

 Technologie-PeripheriegeräteKIJina Einbettung V2: Umgang mit langen Dokumenten, die einfach gemacht wurden
Technologie-PeripheriegeräteKIJina Einbettung V2: Umgang mit langen Dokumenten, die einfach gemacht wurdenJina Einbettung V2: Umgang mit langen Dokumenten, die einfach gemacht wurden

Jina Einbettung v2: revolutionieren Langdokumenttextexbettierung
aktuelle Texteinbettungsmodelle wie Bert werden durch eine Verarbeitungsgrenze von 512 geklärt und behindern ihre Leistung mit langwierigen Dokumenten. Diese Einschränkung führt häufig zu Kontextverlust und ungenauen Verständnis. Jina einbettet V2 diese Einschränkung, indem sie Sequenzen bis zu 8192 Token unterstützt, einen entscheidenden Kontext bewahrt und die Genauigkeit und Relevanz von verarbeiteten Informationen in umfangreichen Texten erheblich verbessert. Dies stellt einen wesentlichen Fortschritt bei der Behandlung komplexer Textdaten dar.
Key -Lernpunkte
- Verständnis der Grenzen herkömmlicher Modelle wie Bert bei der Bearbeitung langer Dokumente.
- Erlernen, wie Jina die Einbettung v2 durch seine Einschränkungen durch seine 8192-Token-Kapazität und fortgeschrittene Architektur überwindet.
- Erforschung der innovativen Merkmale von Jina Embodings V2, einschließlich Alibi, GLU und seiner dreistufigen Trainingsmethode.
- Entdeckung realer Anwendungen in Rechtsforschung, Content-Management und generatives AI.
- praktische Erfahrungen bei der Integration von Jina einbetteten V2 in Projekte mit umarmenden Gesichtsbibliotheken.
Dieser Artikel ist Teil des Data Science -Blogathons.
Inhaltsverzeichnis
- Die Herausforderungen, lange Dokumente einzubetten
- Architektur Innovationen und Trainingsmethoden
- Leistungsbewertung
- reale Anwendungen
- Modellvergleich
- Verwenden von Jina Embodings v2 mit umarmtem Gesicht
- Schlussfolgerung
- häufig gestellte Fragen
Die Herausforderungen, lange Dokumente einzubetten
Verarbeitung langer Dokumente stellt erhebliche Herausforderungen in der Verarbeitung natürlicher Sprache (NLP) auf. Traditionelle Methoden verarbeiten Text in Segmenten und führen zu Kontextabschnitten und fragmentierten Einbettungen, die das Originaldokument falsch darstellen. Dies führt zu:
- erhöhte Rechenanforderungen
- höherer Speicherverbrauch
- Reduzierte Leistung bei Aufgaben, die ein umfassendes Verständnis des Textes erfordern
jina initdings v2 befasst sich direkt mit diesen Problemen, indem sie die Token -Grenze auf 8192 erhöht, die Notwendigkeit einer übermäßigen Segmentierung beseitigt und die semantische Integrität des Dokuments aufrechterhalten.
Architekturale Innovationen und Schulungsmethoden
jina bettbettungen v2 verstärkt die Fähigkeiten von Bert mit hochmodernen Innovationen:
- Aufmerksamkeit mit linearen Verzerrungen (Alibi): Alibi ersetzt traditionelle Positionsbettdings durch eine lineare Verzerrung, die auf Beachtungswerte angewendet wird. Dies ermöglicht es dem Modell, effektiv auf Sequenzen zu extrapolieren, die weit länger als die während des Trainings aufgetreten sind. Im Gegensatz zu früheren unidirektionalen Implementierungen verwendet Jina Embodings V2 eine bidirektionale Variante, um die Kompatibilität mit Codierungsaufgaben zu gewährleisten.
- Gated Lineare Einheiten (GLU): Glu, die für die Verbesserung der Transformatoreffizienz bekannt ist, wird in den Feedforward -Schichten verwendet. Varianten wie Geglu und Reglu werden verwendet, um die Leistung basierend auf der Modellgröße zu optimieren.
- Optimiertes Training: Jina Embodings V2 verwendet einen dreistufigen Schulungsprozess:
- Vorabbau: trainiert auf dem kolossalen sauberen Krabbeln (C4) mit maskierter Sprachmodellierung (MLM).
- Feinabstimmung mit Textpaaren: Ausrichtungen für semantisch ähnliche Textpaare.
- Hartnegative Feinabstimmung: verbessert das Ranking und Abruf, indem es anspruchsvolle Distraktor-Beispiele einbezieht.
- Speichereffizientes Training: Techniken wie gemischtes Präzisionstraining und Aktivierungsprüfung sicherstellen
 Die Aufmerksamkeit von
Die Aufmerksamkeit von
m , wodurch seine Berechnung diversifiziert wird. Das Modell verwendet die Encoder -Variante, bei der alle Token gegeneinander anwesend sind, im Gegensatz zu der in der Sprachmodellierung verwendeten kausalen Variante.
Leistungsbewertung
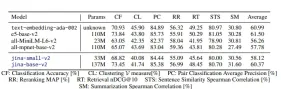
- Klassifizierung: Top -Genauigkeit in Aufgaben wie Amazon Polarity und toxische Konversationen Klassifizierung.
- Clustering: übertrifft die Wettbewerber in Gruppierungstexten (Patentclustering und Wikizitiesclustering).
- Abrufen: Excels in Aufgaben wie narrativeqa, wobei der vollständige Dokumentkontext von entscheidender Bedeutung ist.
- Langes Dokumenthandhabung: behält die MLM-Genauigkeit auch mit 8192-geehrten Sequenzen bei.
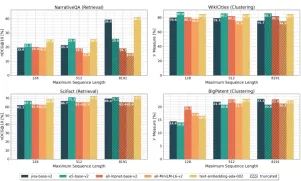
reale Anwendungen
- Recht und akademische Forschung: ideal für die Suche und Analyse von Rechtsdokumenten und akademischen Arbeiten.
- Content -Management -Systeme: Effiziente Tagging, Clustering und Abrufen großer Dokument -Repositories.
- generative AI: verbessert die Zusammenfassungen von AI-generierten und prompt-basierten Modellen.
- E-Commerce: Verbessert die Systemsuche und Empfehlungssysteme.
Modellvergleich
jina einbettet V2 nicht nur in den Umgang mit langen Sequenzen, sondern auch im Wettbewerb mit proprietären Modellen wie OpenAs Text-Embedding-ada-002. Seine Open-Source-Natur sorgt für die Zugänglichkeit.
Verwenden Sie Jina Embettdings v2 mit umarmtem Gesicht
Schritt 1: Installation
!pip install transformers !pip install -U sentence-transformers
Schritt 2: Verwenden von Jina -Einbettungen mit Transformatoren
import torch
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a, b: (a @ b.T) / (norm(a) * norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?'])
print(cos_sim(embeddings, embeddings))
Ausgabe:
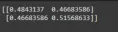
Umgang mit langen Sequenzen:
embeddings = model.encode(['Very long ... document'], max_length=2048)
Schritt 3: Verwenden von Jina-Einbettungen mit Satztransformer
(ähnlicher Code mit sentence_transformers Bibliothek wird sowie Anweisungen zum Einstellen max_seq_length.)
Schlussfolgerung
jina embeddings v2 ist ein signifikanter Fortschritt bei NLP, der die Einschränkungen der Verarbeitung langer Dokumente effektiv behandelt. Seine Fähigkeiten verbessern bestehende Arbeitsabläufe und entsperren neue Möglichkeiten für die Arbeit mit Langformtext.
Key Takeaways (zusammengefasste Schlüsselpunkte aus der ursprünglichen Schlussfolgerung)
häufig gestellte Fragen (zusammengefasste Antworten auf die FAQs)
Hinweis: Die Bilder werden in ihrem ursprünglichen Format und Ort aufbewahrt.
Das obige ist der detaillierte Inhalt vonJina Einbettung V2: Umgang mit langen Dokumenten, die einfach gemacht wurden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Von Reibung zum Fluss: Wie KI juristische Arbeit umsteigtMay 09, 2025 am 11:29 AM
Von Reibung zum Fluss: Wie KI juristische Arbeit umsteigtMay 09, 2025 am 11:29 AMDie Legal Tech -Revolution gewinnt an Dynamik und drängt die Anwaltskräfte, sich aktiv für KI -Lösungen einzusetzen. Passiver Widerstand ist keine praktikable Option mehr für diejenigen, die darauf abzielen, wettbewerbsfähig zu bleiben. Warum ist die Einführung von Technologie entscheidend? Legaler
 Das denkt AI von dir und weiß über dichMay 09, 2025 am 11:24 AM
Das denkt AI von dir und weiß über dichMay 09, 2025 am 11:24 AMViele gehen davon aus, dass Interaktionen mit KI anonym sind, ein starker Kontrast zur menschlichen Kommunikation. AI profiliert jedoch aktiv Benutzer in jedem Chat. Jede Eingabeaufforderung, jedes Wort wird analysiert und kategorisiert. Lassen Sie uns diesen kritischen Aspekt des AI Revo untersuchen
 7 Schritte zum Aufbau einer florierenden, kI-fähigen UnternehmenskulturMay 09, 2025 am 11:23 AM
7 Schritte zum Aufbau einer florierenden, kI-fähigen UnternehmenskulturMay 09, 2025 am 11:23 AMEine erfolgreiche Strategie für künstliche Intelligenz kann nicht von einer starken Unterstützung von Unternehmenskultur getrennt werden. Wie Peter Drucker sagte, hängen Geschäftsbetriebe von Menschen ab, ebenso wie der Erfolg künstlicher Intelligenz. Für Organisationen, die aktiv künstliche Intelligenz einnehmen, ist es entscheidend, eine Unternehmenskultur aufzubauen, die sich an KI anpasst, und sogar den Erfolg oder Misserfolg von AI -Strategien bestimmt. West Monroe hat kürzlich einen praktischen Leitfaden zum Aufbau einer florierenden ki-freundlichen Unternehmenskultur veröffentlicht. Hier einige wichtige Punkte: 1. Klären Sie das Erfolgsmodell von KI: Erstens müssen wir eine klare Vorstellung davon haben, wie KI das Geschäft stärken kann. Eine ideale KI -Betriebskultur kann eine natürliche Integration von Arbeitsprozessen zwischen Menschen und KI -Systemen erreichen. KI ist gut in bestimmten Aufgaben, während Menschen gut in Kreativität und Urteilsvermögen sind
 Netflix New Scroll, META AIs Game Changers, Neuralink im Wert von 8,5 Milliarden US -DollarMay 09, 2025 am 11:22 AM
Netflix New Scroll, META AIs Game Changers, Neuralink im Wert von 8,5 Milliarden US -DollarMay 09, 2025 am 11:22 AMMeta verbessert die AS -Assistant -Bewerbung, und die Ära der tragbaren KI kommt! Die App, die mit ChatGPT konkurrieren soll, bietet Standard -KI -Funktionen wie Text, Sprachinteraktion, Bildgenerierung und Websuche, hat jedoch zum ersten Mal Geolokationsfunktionen hinzugefügt. Dies bedeutet, dass Meta AI weiß, wo Sie sich befinden und was Sie sehen, wenn Sie Ihre Frage beantworten. Es verwendet Ihre Interessen, Standort-, Profil- und Aktivitätsinformationen, um die neuesten Situationsinformationen bereitzustellen, die zuvor nicht möglich waren. Die App unterstützt auch Echtzeitübersetzungen, die das KI-Erlebnis auf Ray-Ban-Brillen vollständig verändert und ihre Nützlichkeit erheblich verbessert. Die Einführung von Zöllen für ausländische Filme ist eine nackte Machtausübung über die Medien und Kultur. Wenn dies implementiert wird, beschleunigt sich dies in Richtung KI und virtueller Produktion
 Machen Sie diese Schritte noch heute, um sich vor AI -Cyberkriminalität zu schützenMay 09, 2025 am 11:19 AM
Machen Sie diese Schritte noch heute, um sich vor AI -Cyberkriminalität zu schützenMay 09, 2025 am 11:19 AMKünstliche Intelligenz revolutioniert das Gebiet der Cyberkriminalität, was uns dazu zwingt, neue Verteidigungsfähigkeiten zu erlernen. Cyberkriminelle verwenden zunehmend mächtige Technologien für künstliche Intelligenz wie tiefe Fälschung und intelligente Cyberangriffe in einem beispiellosen Maßstab. Es wird berichtet, dass 87% der globalen Unternehmen im vergangenen Jahr auf AI -Cyberkriminalität gerichtet waren. Wie können wir es vermeiden, Opfer dieser Welle intelligenter Verbrechen zu werden? Lassen Sie uns untersuchen, wie Sie Risiken identifizieren und Schutzmaßnahmen auf individueller und organisatorischer Ebene ergreifen können. Wie Cyberkriminale künstliche Intelligenz verwenden Im Laufe der Technologie suchen Kriminelle ständig nach neuen Wegen, um Einzelpersonen, Unternehmen und Regierungen anzugreifen. Die weit verbreitete Verwendung künstlicher Intelligenz mag der jüngste Aspekt sein, aber sein potenzieller Schaden ist beispiellos. Insbesondere künstliche Intelligenz
 Ein symbiotischer Tanz: Navigieren von Schleifen künstlicher und natürlicher WahrnehmungMay 09, 2025 am 11:13 AM
Ein symbiotischer Tanz: Navigieren von Schleifen künstlicher und natürlicher WahrnehmungMay 09, 2025 am 11:13 AMDie komplizierte Beziehung zwischen künstlicher Intelligenz (KI) und menschlicher Intelligenz (NI) wird am besten als Rückkopplungsschleife verstanden. Menschen erstellen KI und schulen sie für Daten, die von menschlicher Aktivitäten erzeugt werden, um die Fähigkeiten des Menschen zu verbessern oder zu replizieren. Diese KI
 KIs größtes Geheimnis - Schöpfer verstehen es nicht, Experten teilen sichMay 09, 2025 am 11:09 AM
KIs größtes Geheimnis - Schöpfer verstehen es nicht, Experten teilen sichMay 09, 2025 am 11:09 AMDie jüngste Aussage von Anthropic, die den Mangel an Verständnis in Bezug auf modernste KI-Modelle hervorhebt, hat eine hitzige Debatte unter Experten ausgelöst. Ist diese Opazität eine echte technologische Krise oder einfach eine vorübergehende Hürde auf dem Weg zu mehr Soph
 Bulbul-V2 von Sarvam AI: Indiens bestes TTS-ModellMay 09, 2025 am 10:52 AM
Bulbul-V2 von Sarvam AI: Indiens bestes TTS-ModellMay 09, 2025 am 10:52 AMIndien ist ein vielfältiges Land mit einem reichhaltigen Wandteppich an Sprachen, das in Regionen nahtlose Kommunikation in den Regionen zu einer anhaltenden Herausforderung macht. Sarvams Bulbul-V2 trägt jedoch dazu bei, diese Lücke mit seinem fortschrittlichen Text-zu-Sprach (TTS) t zu schließen


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Dreamweaver CS6
Visuelle Webentwicklungstools

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

