Long-Del-Dem-Memory (LSTM) -Netzwerke besser geeignet. Wählen Sie ein Modell, das die Vorhersageleistung, Interpretierbarkeit und Skalierbarkeit der Umsatzprognose -Nachfrage in Einklang bringt.
Das obige ist der detaillierte Inhalt vonWie wähle ich das beste ML -Modell für Ihre Usecase aus?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

![Kann Chatgpt nicht verwenden! Erklären Sie die Ursachen und Lösungen, die sofort getestet werden können [die neueste 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Kann Chatgpt nicht verwenden! Erklären Sie die Ursachen und Lösungen, die sofort getestet werden können [die neueste 2025]May 14, 2025 am 05:04 AM
Kann Chatgpt nicht verwenden! Erklären Sie die Ursachen und Lösungen, die sofort getestet werden können [die neueste 2025]May 14, 2025 am 05:04 AMChatgpt ist nicht zugänglich? Dieser Artikel bietet eine Vielzahl von praktischen Lösungen! Viele Benutzer können auf Probleme wie Unzugänglichkeit oder langsame Reaktion stoßen, wenn sie täglich ChatGPT verwenden. In diesem Artikel werden Sie geführt, diese Probleme Schritt für Schritt basierend auf verschiedenen Situationen zu lösen. Ursachen für Chatgpts Unzugänglichkeit und vorläufige Fehlerbehebung Zunächst müssen wir feststellen, ob sich das Problem auf der OpenAI -Serverseite oder auf dem eigenen Netzwerk- oder Geräteproblemen des Benutzers befindet. Bitte befolgen Sie die folgenden Schritte, um Fehler zu beheben: Schritt 1: Überprüfen Sie den offiziellen Status von OpenAI Besuchen Sie die OpenAI -Statusseite (status.openai.com), um festzustellen, ob der ChatGPT -Dienst normal ausgeführt wird. Wenn ein roter oder gelber Alarm angezeigt wird, bedeutet dies offen
 Die Berechnung des Risikos des ASI beginnt mit dem menschlichen GeistMay 14, 2025 am 05:02 AM
Die Berechnung des Risikos des ASI beginnt mit dem menschlichen GeistMay 14, 2025 am 05:02 AMAm 10. Mai 2025 teilte der MIT-Physiker Max Tegmark dem Guardian mit, dass AI Labs Oppenheimers Dreifaltigkeitstestkalkül emulieren sollten, bevor sie künstliche Super-Intelligence veröffentlichen. „Meine Einschätzung ist, dass die 'Compton Constant', die Wahrscheinlichkeit, dass ein Rennen ums Rasse
 Eine leicht verständliche Erklärung zum Schreiben und Komponieren von Texten und empfohlenen Tools in ChatgptMay 14, 2025 am 05:01 AM
Eine leicht verständliche Erklärung zum Schreiben und Komponieren von Texten und empfohlenen Tools in ChatgptMay 14, 2025 am 05:01 AMDie KI -Musikkreationstechnologie verändert sich mit jedem Tag. In diesem Artikel werden AI -Modelle wie ChatGPT als Beispiel verwendet, um ausführlich zu erklären, wie mit AI die Erstellung der Musik unterstützt und sie mit tatsächlichen Fällen erklärt. Wir werden vorstellen, wie man Musik durch Sunoai, Ai Jukebox auf Umarmung und Pythons Music21 -Bibliothek kreiert. Mit diesen Technologien kann jeder problemlos Originalmusik erstellen. Es ist jedoch zu beachten, dass das Urheberrechtsproblem von AI-generierten Inhalten nicht ignoriert werden kann, und Sie müssen bei der Verwendung vorsichtig sein. Lassen Sie uns die unendlichen Möglichkeiten der KI im Musikfeld zusammen erkunden! OpenAIs neuester AI -Agent "Openai Deep Research" führt vor: [CHATGPT] ope
 Was ist Chatgpt-4? Eine gründliche Erklärung für das, was Sie tun können, die Preisgestaltung und die Unterschiede von GPT-3.5!May 14, 2025 am 05:00 AM
Was ist Chatgpt-4? Eine gründliche Erklärung für das, was Sie tun können, die Preisgestaltung und die Unterschiede von GPT-3.5!May 14, 2025 am 05:00 AMDie Entstehung von Chatgpt-4 hat die Möglichkeit von AI-Anwendungen erheblich erweitert. Im Vergleich zu GPT-3,5 hat sich ChatGPT-4 erheblich verbessert. Es verfügt über leistungsstarke Kontextverständnisfunktionen und kann auch Bilder erkennen und generieren. Es ist ein universeller AI -Assistent. Es hat in vielen Bereichen ein großes Potenzial gezeigt, z. B. die Verbesserung der Geschäftseffizienz und die Unterstützung der Schaffung. Gleichzeitig müssen wir jedoch auch auf die Vorsichtsmaßnahmen ihrer Verwendung achten. In diesem Artikel werden die Eigenschaften von ChatGPT-4 im Detail erläutert und effektive Verwendungsmethoden für verschiedene Szenarien einführt. Der Artikel enthält Fähigkeiten, um die neuesten KI -Technologien voll auszunutzen. Weitere Informationen finden Sie darauf. OpenAIs neueste AI -Agentin, klicken Sie auf den Link unten, um Einzelheiten zu "OpenAI Deep Research" zu erhalten.
 Erklären Sie, wie Sie die Chatgpt -App verwenden! Japanische Unterstützung und SprachkonversationsfunktionMay 14, 2025 am 04:59 AM
Erklären Sie, wie Sie die Chatgpt -App verwenden! Japanische Unterstützung und SprachkonversationsfunktionMay 14, 2025 am 04:59 AMCHATGPT -App: Entfesselt Ihre Kreativität mit dem AI -Assistenten! Anfängerführer Die ChatGPT -App ist ein innovativer KI -Assistent, der eine breite Palette von Aufgaben erledigt, einschließlich Schreiben, Übersetzung und Beantwortung von Fragen. Es ist ein Werkzeug mit endlosen Möglichkeiten, die für kreative Aktivitäten und Informationssammeln nützlich sind. In diesem Artikel werden wir für Anfänger eine leicht verständliche Weise von der Installation der ChatGPT-Smartphone-App bis hin zu den Funktionen für Apps wie Spracheingangsfunktionen und Plugins sowie die Punkte erklären, die Sie bei der Verwendung der App berücksichtigen sollten. Wir werden auch die Pluginbeschränkungen und die Konfiguration der Geräte-zu-Device-Konfiguration genauer betrachten
 Wie benutze ich die chinesische Version von Chatgpt? Erläuterung der Registrierungsverfahren und GebührenMay 14, 2025 am 04:56 AM
Wie benutze ich die chinesische Version von Chatgpt? Erläuterung der Registrierungsverfahren und GebührenMay 14, 2025 am 04:56 AMChatgpt Chinesische Version: Schalte neue Erfahrung des chinesischen KI -Dialogs frei Chatgpt ist weltweit beliebt. Wussten Sie, dass es auch eine chinesische Version bietet? Dieses leistungsstarke KI -Tool unterstützt nicht nur tägliche Gespräche, sondern behandelt auch professionelle Inhalte und ist mit vereinfachtem und traditionellem Chinesisch kompatibel. Egal, ob es sich um einen Benutzer in China oder ein Freund, der Chinesisch lernt, Sie können davon profitieren. In diesem Artikel wird detailliert eingeführt, wie die chinesische ChatGPT -Version verwendet wird, einschließlich der Kontoeinstellungen, der Eingabeaufgabe der chinesischen Eingabeaufforderung, der Filtergebrauch und der Auswahl verschiedener Pakete sowie potenziellen Risiken und Antwortstrategien. Darüber hinaus werden wir die chinesische Chatgpt -Version mit anderen chinesischen KI -Tools vergleichen, um die Vorteile und Anwendungsszenarien besser zu verstehen. Openais neueste KI -Intelligenz
 5 KI -Agent -Mythen, die Sie jetzt aufhören müssen, zu glaubenMay 14, 2025 am 04:54 AM
5 KI -Agent -Mythen, die Sie jetzt aufhören müssen, zu glaubenMay 14, 2025 am 04:54 AMDiese können als der nächste Sprung nach vorne im Bereich der generativen KI angesehen werden, was uns Chatgpt und andere Chatbots mit großer Sprache modellierte. Anstatt nur Fragen zu beantworten oder Informationen zu generieren, können sie in unserem Namen Maßnahmen ergreifen, Inter
 Eine leicht verständliche Erklärung für die Illegalität des Erstellens und Verwalten mehrerer Konten mit ChatGPTMay 14, 2025 am 04:50 AM
Eine leicht verständliche Erklärung für die Illegalität des Erstellens und Verwalten mehrerer Konten mit ChatGPTMay 14, 2025 am 04:50 AMEffiziente Mehrfachkontoverwaltungstechniken mit Chatgpt | Eine gründliche Erklärung, wie man Geschäft und Privatleben nutzt! Chatgpt wird in verschiedenen Situationen verwendet, aber einige Leute machen sich möglicherweise Sorgen über die Verwaltung mehrerer Konten. In diesem Artikel wird ausführlich erläutert, wie mehrere Konten für ChatGPT, was zu tun ist, wenn Sie es verwenden und wie Sie es sicher und effizient bedienen. Wir decken auch wichtige Punkte wie den Unterschied in der Geschäfts- und Privatnutzung sowie die Einhaltung der Nutzungsbedingungen von OpenAI ab und bieten einen Leitfaden zur Verfügung, mit dem Sie mehrere Konten sicher verwenden können. Openai


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

