



Bytedance's bahnbrechender Omnihuman-1-Rahmen revolutioniert die menschliche Animation! Dieses neue Modell, das in einem kürzlich erschienenen Forschungsarbeit beschrieben ist, nutzt eine Diffusionstransformator -Architektur, um unglaublich realistische menschliche Videos aus einem einzelnen Bild- und Audioeingang zu erzeugen. Vergessen Sie komplexe Setups - Omnihuman vereinfacht den Prozess und liefert überlegene Ergebnisse. Lassen Sie uns in die Details eintauchen.
Inhaltsverzeichnis
- Einschränkungen vorhandener Animationsmodelle
- Die Omnihuman-1-Lösung: ein multimodaler Ansatz
- Beispiel omnihuman-1-Videos
- Modelltraining und Architektur
- Die Omni-Konditions-Trainingsstrategie
- Experimentelle Validierung und Leistung
- Ablationsstudie: Optimierung des Trainingsprozesses
- erweiterte visuelle Ergebnisse: Vielseitigkeit zeigt
- Schlussfolgerung
Einschränkungen bestehender menschlicher Animationsmodelle
aktuelle menschliche Animationsmodelle leiden häufig unter Einschränkungen. Sie verlassen sich häufig auf kleine, spezialisierte Datensätze, was zu minderwertigen, unflexiblen Animationen führt. Viele kämpfen mit der Verallgemeinerung über verschiedene Kontexte hinweg und fehlen Realismus und Fluidität. Die Abhängigkeit von einzelnen Eingabemodalitäten (z. B. nur Text oder Bild) beschränkt ihre Fähigkeit, die Nuancen der menschlichen Bewegung und des Ausdrucks zu erfassen.
.Die Omnihuman-1-Lösung
omnihuman-1 geht diese Herausforderungen direkt mit einem multimodalen Ansatz vor. Es integriert Text, Audio und Informationen als Konditionierungssignale und erstellen kontextuell reichhaltige und realistische Animationen. Das innovative Omni-Konditionen-Design bewahrt die Identitäts- und Hintergrunddetails der Themen aus dem Referenzbild und gewährleistet die Konsistenz. Eine einzigartige Trainingsstrategie maximiert die Datennutzung und verhindert die Überanpassung und Steigerung der Leistung.

Beispiel omnihuman-1-Videos
omnihuman-1 generiert realistische Videos aus nur einem Bild und Audio. Es kümmert sich um verschiedene visuelle und Audio -Stile und produziert Videos in einem beliebigen Seitenverhältnis und dem Körperanteil. Die resultierenden Animationen enthalten detaillierte Bewegung, Beleuchtung und Texturen. (Hinweis: Referenzbilder werden für die Kürze weggelassen, aber auf Anfrage verfügbar.)
redet
Ihr Browser unterstützt das Video -Tag nicht.
singen
Ihr Browser unterstützt das Video -Tag nicht.
Vielfalt
Ihr Browser unterstützt das Video -Tag nicht.
Halbkörperfälle mit Händen
Ihr Browser unterstützt das Video -Tag nicht.
Modelltraining und Architektur
omnihuman-1s Training nutzt ein Multi-Kondition-Diffusionsmodell. Der Kern ist ein vorgebildetes Seetangmodell (MMDIT-Architektur), das ursprünglich auf allgemeinen Text-Video-Paaren ausgebildet ist. Dies wird dann für die menschliche Videogenerierung durch Integration von Text-, Audio- und Pose -Signalen angepasst. Ein kausaler 3D -Variationsautoencoder (3DVAE) veranstaltet Videos in einen latenten Raum für eine effiziente Denoising. Die Architektur wiederverwendet den Denoising -Prozess geschickt wieder, um die Identität und den Hintergrund der Subjekte aus dem Referenzbild zu erhalten.
Modellarchitekturdiagramm
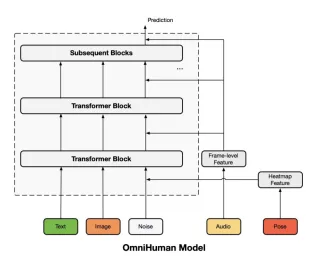
Die Omni-Konditions-Trainingsstrategie
Dieser dreistufige Prozess verfeinert das Diffusionsmodell progressiv. Es führt nach ihrer Bewegungskorrelationsstärke (schwach bis stark) Konditionierungsmodalitäten (Text, Audio, Pose) ein. Dies gewährleistet einen ausgewogenen Beitrag aus jeder Modalität und optimiert die Animationsqualität. Die Audio -Konditionierung verwendet WAV2VEC für die Feature -Extraktion, und die Pose Conditioning integriert Pose -Wärmemaps.

Experimentelle Validierung und Leistung
Das Papier zeigt eine strenge experimentelle Validierung unter Verwendung eines massiven Datensatzes (18,7.000 Stunden von Daten im Zusammenhang mit Menschen). OmniHuman-1 übertrifft vorhandene Methoden über verschiedene Metriken hinweg (IQA, ASE, Sync-C, FID, FVD) und demonstriert seine überlegene Leistung und Vielseitigkeit bei der Behandlung verschiedener Eingangskonfigurationen.
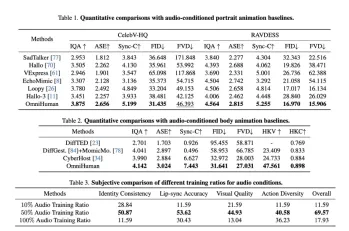
Ablationsstudie: Optimierung des Trainingsprozesses
Die Ablationsstudie untersucht die Auswirkungen verschiedener Trainingsdatenverhältnisse für jede Modalität. Es zeigt optimale Verhältnisse für Audio- und Pose -Daten, den Realismus und den Dynamikbereich aus. Die Studie unterstreicht auch die Bedeutung eines ausreichenden Referenzbildverhältnisses für die Erhaltung von Identität und visueller Treue. Visualisierungen zeigen deutlich die Auswirkungen unterschiedlicher Audio- und Pose -Bedingungenverhältnisse.

Erweiterte visuelle Ergebnisse: Vielseitigkeit zeigt
Die erweiterten visuellen Ergebnisse zeigen die Fähigkeit von Omnihuman-1, verschiedene und qualitativ hochwertige Animationen zu erzeugen und seine Fähigkeit zu markieren, verschiedene Stile, Objektinteraktionen und posegesteuerte Szenarien zu bewältigen.

Schlussfolgerung
omnihuman-1 stellt einen signifikanten Sprung nach vorne in der menschlichen Videogenerierung dar. Seine Fähigkeit, realistische Animationen aus begrenzten Eingaben und seine multimodalen Fähigkeiten zu erstellen, macht es zu einer wirklich bemerkenswerten Leistung. Dieses Modell ist bereit, das Gebiet der digitalen Animation zu revolutionieren.
Das obige ist der detaillierte Inhalt vonBytedance machte nur KI -Videos um das Blasen! - Omnihuman 1. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Warum Sam Altman und andere jetzt Vibes als neues Messgerät für die neuesten Fortschritte in der KI verwendenMay 06, 2025 am 11:12 AM
Warum Sam Altman und andere jetzt Vibes als neues Messgerät für die neuesten Fortschritte in der KI verwendenMay 06, 2025 am 11:12 AMLassen Sie uns die steigende Verwendung von "Vibes" als Bewertungsmetrik im KI -Feld diskutieren. Diese Analyse ist Teil meiner laufenden Forbes -Spalte zu KI -Fortschritten und untersucht komplexe Aspekte der KI -Entwicklung (siehe Link hier). Stimmung in der AI -Bewertung Tradi
 Innerhalb der Waymo -Fabrik baut eine Robotaxi -Zukunft aufMay 06, 2025 am 11:11 AM
Innerhalb der Waymo -Fabrik baut eine Robotaxi -Zukunft aufMay 06, 2025 am 11:11 AMWaymo's Arizona Factory: Massenproduzierende selbstfahrende Jaguare und darüber hinaus Waymo befindet sich in der Nähe von Phoenix, Arizona, und betreibt eine hochmoderne Einrichtung, in der die Flotte autonomer Jaguar I-Pace Electric SUVs produziert wird. Diese 239.000 Quadratmeter große Fabrik wurde eröffnet
 In der datengesteuerten Transformation von S & P Global mit KI im KernMay 06, 2025 am 11:10 AM
In der datengesteuerten Transformation von S & P Global mit KI im KernMay 06, 2025 am 11:10 AMDer Chief Digital Solutions Officer von S & P Global, Jigar Kocherlakota, diskutiert die KI-Reise des Unternehmens, die strategischen Akquisitionen und die zukünftige digitale Transformation. Eine transformative Führungsrolle und ein zukünftiges Team Kocherlakotas Rolle
 Der Aufstieg der Super-Apps: 4 Schritte zum gedigten Ökosystem zum GedeihenMay 06, 2025 am 11:09 AM
Der Aufstieg der Super-Apps: 4 Schritte zum gedigten Ökosystem zum GedeihenMay 06, 2025 am 11:09 AMVon Apps zu Ökosystemen: Navigieren in der digitalen Landschaft Die digitale Revolution geht weit über soziale Medien und KI hinaus. Wir sehen den Aufstieg "Alles -Apps" - kompetente digitale Ökosysteme, die alle Aspekte des Lebens integrieren. Sam a
 MasterCard und Visa entfesseln KI -Agenten, um für Sie einzukaufenMay 06, 2025 am 11:08 AM
MasterCard und Visa entfesseln KI -Agenten, um für Sie einzukaufenMay 06, 2025 am 11:08 AMMasterCards Agent Pay: AI-angetriebene Zahlungen revolutionieren den Handel Während die KI-betriebenen Transaktionsfunktionen von Visa Schlagzeilen machten, hat MasterCard ein fortgeschritteneres AI-natives Zahlungssystem vorgestellt, das auf Tokenisierung, Vertrauen und Agenten basiert
 Unterstützung des mutigen: Future Ventures Transformative Innovation PlaybookMay 06, 2025 am 11:07 AM
Unterstützung des mutigen: Future Ventures Transformative Innovation PlaybookMay 06, 2025 am 11:07 AMFuture Ventures Fund IV: Eine Wette von 200 Millionen US -Dollar auf neuartige Technologien Future Ventures hat kürzlich seinen überzeichneten Fonds IV von insgesamt 200 Millionen US -Dollar geschlossen. Dieser neue Fonds, der von Steve Jurvetson, Maryanna Saenko und Nico Enriquez verwaltet wird, ist eine bedeutende Inv.
 Wenn KI steigt, wechseln Unternehmen von SEO nach GeoMay 05, 2025 am 11:09 AM
Wenn KI steigt, wechseln Unternehmen von SEO nach GeoMay 05, 2025 am 11:09 AMMit der Explosion von AI -Anwendungen wechseln Unternehmen von der herkömmlichen Suchmaschinenoptimierung (SEO) auf generative Motoroptimierung (GEO). Google führt die Verschiebung an. Die Funktion "KI -Übersicht" hat mehr als eine Milliarde Nutzer bedient und vollständige Antworten bereitgestellt, bevor Benutzer auf den Link klicken. [^2] Andere Teilnehmer steigen ebenfalls schnell. Chatgpt, Microsoft Copilot und Verwirrung erstellen eine neue Kategorie „Antwort Engine“, die herkömmliche Suchergebnisse vollständig umgeht. Wenn Ihr Unternehmen in diesen Antworten mit AI-generierten Antworten nicht angezeigt wird, finden Sie potenzielle Kunden möglicherweise nie-auch wenn Sie in herkömmlichen Suchergebnissen hoch rangieren. Von SEO bis Geo - was genau bedeutet das? Jahrzehntelang
 Große Wetten, welche dieser Wege die heutige KI dazu bringen werden, um geschätzte AGI zu werdenMay 05, 2025 am 11:08 AM
Große Wetten, welche dieser Wege die heutige KI dazu bringen werden, um geschätzte AGI zu werdenMay 05, 2025 am 11:08 AMLassen Sie uns die potenziellen Wege zu künstlicher allgemeinen Intelligenz (AGI) untersuchen. Diese Analyse ist Teil meiner laufenden Forbes -Spalte zu KI -Fortschritten, die sich mit der Komplexität der Erreichung von AGI und künstlicher Superintelligence (ASI) befassen. (Siehe verwandte Kunst


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

