
 Technologie-PeripheriegeräteKIUmarmung der Gesichtsbildklassifizierung: Eine umfassende Anleitung mit Beispielen
Technologie-PeripheriegeräteKIUmarmung der Gesichtsbildklassifizierung: Eine umfassende Anleitung mit BeispielenUmarmung der Gesichtsbildklassifizierung: Eine umfassende Anleitung mit Beispielen

Umarmungsgesicht für Bildklassifizierung nutzen: Ein umfassender Leitfaden
Bildklassifizierung, ein Eckpfeiler von KI und maschinellem Lernen, findet Anwendungen in verschiedenen Bereichen, von der Gesichtserkennung bis zur medizinischen Bildgebung. Das Umarmen ist eine leistungsstarke Plattform für diese Aufgabe, insbesondere für diejenigen, die mit natürlicher Sprachverarbeitung (NLP) und zunehmend Computer Vision vertraut sind. Diese Anleitung detailliert detailliert mit dem Umarmungsgesicht für die Bildklassifizierung, die sowohl Anfänger als auch erfahrenen Praktikern sorgt.
Bildklassifizierung verstehen und die Vorteile von Face
umarmtBildklassifizierung umfasst die Kategorisierung von Bildern in vordefinierte Klassen unter Verwendung von Algorithmen, die visuellen Inhalt analysieren und Kategorien basierend auf gelernten Mustern vorhersagen. Faltungsnetzwerke (CNNs) sind aufgrund ihrer Musternerkennungsfunktionen der Standardansatz der Standardansatz. Für einen tieferen Eintauchen in CNNs finden Sie in unserem Artikel "Eine Einführung in die neuronalen Netzwerke (CNNs)". Unser Artikel "Klassifizierung in maschinellem Lernen: Ein Einführung" bietet ein breiteres Verständnis der Klassifizierungsalgorithmen.
Umarmung bietet mehrere Vorteile:

Hauptvorteile der Verwendung von Umarmungen für die Bildklassifizierung
- Zugänglichkeit: Intuitive APIs und umfassende Dokumentation richten sich an alle Qualifikationsstufen.
- Vorausgebildete Modelle: Ein riesiges Repository von vorgeborenen Modellen ermöglicht eine effiziente Feinabstimmung für benutzerdefinierte Datensätze, wodurch die Schulungszeit und die Rechenressourcen minimiert werden. Benutzer können ihre eigenen Modelle trainieren und bereitstellen.
- Community & Support: Eine lebendige Community bietet eine unschätzbare Unterstützung und Fehlerbehebung.
Umarmung Gesicht vereinfacht auch die Modellbereitstellung für wichtige Cloud -Plattformen (AWS, Azure, Google Cloud -Plattform) mit verschiedenen Inferenzoptionen.
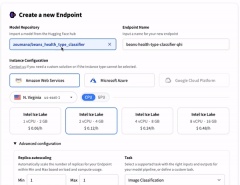
Modellbereitstellungsoptionen für Cloud -Plattformen
Datenvorbereitung und Vorverarbeitung
Dieser Leitfaden verwendet den Umarmungsgesichts -Datensatz "Beans" zur Demonstration. Nach dem Laden visualisieren wir die Daten vor der Vorverarbeitung. Das dazugehörige Google Colab -Notizbuch enthält den Code. Der Code wird durch Umarmung der offiziellen Dokumentation von Face inspiriert.
Bibliotheksanforderungen:
Installieren Sie die erforderlichen Bibliotheken mit PIP:
pip -q install datasets pip -q install transformers=='4.29.0' pip -q install tensorflow=='2.15' pip -q install evaluate pip -q install --upgrade accelerate
starten Sie den Kernel nach der Installation neu. Erforderliche Bibliotheken importieren:
import torch import torchvision import numpy as np import evaluate from datasets import load_dataset from huggingface_hub import notebook_login from torchvision import datasets, transforms from torch.utils.data import DataLoader from transformers import DefaultDataCollator from transformers import AutoImageProcessor from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor from transformers import AutoModelForImageClassification, TrainingArguments, Trainer import matplotlib.pyplot as plt
Datenlade und Organisation:
Laden Sie den Datensatz:
pip -q install datasets pip -q install transformers=='4.29.0' pip -q install tensorflow=='2.15' pip -q install evaluate pip -q install --upgrade accelerate
Der Datensatz enthält 1034 Bilder, jeweils mit 'Image_file_path', 'Bild' (Pil -Objekt) und 'Labels' (0: Angular_leaf_spot, 1: Bean_rust, 2: gesund).
Eine Helferfunktion visualisiert zufällige Bilder:
import torch import torchvision import numpy as np import evaluate from datasets import load_dataset from huggingface_hub import notebook_login from torchvision import datasets, transforms from torch.utils.data import DataLoader from transformers import DefaultDataCollator from transformers import AutoImageProcessor from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor from transformers import AutoModelForImageClassification, TrainingArguments, Trainer import matplotlib.pyplot as plt
visualisieren Sie sechs zufällige Bilder:
beans_train = load_dataset("beans", split="train")

Beispielbilder aus dem Beans -Datensatz
Datenvorverarbeitung:
Teilen Sie den Datensatz (80% Zug, 20% Validierung):
labels_names = {0: "angular_leaf_spot", 1: "bean_rust", 2: "healthy"}
def display_random_images(dataset, num_images=4):
# ... (function code as in original input) ...
Label -Mappings erstellen:
display_random_images(beans_train, num_images=6)
Modelllade und Feinabstimmung
Laden Sie das vorgebildete VIT-Modell:
beans_train = beans_train.train_test_split(test_size=0.2)
Der Code lädt das vorgebildete Modell, definiert Transformationen (Größe, Normalisierung) und bereitet den Datensatz für das Training vor. Die Genauigkeitsmetrik ist für die Bewertung definiert.
Melden Sie sich beim Umarmungsgesicht an:
labels = beans_train["train"].features["labels"].names label2id, id2label = dict(), dict() for i, label in enumerate(labels): label2id[label] = str(i) id2label[str(i)] = label
(Anweisungen auf dem Bildschirm folgen)
Konfigurieren und initiieren Sie das Training:
checkpoint = "google/vit-base-patch16-224-in21k" image_processor = AutoImageProcessor.from_pretrained(checkpoint) # ... (rest of the preprocessing code as in original input) ...
(Trainingsergebnisse, wie im ursprünglichen Eingang gezeigt)
Modellbereitstellung und Integration
Drücken Sie das trainierte Modell in den umarmenden Gesichtszentrum:
notebook_login()
auf das Modell kann dann zugegriffen und verwendet werden über:
- Umarmung des Gesichtsportals: Laden Sie Bilder direkt zur Vorhersage hoch.
- Transformators Library: Verwenden Sie das Modell in Ihrem Python -Code.
- REST -API: Verwenden Sie den bereitgestellten API -Endpunkt für Vorhersagen. Beispiel unter Verwendung der API:
training_args = TrainingArguments(
# ... (training arguments as in original input) ...
)
trainer = Trainer(
# ... (trainer configuration as in original input) ...
)
trainer.train()
Schlussfolgerung und weitere Ressourcen
Dieser Leitfaden bietet eine umfassende Abhandlung der Bildklassifizierung mit dem Umarmungsgesicht. Weitere Lernressourcen umfassen:
- "Eine Einführung in die Verwendung von Transformatoren und Umarmungen"
- "Bildverarbeitung mit Python" -Fertigkeitsspur
- "Was ist Bilderkennung?" Artikel
Dieser Leitfaden ermöglicht den Benutzern aller Ebenen, um das Gesicht für ihre Bildklassifizierungsprojekte zu nutzen.
Das obige ist der detaillierte Inhalt vonUmarmung der Gesichtsbildklassifizierung: Eine umfassende Anleitung mit Beispielen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Kalifornien tippt auf die KI auf die Fast-Track-Waldfeuer-ErholungsgenehmigungenMay 04, 2025 am 11:10 AM
Kalifornien tippt auf die KI auf die Fast-Track-Waldfeuer-ErholungsgenehmigungenMay 04, 2025 am 11:10 AMKI rationalisiert die Waldfeuer -Erholung zulässt es Die KI -Software von Australian Tech -Firma Archistar, die maschinelles Lernen und Computer Vision nutzt, automatisiert die Bewertung der Erstellung von Plänen für die Einhaltung lokaler Vorschriften. Diese Vorvalidation signifikant
 Was die USA aus Estlands KI-betriebener digitaler Regierung lernen könnenMay 04, 2025 am 11:09 AM
Was die USA aus Estlands KI-betriebener digitaler Regierung lernen könnenMay 04, 2025 am 11:09 AMEstlands digitale Regierung: Ein Modell für die USA? Die USA kämpfen mit bürokratischen Ineffizienzen, aber Estland bietet eine überzeugende Alternative. Diese kleine Nation verfügt über eine fast 100% digitalisierte, bürgerzentrierte Regierung, die von der KI betrieben wird. Das ist nicht
 Hochzeitsplanung über generative KIMay 04, 2025 am 11:08 AM
Hochzeitsplanung über generative KIMay 04, 2025 am 11:08 AMDie Planung einer Hochzeit ist eine monumentale Aufgabe, die selbst die am meisten organisierten Paare oft überwältigt. In diesem Artikel, einem Teil einer laufenden Forbes -Serie zu AIs Auswirkungen (siehe Link hier), wird untersucht, wie generative KI die Hochzeitsplanung revolutionieren kann. Die Hochzeit pl
 Was sind Digital Defense AI Agents?May 04, 2025 am 11:07 AM
Was sind Digital Defense AI Agents?May 04, 2025 am 11:07 AMUnternehmen nutzen zunehmend KI -Agenten für den Umsatz, während die Regierungen sie für verschiedene etablierte Aufgaben nutzen. Verbrauchervertreter heben jedoch die Notwendigkeit hervor, dass Einzelpersonen ihre eigenen KI-Agenten als Verteidigung gegen die oft gezogenen
 Ein Leitfaden für Unternehmensleiter zur generativen Motoroptimierung (GEO)May 03, 2025 am 11:14 AM
Ein Leitfaden für Unternehmensleiter zur generativen Motoroptimierung (GEO)May 03, 2025 am 11:14 AMGoogle führt diese Verschiebung an. Die Funktion "KI -Übersichten" bietet bereits mehr als eine Milliarde Nutzer und liefert vollständige Antworten, bevor jemand auf einen Link klickt. [^2] Andere Spieler gewinnen ebenfalls schnell an Boden. Chatgpt, Microsoft Copilot und PE
 Dieses Startup verwendet AI -Agenten, um böswillige Anzeigen und Imitatorkonten zu bekämpfenMay 03, 2025 am 11:13 AM
Dieses Startup verwendet AI -Agenten, um böswillige Anzeigen und Imitatorkonten zu bekämpfenMay 03, 2025 am 11:13 AMIm Jahr 2022 gründete er Social Engineering Defense Startup Doppel, um genau das zu tun. Und da Cybercriminals immer fortgeschrittenere KI -Modelle zum Turbo -Ladung ihrer Angriffe nutzen, haben die KI -Systeme von Doppel dazu beigetragen, sie im Maßstab zu bekämpfen - schneller und
 Wie Weltmodelle die Zukunft der generativen KI und der LLMs radikal umformierenMay 03, 2025 am 11:12 AM
Wie Weltmodelle die Zukunft der generativen KI und der LLMs radikal umformierenMay 03, 2025 am 11:12 AMVoila kann durch die Interaktion mit geeigneten Weltmodellen im Wesentlichen angehoben werden. Reden wir darüber. Diese Analyse eines innovativen KI -Durchbruch
 Mai Tag 2050: Was haben wir gegangen, um zu feiern?May 03, 2025 am 11:11 AM
Mai Tag 2050: Was haben wir gegangen, um zu feiern?May 03, 2025 am 11:11 AMLabor Day 2050. Parks im ganzen Land füllen sich mit Familien, die traditionelle Grillen genießen, während nostalgische Paraden durch die Straßen der Stadt winden. Die Feier hat nun nun eine museumähnliche Qualität-historische Nachstellung als das Gedenken an C


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

