



Seit seiner Einführung im Jahr 2018 hat Bert die Verarbeitung natürlicher Sprache verändert. Es funktioniert bei Aufgaben wie Stimmungsanalyse, Fragenbeantwortung und Sprachinferenz. Mithilfe von bidirektionalem Training und transformatorbasiertem Selbstbegegnung führte Bert eine neue Möglichkeit ein, die Beziehungen zwischen Wörtern im Text zu verstehen. Trotz seines Erfolgs hat Bert Einschränkungen. Es kämpft mit der Recheneffizienz, dem Umgang mit längeren Texten und der Bereitstellung von Interpretierbarkeit. Dies führte zur Entwicklung von Modernbert, einem Modell, das diese Herausforderungen bewältigen soll. Modernbert verbessert die Verarbeitungsgeschwindigkeit, verarbeitet längere Texte besser und bietet Entwicklern mehr Transparenz. In diesem Artikel werden wir untersuchen, wie Modernbert für die Stimmungsanalyse verwendet wird, um seine Funktionen und Verbesserungen gegenüber Bert hervorzuheben.
Lernziel
- kurze Einführung in Bert und warum Modernbert ins Leben gerufen wurde
- Verstehen Sie die Merkmale von Modernbert
- wie man Modernbert praktisch per Sentimentanalyse -Beispiel
- implementiert implementiert
Dieser Artikel wurde als Teil des Data Science -Blogathon veröffentlicht.
- Inhaltsverzeichnis
- Was ist Bert?
- Was ist Modernbert? Fragen
- Was ist Bert?
- Bert, das für bidirektionale Encoder-Darstellungen von Transformers steht, ist seit seiner Einführung durch Google im Jahr 2018 ein Game-Changer. Bert führte das Konzept des bidirektionalen Trainings ein, das es dem Modell ermöglichte, den Kontext zu verstehen, indem sie umgebende Wörter in alle Richtungen betrachteten. Dies führte zu einer deutlich besseren Leistung von Modellen für eine Reihe von NLP -Aufgaben, einschließlich Fragenbeantwortung, Stimmungsanalyse und Sprachinferenz. Die Architektur von Bert basiert nur auf Encoder-Transformatoren, die Selbstbewegungsmechanismen verwenden, um den Einfluss verschiedener Wörter in einem Satz abzuwägen und nur Encoder zu haben. Dies bedeutet, dass sie Eingaben nur verstehen und codieren und keine Ausgabe rekonstruieren oder generieren. So ist Bert hervorragend darin, kontextbezogene Beziehungen im Text aufzunehmen und sie zu einem der mächtigsten und am häufigsten übernommenen NLP -Modelle in den letzten Jahren zu machen.
- Was ist Modernbert?
- Trotz des bahnbrechenden Erfolgs von Bert hat es bestimmte Einschränkungen. Einige von ihnen sind:
-
- Rechenressourcen: Bertis Ein rechnerisch teures, speicherintensives Modell, das für Echtzeit-Anwendungen ORFOR-Setups mit einer zugänglichen, leistungsstarken Computerinfrastruktur verfügen.
- Kontextlänge: Bert hat ein Kontextfenster mit fester Länge, das bei der Behandlung von Langstreckeneingängen wie langwierigen Dokumenten zu einer Einschränkung wird.
- Interpretierbarkeit: Die Komplexität des Modells macht es weniger interpretierbar als einfachere Modelle, was zu Herausforderungen beim Debugieren und Durchführen von Modifikationen des Modells führt.
- Argumentation des gesunden Menschenverstandes: Bert fehlt dem Argumentieren des gesunden Menschenverstandes und kämpft darum, Kontext, Nuance und logisches Denken über die angegebenen Informationen hinaus zu verstehen.
Bert gegen Modernbert
BERT ModernBERT It has fixed positional embeddings It uses Rotary Positional Embeddings (RoPE) Standard self-attention Flash Attention for improved efficiency It has fixed-length context windows It can support longer contexts with Local-Global Alternating Attention Complex and less interpretable Improved interpretability Primarily trained on English text Primarily trained on English and code data Modernbert befasst sich mit diesen Einschränkungen, indem sie effizientere Algorithmen wie Flash-Aufmerksamkeit und lokal-globales Alternationsaufmerksamkeit einbeziehen, die die Speichernutzung optimieren und die Verarbeitungsgeschwindigkeit verbessern. Darüber hinaus führt Modernbert Verbesserungen ein, um längere Kontextlängen effektiver zu bewältigen, indem Techniken wie Rotationspositionseinbettung (Seil) integriert werden, um längere Kontextlängen zu unterstützen.
.
es verbessert die Interpretierbarkeit, indem es darauf abzielt, transparenter und benutzerfreundlicher zu sein, wodurch es den Entwicklern das Debuggen und die Anpassung des Modells an bestimmte Aufgaben erleichtert. Darüber hinaus beinhaltet Modernbert Fortschritte im gesunden Menschenverstand und ermöglicht es, Kontext, Nuancen und logische Beziehungen besser zu verstehen, die über die ausdrücklichen Informationen hinausgehen. Es ist für gemeinsame GPUs wie Nvidia T4, A100 und RTX 4090 geeignet.
Modernbert wird auf Daten aus verschiedenen englischen Quellen geschult, einschließlich Webdokumenten, Code und wissenschaftlichen Artikeln. Es ist im Gegensatz zu den in früheren Encodern beliebten Standard-20-40-Wiederholungen, die in früheren Encodern beliebt sind, ausgebildet.Es wird in den folgenden Größen veröffentlicht:
- Modernbert-Base mit 22 Ebenen und 149 Millionen Parametern
- modernbert-large mit 28 Schichten und 395 Millionen Parametern
Verständnis der Merkmale von Modernbert
Einige der einzigartigen Merkmale von Modernbert sind:
Flash Achtung
Dies ist ein neuer Algorithmus, der den Aufmerksamkeitsmechanismus von Transformatormodellen in Bezug auf Zeit und Speicherverwendung beschleunigt. Die Berechnung der Aufmerksamkeit kann durch Umordnen der Operationen und die Verwendung von Fliesen und Neukomputationen beschleunigt werden. Durch das Fliesen wird große Daten in überschaubare Stücke zerlegt, und die Neukomputation verringert die Speicherverwendung, indem die Zwischenergebnisse nach Bedarf neu berechnet werden. Dies reduziert die quadratische Speicherverwendung auf linear und macht es für lange Sequenzen viel effizienter. Der Rechenaufwand reduziert sich. Es ist 2-4x schneller als herkömmliche Aufmerksamkeitsmechanismen. Die Aufmerksamkeit von Flash wird zur Beschleunigung des Trainings und zur Folgerung von Transformatormodellen verwendet.
Lokal-Global Wechselaufmerksamkeit
Eines der neuesten Merkmale von Modernbert ist eher wechselnde Aufmerksamkeit als die volle globale Aufmerksamkeit.
- Die vollständige Eingabe findet erst nach jeder dritten Schicht teil. Dies ist globale Aufmerksamkeit.
- In der Zwischenzeit haben alle anderen Schichten ein Schiebefenster. In diesem Schiebenfenster kümmert sich jedes Token nur an den nächsten 128 Token. Dies ist lokale Aufmerksamkeit.

Rotationspositionaleinbettung (Seil)
Rotationspositionale Einbettung (Seil) ist eine Transformatormodell -Technik, die die Position von Token in einer Sequenz unter Verwendung von Rotationsmatrizen codiert. Es enthält absolute und relative Positionsinformationen und passt den Aufmerksamkeitsmechanismus an, um die Ordnung und den Abstand zwischen Token zu verstehen. Seil codiert die absolute Position von Token mit einer Rotationsmatrix und notiert auch die relativen Positionsinformationen oder die Reihenfolge und den Abstand zwischen den Token.
Unpadding und Sequenzierung
Unpadding und Sequenzverpackung sind Techniken zur Optimierung des Speichers und der Recheneffizienz.
- Normalerweise wird die Polsterung verwendet, um das längste Token zu finden. Fügen Sie bedeutungslose Polstertoken hinzu, um den Rest kürzerer Sequenzen so zu füllen, dass sie ihren Längen entsprechen. Dies erhöht die Berechnung von bedeutungslosen Token. Unpadding entfernt unnötige Polstertoken aus Sequenzen und verringert die Verschwendung der Berechnung.
- Sequenzpackung organisiert neu organisiert Stapel von Text in kompakte Formulare und gruppiert kürzere Sequenzen zusammen, um die Hardware -Nutzung zu maximieren.
Stimmungsanalyse mit Modernbert
Lassen Sie uns die Stimmungsanalyse mit Modernbert praktisch implementieren. Wir werden mit Modernbert eine Stimmungsanalyseaufgabe ausführen. Die Sentiment -Analyse ist eine spezifische Art von Textklassifizierungsaufgabe, die darauf abzielt, Text in positiv oder negativ zu klassifizieren.
Der Datensatz, den wir verwenden, ist IMDB Movie Reviews Dataset, um Bewertungen entweder in positive oder negative Gefühle zu klassifizieren.
Hinweis:
- Ich habe A100 GPU für eine schnellere Verarbeitung bei Google Colab verwendet. Weitere Informationen finden Sie unter: Antwortdotai/Modernbert-Base .
- Schulungsprozess benötigt einen Wandb -API -Schlüssel. Sie können eine über: Gewicht und Verzerrungen erstellen.
Schritt 1: Installieren Sie die erforderlichen Bibliotheken
Installieren Sie die Bibliotheken, die für die Arbeit mit umarmenden Gesichtstransformatoren erforderlich sind.
#install libraries !pip install git+https://github.com/huggingface/transformers.git datasets accelerate scikit-learn -Uqq !pip install -U transformers>=4.48.0 import torch from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer,AutoModelForMaskedLM,AutoConfig from datasets import load_dataset
Schritt 2: Laden Sie den IMDB -Datensatz mithilfe von Load_Dataset -Funktion
Der Befehl IMDB ["Test"] [0] druckt das erste Beispiel in der Testaufteilung des IMDB Movie Review -Datensatzes, d. H. Die erste Testüberprüfung zusammen mit dem zugehörigen Etikett.
#Load the dataset from datasets import load_dataset imdb = load_dataset("imdb") #print the first test sample imdb["test"][0] Schritt 3: Tokenisierung
ochenisieren Sie den Datensatz mithilfe von vorgebliebenem Modernbert-Base-Tokenizer. Dieser Prozess wandelt Text in numerische Eingänge um, die für das Modell geeignet sind
#initialize the tokenizer and the model tokenizer = AutoTokenizer.from_pretrained("answerdotai/ModernBERT-base") model = AutoModelForMaskedLM.from_pretrained("answerdotai/ModernBERT-base") #define the tokenizer function def tokenizer_function(example): return tokenizer( example["text"], padding="max_length", truncation=True, max_length=512, ## max length can be modified return_tensors="pt" ) #tokenize training and testing data set based on above defined tokenizer function tokenized_train_dataset = imdb["train"].map(tokenizer_function, batched=True) tokenized_test_dataset = imdb["test"].map(tokenizer_function, batched=True) #print the tokenized output of first test sample print(tokenized_test_dataset[0])Schritt 4: Initialisieren Sie das Modernbert-Base-Modell für die Stimmungsklassifizierung
#install libraries !pip install git+https://github.com/huggingface/transformers.git datasets accelerate scikit-learn -Uqq !pip install -U transformers>=4.48.0 import torch from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer,AutoModelForMaskedLM,AutoConfig from datasets import load_dataset
Schritt 5: Bereiten Sie die Datensätze
vorBereiten Sie die Datensätze vor, indem Sie die Spalte für Stimmungsbezeichnungen (Etikett) in "Beschriftungen" umbenennen und unnötige Spalten entfernen.
#Load the dataset from datasets import load_dataset imdb = load_dataset("imdb") #print the first test sample imdb["test"][0]Schritt 6: Rechenmetriken definieren
Verwenden wir F1_Score als Metrik, um unser Modell zu bewerten. Wir werden eine Funktion definieren, um die Bewertungsvorhersagen zu verarbeiten und ihre F1 -Punktzahl zu berechnen. Dadurch vergleichen wir die Vorhersagen des Modells mit den wahren Beschriftungen.
#initialize the tokenizer and the model tokenizer = AutoTokenizer.from_pretrained("answerdotai/ModernBERT-base") model = AutoModelForMaskedLM.from_pretrained("answerdotai/ModernBERT-base") #define the tokenizer function def tokenizer_function(example): return tokenizer( example["text"], padding="max_length", truncation=True, max_length=512, ## max length can be modified return_tensors="pt" ) #tokenize training and testing data set based on above defined tokenizer function tokenized_train_dataset = imdb["train"].map(tokenizer_function, batched=True) tokenized_test_dataset = imdb["test"].map(tokenizer_function, batched=True) #print the tokenized output of first test sample print(tokenized_test_dataset[0])Schritt 7: Setzen Sie die Trainingsargumente
Definieren Sie die Hyperparameter und andere Konfigurationen zur Feinabstimmung des Modells mithilfe von den TrainingsArguments von Hugging Face. Lassen Sie uns einige Argumente verstehen:
- train_bsz, val_bsz : Zeigt die Stapelgröße für das Training und die Validierung an. Die Stapelgröße bestimmt die Anzahl der Stichproben, die vor den internen Parametern des Modells verarbeitet werden.
- lr : Die Lernrate steuert die Anpassung der Gewichte des Modells in Bezug auf den Verlustgradienten.
- Betas : Dies sind die Beta -Parameter für den Adam -Optimierer.
- n_epochs : Anzahl der Epochen, die einen vollständigen Durchgang im gesamten Trainingsdatensatz anzeigen.
- EPS : Eine kleine Konstante, die dem Nenner hinzugefügt wurde, um die numerische Stabilität im Adam -Optimierer zu verbessern.
- wd : steht für Gewichtsverfall, eine Regularisierungstechnik, um eine Überanpassung durch Bewertung großer Gewichte zu verhindern.
#initialize the model config = AutoConfig.from_pretrained("answerdotai/ModernBERT-base") model = AutoModelForSequenceClassification.from_config(config)Schritt 8: Modelltraining
Verwenden Sie die Trainerklasse, um den Modelltraining und den Bewertungsprozess auszuführen.
#data preparation step - train_dataset = tokenized_train_dataset.remove_columns(['text']).rename_column('label', 'labels') test_dataset = tokenized_test_dataset.remove_columns(['text']).rename_column('label', 'labels') Schritt 9: Bewertung
Bewerten Sie das ausgebildete Modell beim Testen des Datensatzes.
import numpy as np from sklearn.metrics import f1_score # Metric helper method def compute_metrics(eval_pred): predictions, labels = eval_pred predictions = np.argmax(predictions, axis=1) score = f1_score( labels, predictions, labels=labels, pos_label=1, average="weighted" ) return {"f1": float(score) if score == 1 else score} Schritt 10: Speichern Sie das fein abgestimmte Modell
speichern Sie das feine Modell und Tokenizer zur weiteren Wiederverwendung.
#define training arguments train_bsz, val_bsz = 32, 32 lr = 8e-5 betas = (0.9, 0.98) n_epochs = 2 eps = 1e-6 wd = 8e-6 training_args = TrainingArguments( output_dir=f"fine_tuned_modern_bert", learning_rate=lr, per_device_train_batch_size=train_bsz, per_device_eval_batch_size=val_bsz, num_train_epochs=n_epochs, lr_scheduler_type="linear", optim="adamw_torch", adam_beta1=betas[0], adam_beta2=betas[1], adam_epsilon=eps, logging_strategy="epoch", eval_strategy="epoch", save_strategy="epoch", load_best_model_at_end=True, bf16=True, bf16_full_eval=True, push_to_hub=False, )Schritt 11: Vorhersage das Gefühl der Überprüfung
Hier: 0 zeigt eine negative Überprüfung an und 1 zeigt eine positive Überprüfung an. Für mein neues Beispiel sollte die Ausgabe [0,1] sein, da das Bohrung eine negative Überprüfung (0) angibt und die spektakuläre positive Meinung zeigt, dass 1 als Ausgabe angegeben wird.
#Create a Trainer instance trainer = Trainer( model=model, # The pre-trained model args=training_args, # Training arguments train_dataset=train_dataset, # Tokenized training dataset eval_dataset=test_dataset, # Tokenized test dataset compute_metrics=compute_metrics, # Personally, I missed this step, my output won't show F1 score ) Einschränkungen von Modernbert
Während Modernbert mehrere Verbesserungen gegenüber dem traditionellen Bert mit sich bringt, hat es immer noch einige Einschränkungen:
- Trainingsdatenverzerrung: Es ist auf Englisch- und Codedaten is betrieben und kann daher nicht so effektiv auf anderen Sprachen oder nicht Code-Text ausgeführt werden.
- Komplexität : Die architektonischen Verbesserungen und neuen Techniken wie Flash-Aufmerksamkeit und Rotationspositionsverbettungen verleihen dem Modell die Komplexität, die es schwieriger machen kann, für bestimmte Aufgaben zu implementieren und zu optimieren.
- Inferenzgeschwindigkeit : Während die Aufmerksamkeit der Flash die Inferenzgeschwindigkeit verbessert, kann das volle 8.192 -Token -Fenster immer noch langsamer sein.
Schlussfolgerung
Modernbert nimmt Berts Fundament und verbessert es mit einer schnelleren Verarbeitung, besserer Handhabung langer Texte und verbesserter Interpretierbarkeit. Während es immer noch Herausforderungen wie Trainingsdatenverzerrungen und Komplexität hat, stellt es einen signifikanten Sprung in NLP dar. Modernbert eröffnet neue Möglichkeiten für Aufgaben wie Stimmungsanalyse und Textklassifizierung, wodurch ein effizienteres und zugänglicheres Verständnis des Sprachgebrauchs gestellt wird.
Key Takeaways
- Modernbert verbessert Bert, indem sie Probleme wie Ineffizienz und begrenzte Kontextbearbeitung beheben.
- Es verwendet Flash -Aufmerksamkeit und Rotationspositions -Einbettungen für eine schnellere Verarbeitung und längere Textunterstützung.
- Modernbert eignet sich hervorragend für Aufgaben wie Stimmungsanalyse und Textklassifizierung.
- Es hat immer noch einige Einschränkungen, wie die Verzerrung von Englisch- und Codedaten.
- Werkzeuge wie Umarmung von Gesicht und Wandb machen es einfach, implementiert und zu bedienen.
Referenzen:
- Modernbert Blog
- Moderbert -Dokumentation
Die in diesem Artikel gezeigten Medien sind nicht im Besitz von Analytics Vidhya und wird nach Ermessen des Autors verwendet.
häufig gestellte Fragen
Q1. Was sind nur Encoder-Architekturen?Ans. Ans. Nur-Encoder-Architekturen Prozesseingangssequenzen ohne Erzeugung von Ausgabesequenzen, die sich auf das Verständnis und die Codierung der Eingabe konzentrieren.
Q2. Was sind Einschränkungen von Bert?Ans. Einige Einschränkungen von Bert umfassen hohe Rechenressourcen, feste Kontextlänge, Ineffizienz, Komplexität und mangelnde Argumentation. Was ist Aufmerksamkeitsmechanismus?
Ans. Ein Aufmerksamkeitsmechanismus ist eine Technik, mit der sich das Modell auf bestimmte Teile der Eingabe konzentriert, um zu bestimmen, welche Teile mehr oder weniger wichtig sind.Q4. Was ist abwechselnde Aufmerksamkeit?
Ans. Dieser Mechanismus wechselt zwischen der Fokussierung auf lokale und globale Kontexte innerhalb von Textsequenzen. Lokale Aufmerksamkeit hebt angrenzende Wörter oder Phrasen hervor und sammelt feinkörnige Informationen, während die globale Aufmerksamkeit allgemeine Muster und Beziehungen im gesamten Text erkennt. Q5. Was sind Rotationspotential -Einbettungen? Wie unterscheiden sie sich von festen Positionseinbettungen?Ans. Im Gegensatz zu festen Positionseinbettungen, die nur absolute Positionen erfassen, verwenden Rotationspositions -Einbettungen (Seil) Rotationsmatrizen, um sowohl absolute als auch relative Positionen zu codieren. Seil ist besser mit erweiterten Sequenzen ab.
Q6. Was sind die potenziellen Anwendungen von Modernbert?Ans. Einige Anwendungen von Modernbert können sich in Bereichen der Textklassifizierung, der Stimmungsanalyse, der Beantwortung der Beantwortung, der Erkennung benannter Entfernung, der Analyse von Rechtstext, dem Verständnis von Code usw.
Q7 befinden. Was und warum wird Wandb -API benötigt?Ans. Gewichte & Vorurteile (W & B) ist eine Plattform zum Verfolgen, Visualisieren und Teilen von ML -Experimenten. Es hilft bei der Verfolgung von Modellmetriken, visualisieren Sie Experimentdaten, teilen Sie Ergebnisse und mehr. Es hilft, Metriken wie Genauigkeit zu überwachen, den Fortschritt zu visualisieren, Hyperparameter zu stimmen, die Versionen von Modell usw. zu verfolgen usw.








Das obige ist der detaillierte Inhalt vonVerbesserung der Stimmungsanalyse mit Modernbert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Sam's Club -Wetten auf KI zur Beseitigung von Quittungsprüfungen und zur Verbesserung des EinzelhandelsApr 22, 2025 am 11:29 AM
Sam's Club -Wetten auf KI zur Beseitigung von Quittungsprüfungen und zur Verbesserung des EinzelhandelsApr 22, 2025 am 11:29 AMRevolutionieren die Erfahrung im Checkout Der innovative "Just Go" -System von Sam's Club baut auf seiner vorhandenen KI-angetriebenen "Scan & Go" -Technologie auf und ermöglicht es den Mitgliedern, während ihres Einkaufsbaus Einkäufe über die Sam's Club-App zu scannen.
 Die AI -Omniverse von Nvidia erweitert sich bei GTC 2025Apr 22, 2025 am 11:28 AM
Die AI -Omniverse von Nvidia erweitert sich bei GTC 2025Apr 22, 2025 am 11:28 AMVerbesserte Vorhersehbarkeit und neue Produktaufstellung von NVIDIA bei GTC 2025 Nvidia, ein wichtiger Akteur in der KI -Infrastruktur, konzentriert sich auf eine erhöhte Vorhersagbarkeit seiner Kunden. Dies beinhaltet eine konsequente Produktlieferung, die Erwartung der Leistungsverwaltung und die Erfüllung der Leistungsverwalter und beinhaltet
 Erkundung der Funktionen der Gemma 2 -Modelle von Google.Apr 22, 2025 am 11:26 AM
Erkundung der Funktionen der Gemma 2 -Modelle von Google.Apr 22, 2025 am 11:26 AMGoogles Gemma 2: Ein leistungsstarkes, effizientes Sprachmodell Die Gemma-Familie von Google von Sprachmodellen, die für Effizienz und Leistung gefeiert wurde
 Die nächste Welle von Genai: Perspektiven mit Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AM
Die nächste Welle von Genai: Perspektiven mit Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AMDiese Führung mit Daten -Episode zeigt Dr. Kirk Borne, einen führenden Datenwissenschaftler, Astrophysiker und TEDX -Sprecher. Dr. Borne, ein renommierter Experte für Big Data, KI und maschinelles Lernen, bietet unschätzbare Einblicke in den aktuellen Zustand und den zukünftigen Traje
 KI für Läufer und Sportler: Wir machen hervorragende FortschritteApr 22, 2025 am 11:12 AM
KI für Läufer und Sportler: Wir machen hervorragende FortschritteApr 22, 2025 am 11:12 AMEs gab einige sehr aufschlussreiche Perspektiven in dieser Rede - Background -Informationen über Ingenieurwesen, die uns zeigten, warum künstliche Intelligenz so gut darin ist, die körperliche Bewegung der Menschen zu unterstützen. Ich werde eine Kernidee aus der Perspektive jedes Mitwirkenden skizzieren, um drei Designaspekte zu demonstrieren, die ein wichtiger Bestandteil unserer Erforschung der Anwendung künstlicher Intelligenz im Sport sind. Edge -Geräte und rohe personenbezogene Daten Diese Vorstellung von künstlicher Intelligenz enthält tatsächlich zwei Komponenten - eine, die sich darauf bezieht, wo wir große Sprachmodelle platzieren, und die andere hängt mit den Unterschieden zwischen unserer menschlichen Sprache und der Sprache zusammen, die unsere Vitalfunktionen „ausdrücken“, wenn sie in Echtzeit gemessen werden. Alexander Amini weiß viel über Laufen und Tennis, aber er immer noch
 Jamie Engstrom über Technologie, Talent und Transformation bei CaterpillarApr 22, 2025 am 11:10 AM
Jamie Engstrom über Technologie, Talent und Transformation bei CaterpillarApr 22, 2025 am 11:10 AMJamie Engstrom, Chief Information Officer und Senior Vice President It, leitet ein globales Team von über 2.200 IT -Fachleuten in 28 Ländern. Mit 26 Jahren in Caterpillar, darunter viereinhalb Jahre in ihrer gegenwärtigen Rolle, Engst
 Neues Google -Fotos Update macht ein Foto mit Ultra HDR -Qualität PopApr 22, 2025 am 11:09 AM
Neues Google -Fotos Update macht ein Foto mit Ultra HDR -Qualität PopApr 22, 2025 am 11:09 AMDas neue Ultra HDR -Tool von Google Photos: Eine schnelle Anleitung Verbessern Sie Ihre Fotos mit dem neuen Ultra HDR-Tool von Google Photos und verwandeln Sie Standardbilder in lebendige Meisterwerke mit hohem Dynamik. Dieses Tool ist ideal für soziale Medien und steigert die Auswirkungen eines Fotos.
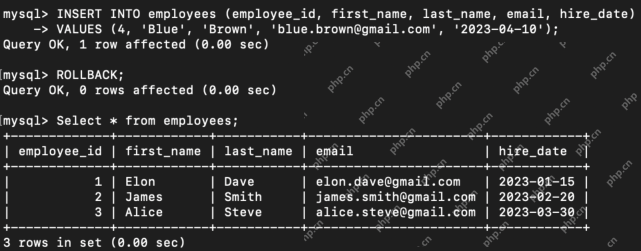 Was sind die TCL -Befehle in SQL? - Analytics VidhyaApr 22, 2025 am 11:07 AM
Was sind die TCL -Befehle in SQL? - Analytics VidhyaApr 22, 2025 am 11:07 AMEinführung Die Befehle der Transaktionskontrollsprache (TCL) sind in SQL für die Verwaltung von Änderungen, die durch Datenmanipulationssprache (DML) angegeben wurden, von wesentlicher Bedeutung. Mit diesen Befehlen können Datenbankadministratoren und Benutzer Transaktionsprozesse kontrollieren, dadurch


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

