

 Technologie-PeripheriegeräteKISo erstellen Sie das QA -Lag -System des Agenten mithilfe des Haystack -Frameworks
Technologie-PeripheriegeräteKISo erstellen Sie das QA -Lag -System des Agenten mithilfe des Haystack -Frameworks
Stellen Sie sich vor, Sie bauen eine KIS -Support -KI auf, die Fragen zu Ihrem Produkt beantworten muss. Manchmal muss es Informationen aus Ihrer Dokumentation ziehen, während es in anderen Fällen das Web nach den neuesten Updates durchsuchen muss. In solchen Arten komplexer KI -Anwendungen sind Agentenlag -Systeme nützlich. Stellen Sie sich sie als intelligente Forschungsassistenten vor, die nicht nur Ihre interne Dokumentation kennen, sondern auch entscheiden, wann Sie im Web suchen sollen. In diesem Leitfaden werden wir mit dem Haystack -Framework durch den Prozess des Aufbaus eines agenten -QA -Lappensystems gehen.
Lernziele
- Wissen, was ein Agenten -LLM ist, und verstehen Sie, wie es sich von einem Lappensystem unterscheidet.
- Machen Sie das Haystack -Framework für agierische LLM -Anwendungen vertraut.
- Verstehen Sie den Prozess des schnellen Erstellens aus einer Vorlage und lernen Sie, wie Sie verschiedene Eingabeaufforderungen zusammenschließen.
- Erfahren Sie, wie Sie ein Einbettung mit Chromadb in Haystack erstellen.
- Erfahren Sie, wie Sie ein vollständiges lokales Entwicklungssystem von der Einbettung in die Generation einrichten.
Dieser Artikel wurde als Teil des Data Science -Blogathon veröffentlicht.
Inhaltsverzeichnis
- Was ist ein agenten llm? Blocks
- Komponenten
- Knoten
- Verbindungsgraphen
- Frage-Answer-RAG-Projekt für höhere Sekundärphysik
- Die Entwicklungsumgebung
- -Dokumentierungskomponenten
Indizing-Dokument für Dokument für die Indexitätsdokumentation - Index-Umgebung
- Indexierungskomponenten
- Indizing-Komponenten erstellen. Pipeline
- Implement a Router
- Create Prompt Templates
- Implement Query Pipeline
- Draw Query Pipeline Graph
- Conclusion
- Was ist ein Agenten LLM?
- Ein Agenten -LLM ist ein KI -System, das autonome Entscheidungen treffen und Maßnahmen ergreifen kann, die auf dem Verständnis der Aufgabe basieren. Im Gegensatz zu herkömmlichen LLMs, die hauptsächlich Textantworten generieren, kann ein Agenten -LLM viel mehr tun.
Agentic LLMS
verlassen sich nicht auf statische Daten oder indizierte Kenntnisse. Sie entscheiden stattdessen, welche Quellen sie vertrauen und wie die besten Erkenntnisse gesammelt werden sollen.Dieser Systemtyp kann auch die richtigen Tools für den Job auswählen. Es kann entscheiden, wann Dokumente abgerufen werden müssen, Berechnungen ausführen oder Aufgaben automatisieren müssen. Was sie auszeichnet, ist seine Fähigkeit, komplexe Probleme in Schritte aufzuteilen und unabhängig auszuführen, was es für Forschung, Analyse und Workflow -Automatisierung wertvoll macht.
rag gegen agentenlag
herkömmliche Lappensysteme folgen einem linearen Prozess. Wenn eine Abfrage empfangen wird, identifiziert das System zunächst die Schlüsselelemente innerhalb der Anfrage. Anschließend sucht es die Wissensbasis und scannt nach relevanten Informationen, die dazu beitragen können, eine genaue Antwort zu entwerfen. Sobald die relevanten Informationen oder Daten abgerufen wurden, verarbeitet das System es, um eine aussagekräftige und kontextbezogene Antwort zu generieren.
Sie können die Prozesse leicht durch das folgende Diagramm verstehen.

Jetzt verbessert ein Agentenlag -System diesen Prozess um:
- Bewertung der Anforderungen an die Abfrage
- entscheiden zwischen mehreren Wissensquellen
- potenziell kombiniert Informationen aus verschiedenen Quellen
- autonome Entscheidungen über die Antwortstrategie treffen
- Bereitstellung von Reaktionen mit Quellenabrechnung
Der Hauptunterschied liegt in der Fähigkeit des Systems, intelligente Entscheidungen darüber zu treffen, wie Abfragen umgehen, anstatt einem Muster der festen Abrufgeneration zu folgen.
Haystack Framework -Komponenten verstehen
Haystack ist ein Open-Source-Rahmen für die Produktionsstätte, LLM-Anwendungen, Lag-Pipelines und Suchsysteme. Es bietet ein leistungsstarkes und flexibles Framework für den Aufbau von LLM -Anwendungen. Sie können Modelle von verschiedenen Plattformen wie Huggingface, Openai, Cohere, Mistral und Local Ollama integrieren. Sie können auch Modelle für Cloud -Dienste wie AWS Sagemaker, Bedrock, Azure und GCP bereitstellen.
Haystack bietet robuste Dokumentspeicher für ein effizientes Datenmanagement. Es verfügt außerdem über eine umfassende Reihe von Tools für die Bewertung, Überwachung und Datenintegration, die eine reibungslose Leistung in allen Schichten Ihrer Anwendung gewährleisten. Es verfügt auch über eine starke Zusammenarbeit in der Gemeinschaft, die regelmäßig neue Service -Integration von verschiedenen Dienstanbietern macht.

Was können Sie mit Haystack bauen?
- Einfach zu vergrößern Sie Ihre Daten mit robustem Abruf- und Generationstechniken.
- Chatbot und Agenten, die aktuelle Genai-Modelle wie GPT-4, LAMA3.2, Deepseek-R1 verwenden.
- generatives multimodales Fragen-Antworten auf gemischte Typen (Bilder, Text, Audio und Tabelle) Wissensbasis.
- Informationsextraktion aus Dokumenten oder Erstellung von Wissensgraphen.
Haystack -Bausteine
Haystack verfügt über zwei Hauptkonzepte zum Aufbau von voll funktionsfähigen Genai -LLM -Systemen - Komponenten und Pipelines. Verstehen wir sie mit einem einfachen Beispiel für Lappen auf japanischen Anime -Charakteren
Komponenten
Komponenten sind die Kernbausteine von Heuhaufen. Sie können Aufgaben wie Dokumentenspeicher, Dokumentenabruf, Textgenerierung und Einbettung ausführen. Haystack verfügt über viele Komponenten, die Sie direkt nach der Installation verwenden können. Es bietet auch APIs, um Ihre eigenen Komponenten durch das Schreiben einer Python -Klasse zu erstellen.
Es gibt eine Sammlung von Integration von Partnerunternehmen und der Community.
Installieren Sie Bibliotheken und setzen Sie Ollama
$ pip install haystack-ai ollama-haystack # On you system download Ollama and install LLM ollama pull llama3.2:3b ollama pull nomic-embed-text # And then start ollama server ollama serve
Importieren Sie einige Komponenten
from haystack import Document, Pipeline from haystack.components.builders.prompt_builder import PromptBuilder from haystack.components.retrievers.in_memory import InMemoryBM25Retriever from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack_integrations.components.generators.ollama import OllamaGenerator
Erstellen Sie ein Dokument und ein Dokumentgeschäft
document_store = InMemoryDocumentStore()
documents = [
Document(
content="Naruto Uzumaki is a ninja from the Hidden Leaf Village and aspires to become Hokage."
),
Document(
content="Luffy is the captain of the Straw Hat Pirates and dreams of finding the One Piece."
),
Document(
content="Goku, a Saiyan warrior, has defended Earth from numerous powerful enemies like Frieza and Cell."
),
Document(
content="Light Yagami finds a mysterious Death Note, which allows him to eliminate people by writing their names."
),
Document(
content="Levi Ackerman is humanity’s strongest soldier, fighting against the Titans to protect mankind."
),
]
Pipeline
Pipelines sind das Rückgrat des Rahmens von Haystack. Sie definieren den Datenfluss zwischen verschiedenen Komponenten. Pipelines sind im Wesentlichen ein gerichteter Acyclic Graph (DAG). Eine einzelne Komponente mit mehreren Ausgängen kann eine Verbindung zu einer anderen einzelnen Komponente mit mehreren Eingängen herstellen.
Sie können Pipeline mit
definierenpipe = Pipeline()
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
pipe.connect("retriever", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
Sie können die Pipeline visualisieren
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
Die Pipeline enthält:
- modulares Workflow -Management
- Anordnung flexible Komponenten
- Einfaches Debuggen und Überwachung
- skalierbare Verarbeitungsarchitektur
Knoten
Knoten sind die grundlegenden Verarbeitungseinheiten, die in einer Pipeline angeschlossen werden können. Diese Knoten sind die Komponenten, die bestimmte Aufgaben ausführen.
Beispiele für Knoten aus der obigen Pipeline
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
Verbindungsgraf
Der ConnectionGraph definiert, wie Komponenten interagieren.
Aus der obigen Pipeline können Sie den Verbindungsdiagramm visualisieren.
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
Das Verbindungsgraphen der Anime -Pipeline

Diese Grafikstruktur:
- definiert den Datenfluss zwischen den Komponenten
- verwaltet Eingabe-/Ausgabesbeziehungen
- Ermöglicht die parallele Verarbeitung, soweit möglich
- erstellt flexible Verarbeitungswege.
Jetzt können wir unsere Anime -Wissensbasis mit der Eingabeaufforderung abfragen.
Erstellen Sie eine Eingabeaufforderung Vorlage
template = """
Given only the following information, answer the question.
Ignore your own knowledge.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ query }}?
"""
Diese Eingabeaufforderung enthält eine Antwort, die Informationen aus der Dokumentbasis entnimmt.
Abfrage mit Eingabeaufforderung und Retriever
query = "How Goku eliminate people?"
response = pipe.run({"prompt_builder": {"query": query}, "retriever": {"query": query}})
print(response["llm"]["replies"])
Antwort:

Dieser Lappen ist für den Newcomer einfach und dennoch konzeptionell wertvoll. Jetzt, da wir die meisten Konzepte von Haystack -Frameworks verstanden haben, können wir in unser Hauptprojekt eintauchen. Wenn etwas Neues auftaucht, werde ich auf dem Weg erklären.
Frage-Answer-Rag-Projekt für höhere Sekundärphysik
Wir werden einen NCERT Physics Books-basierten Frage-Antwortlagen für höhere Sekundärstudenten erstellen. Es wird Antworten auf die Abfrage liefern, indem Informationen aus den NCERT -Büchern entnommen werden. Wenn die Informationen nicht vorhanden sind, wird das Web gesucht, um diese Informationen zu erhalten.
- verwenden
- lokales Lama3.2: 3b oder lama3.2: 1b
- chromadb zum Einbettung von Speicher
- Nomic Embett Textmodell für lokale Einbettung
- DuckDuckgo suchen nach Websuche oder suche (optional)
Ich benutze ein kostenloses, total lokalisiertes System.
Einrichten der Entwicklerumgebung
Wir werden ein Conda Env Python 3.12
$ pip install haystack-ai ollama-haystack # On you system download Ollama and install LLM ollama pull llama3.2:3b ollama pull nomic-embed-text # And then start ollama server ollama serveeinrichten
das erforderliche Paket
from haystack import Document, Pipeline from haystack.components.builders.prompt_builder import PromptBuilder from haystack.components.retrievers.in_memory import InMemoryBM25Retriever from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack_integrations.components.generators.ollama import OllamaGeneratorinstallieren
Erstellen Sie nun ein Projektverzeichnis namens Qagent
.document_store = InMemoryDocumentStore()
documents = [
Document(
content="Naruto Uzumaki is a ninja from the Hidden Leaf Village and aspires to become Hokage."
),
Document(
content="Luffy is the captain of the Straw Hat Pirates and dreams of finding the One Piece."
),
Document(
content="Goku, a Saiyan warrior, has defended Earth from numerous powerful enemies like Frieza and Cell."
),
Document(
content="Light Yagami finds a mysterious Death Note, which allows him to eliminate people by writing their names."
),
Document(
content="Levi Ackerman is humanity’s strongest soldier, fighting against the Titans to protect mankind."
),
]
Sie können einfache Python -Dateien für das Projekt oder das Jupyter -Notizbuch für das Projekt verwenden, das es nicht spielt. Ich werde eine einfache Python -Datei verwenden.
Erstellen Sie eine main.py
Datei auf dem Projektroot.importieren notwendige Bibliotheken
- Systempakete
- Core -Haystack -Komponenten
- chromadb für einbettende Komponenten
- Ollama -Komponenten für lokale Schlussfolgerungen
- und Duckduckgo für Websuche
pipe = Pipeline()
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
pipe.connect("retriever", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
template = """
Given only the following information, answer the question.
Ignore your own knowledge.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ query }}?
"""
Erstellen eines Dokumentgeschäfts
Dokumentgeschäft ist das Wichtigste hier, wir werden unsere Einbettung zum Abrufen speichern, wir verwenden Chromadb
für den Einbettungsgeschäft, und wie Sie im früheren Beispiel sehen können, verwenden wir InmemoryDocumentStore zum schnellen Abruf, weil unsere Daten winzig sind, aber wir werden das Mado -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Memal -Botschaftsschreiber. Starten Sie das System.Die Lösung ist eine Vektor -Datenbank wie Pinecode, Weaaid, Postgres Vector DB oder Chromadb. Ich benutze Chromadb, weil kostenlos, Open-Source, einfach zu bedienen und robust.
query = "How Goku eliminate people?"
response = pipe.run({"prompt_builder": {"query": query}, "retriever": {"query": query}})
print(response["llm"]["replies"])
persist_path
Sie möchten Ihre Einbettung speichern.PDF -Dateien Pfad
$conda create --name agenticlm python=3.12 $conda activate agenticlm
wird eine Liste von Dateien aus dem Datenordner erstellt, der aus unseren PDF -Dateien besteht.
Dokumentvorverarbeitungskomponenten
Wir werden Haystacks integriertes Dokument-Präprozessor wie Reiniger, Splitter und Dateikonverter verwenden und dann einen Autor verwenden, um die Daten in den Speicher zu schreiben.
Reiniger:
es reinigt den zusätzlichen Platz, wiederholte Linien, leere Zeilen usw. aus den Dokumenten.$pip install haystack-ai ollama-haystack pypdf $pip install chroma-haystack duckduckgo-api-haystack
Splitter:
Es wird das Dokument auf verschiedene Weise aufgeteilt, z. B. Wörter, Sätze, Ziffern, Seiten.$md qagent # create dir $cd qagent # change to dir $ code . # open folder in vscode
Dateikonverter:
verwendet das PYPDF, um die PDF in Dokumente zu konvertieren.$ pip install haystack-ai ollama-haystack # On you system download Ollama and install LLM ollama pull llama3.2:3b ollama pull nomic-embed-text # And then start ollama server ollama serve
Schriftsteller: Es wird das Dokument gespeichert, in dem Sie die Dokumente speichern möchten, und für doppelte Dokumente wird es mit vorheriger Überschrift.
überschreiben.from haystack import Document, Pipeline from haystack.components.builders.prompt_builder import PromptBuilder from haystack.components.retrievers.in_memory import InMemoryBM25Retriever from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack_integrations.components.generators.ollama import OllamaGenerator
Stellen Sie nun das Einbettder für die Dokumentindexierung fest.
Einbettder: Nomic Einbett Text
Wir werden Nomic-EMbed-Text-Einbettder verwenden, das sehr effektiv und frei inhugging und Ollama ist.
Bevor Sie Ihre Indizierungspipeline ausführen, öffnen Sie Ihr Terminal und geben Sie unten ein, um das Nomic-EMbed-Text und das LAMA3.2: 3B-Modell aus dem Ollama-Modell Store
document_store = InMemoryDocumentStore()
documents = [
Document(
content="Naruto Uzumaki is a ninja from the Hidden Leaf Village and aspires to become Hokage."
),
Document(
content="Luffy is the captain of the Straw Hat Pirates and dreams of finding the One Piece."
),
Document(
content="Goku, a Saiyan warrior, has defended Earth from numerous powerful enemies like Frieza and Cell."
),
Document(
content="Light Yagami finds a mysterious Death Note, which allows him to eliminate people by writing their names."
),
Document(
content="Levi Ackerman is humanity’s strongest soldier, fighting against the Titans to protect mankind."
),
] zu ziehen
und starten Sie Ollama, indem Sie den Befehl ollama serve
in Ihrem Terminaleingeben
Einbettende Komponentepipe = Pipeline()
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
pipe.connect("retriever", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
Wir verwenden ollamadocumentembedder Komponente zum Einbetten von Dokumenten. Wenn Sie jedoch die Textzeichenfolge einbetten möchten, müssen Sie ollamatextembedder verwenden.
Erstellen von Indexierungspipeline
Wie unser früheres Spielzeuglag -Beispiel werden wir zunächst die Pipeline -Klasse initiieren.
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
Jetzt werden wir die Komponenten zu unserer Pipeline nacheinander hinzufügen
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
Das Hinzufügen von Komponenten in die Pipeline kümmert sich nicht um Reihenfolge. Daher können Sie Komponenten in beliebiger Reihenfolge hinzufügen. Aber eine Verbindung ist es, was zählt.
Verbinden von Komponenten mit dem Pipeline -Diagramm
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
Hier ist die Bestellung von Bedeutung, denn wie Sie die Komponente anschließen, gibt die Pipeline an, wie die Daten durch die Pipeline fließen. Es ist so, dass es keine Rolle spielt, in welcher Reihenfolge oder aus der Stelle, an der Sie Ihre Sanitärartikel kaufen, aber wie man sie zusammenstellt, entscheidet, ob Sie Ihr Wasser bekommen oder nicht.
Der Konverter konvertiert die PDFs und sendet sie zur Reinigung zur Reinigung. Dann sendet der Reiniger die gereinigten Dokumente zum Splitter zum Knacken. Diese Stücke übergeben dann die Eingriffen für die Vektorisierung, und die zuletzt eingebettete übergeben diese Einbettungen an den Verfasser zur Lagerung.
Verstehen Sie! OK, lassen Sie mich Ihnen ein visuelles Diagramm der Indexierung geben, damit Sie den Datenfluss überprüfen können.
template = """
Given only the following information, answer the question.
Ignore your own knowledge.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ query }}?
""" Indexierungspipeline zeichnen
Ja, Sie können leicht ein schönes Meerjungfrau -Diagramm aus der Haystack -Pipeline erstellen.
Diagramm der Indexierungspipeline 
Ich nehme an, Sie haben jetzt die Idee hinter der Heuhaufenspipeline vollständig erfasst. Danken Ihnen Klempner.
Implementieren Sie einen Router Jetzt müssen wir einen Router erstellen, um die Daten über einen anderen Weg zu leiten. In diesem Fall werden wir einen bedingten Router verwenden, der unseren Routing -Job unter bestimmten Bedingungen erledigt.
Der bedingte Router bewertet die Bedingungen basierend auf der Komponentenausgabe. Es wird den Datenfluss durch verschiedene Pipeline-Zweige leiten, die dynamische Entscheidungen ermöglichen. Es wird auch robuste Fallback -Strategien haben.$ pip install haystack-ai ollama-haystack # On you system download Ollama and install LLM ollama pull llama3.2:3b ollama pull nomic-embed-text # And then start ollama server ollama serve
Wenn das System NO_ANswer -Antworten aus dem Einbettungsgeschäftskontext erhält, wird es zu den Web -Such -Tools gilt, um relevante Daten aus dem Internet zu sammeln.
Für die Websuche werden wir Duckduckgo -API verwenden oder hier habe ich DuckDuckgo verwendet.
from haystack import Document, Pipeline from haystack.components.builders.prompt_builder import PromptBuilder from haystack.components.retrievers.in_memory import InMemoryBM25Retriever from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack_integrations.components.generators.ollama import OllamaGenerator
Ok, der größte Teil des schweren Hebens wurde durchgeführt. Jetzt Zeit für schnelle Engineering
Erstellen Sie Eingabeaufforderungsvorlagen
Wir werden die Haystack promptBuilder -Komponente zum Erstellen von Eingabeaufforderungen aus der Vorlage
verwendenErstens erstellen wir eine Eingabeaufforderung für QA
document_store = InMemoryDocumentStore()
documents = [
Document(
content="Naruto Uzumaki is a ninja from the Hidden Leaf Village and aspires to become Hokage."
),
Document(
content="Luffy is the captain of the Straw Hat Pirates and dreams of finding the One Piece."
),
Document(
content="Goku, a Saiyan warrior, has defended Earth from numerous powerful enemies like Frieza and Cell."
),
Document(
content="Light Yagami finds a mysterious Death Note, which allows him to eliminate people by writing their names."
),
Document(
content="Levi Ackerman is humanity’s strongest soldier, fighting against the Titans to protect mankind."
),
]
Es wird den Kontext aus dem Dokument entnommen und versuchen, die Frage zu beantworten. Wenn es jedoch keinen relevanten Kontext in den Dokumenten findet, wird no_answer antworten.
In der zweiten Eingabeaufforderung nutzt das System nach dem Erhalten von NO_answer aus der LLM die Web -Such -Tools, um Kontext aus dem Internet zu sammeln.
DuckDuckgo Eingabeaufforderung
pipe = Pipeline()
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
pipe.connect("retriever", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
Erleichtert das System, zur Websuche zu gehen und die Abfrage zu beantworten.
Erstellen Sie die Eingabeaufforderung mit dem Eingabeaufentwicklungsbuilder aus Haystack
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
Wir werden Haystack -Eingabeaufforderungs -Joiner verwenden, um zusammen mit den Zweigen der Eingabeaufforderung teilzunehmen.
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
Abfragepipeline
implementierenDie Abfragepipeline wird die Kontextressourcen für Abfragen aus den Einbettungen einbetten und unsere Abfrage mit LLM oder Web -Search -Tool beantworten.
ähnelt es der Indexierungspipeline.
Pipeline initiieren
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)
Komponenten zur Abfragepipeline
Hinzufügen von Komponenten addierentemplate = """
Given only the following information, answer the question.
Ignore your own knowledge.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ query }}?
"""
Hier verwenden wir für die LLM -Generation die Ollamagenerator -Komponente, um Antworten mit LLAMA3.2: 3B oder 1B oder was auch immer LLM zu generieren, wenn Tools anrufen.
Verbinden Sie alle Komponenten für den Abfragefluss und die Antwortgenerierung
query = "How Goku eliminate people?"
response = pipe.run({"prompt_builder": {"query": query}, "retriever": {"query": query}})
print(response["llm"]["replies"])
Zusammenfassend der obigen Verbindung:
- Die Einbettung aus dem an die Abfrage des Retriever gesendeten Texts.
- Der Retriever sendet Daten an das Dokument des Eingabeaufforderungs_builders.
- Eingabeaufforderungserbauer Gehen
- Der schnelle Tischler übergibt Daten für die Generation an die LLM. Die Antworten von
- LLM finden Websuche sendet die Daten als Abfrage an eine Websucheingabeaufforderung. Web -Suchdokumente senden Daten an die Websuchdokumente. Die Web -Suchaufforderung sendet die Daten an den Eingabeaufforderung.
- und der prompt -Joiner sendet die Daten zur Antwortgenerierung an die LLM.
- Warum nicht selbst sehen?
- Abfragen -Pipeline -Diagramm zeichnen
Abfraggraf
$conda create --name agenticlm python=3.12 $conda activate agenticlm
Ich weiß, es ist ein riesiges Diagramm, aber es zeigt Ihnen genau, was unter dem Bauch des Tieres vor sich geht.
Jetzt ist es Zeit, die Früchte unserer harten Arbeit zu genießen.
Erstellen Sie eine Funktion für einfache Abfragen.
$ pip install haystack-ai ollama-haystack # On you system download Ollama and install LLM ollama pull llama3.2:3b ollama pull nomic-embed-text # And then start ollama server ollama serve
Es ist eine einfache Funktion für die Antwortgenerierung.
Führen Sie jetzt Ihr Hauptskript aus, um das NCERT Physics Book
zu indizierenfrom haystack import Document, Pipeline from haystack.components.builders.prompt_builder import PromptBuilder from haystack.components.retrievers.in_memory import InMemoryBM25Retriever from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack_integrations.components.generators.ollama import OllamaGenerator
Es ist ein einmaliger Job. Nach der Indexierung müssen Sie diese Zeile kommentieren, da sonst die Bücher wieder in den Vorgang gebracht werden.
und am Ende der Datei schreiben wir unseren Treibercode für die Abfrage
document_store = InMemoryDocumentStore()
documents = [
Document(
content="Naruto Uzumaki is a ninja from the Hidden Leaf Village and aspires to become Hokage."
),
Document(
content="Luffy is the captain of the Straw Hat Pirates and dreams of finding the One Piece."
),
Document(
content="Goku, a Saiyan warrior, has defended Earth from numerous powerful enemies like Frieza and Cell."
),
Document(
content="Light Yagami finds a mysterious Death Note, which allows him to eliminate people by writing their names."
),
Document(
content="Levi Ackerman is humanity’s strongest soldier, fighting against the Titans to protect mankind."
),
]
MCQ über Widerstand aus dem Wissen des Buches

Eine andere Frage, die nicht im Buch
stehtpipe = Pipeline()
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component(
"llm", OllamaGenerator(model="llama3.2:1b", url="http://localhost:11434")
)
pipe.connect("retriever", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
Ausgabe

Versuchen wir eine andere Frage.
image_param = {
"format": "img",
"type": "png",
"theme": "forest",
"bgColor": "f2f3f4",
}
pipe.show(params=image_param)

Also, es funktioniert! Wir können mehr Daten, Bücher oder PDFs zum Einbetten verwenden, um mehr kontextbezogene Antworten zu erzielen. Außerdem werden LLMs wie GPT-4O, Anthropics Claude oder andere Cloud-LLMs den Job noch besser machen.
Schlussfolgerung
Unser Agentenlag -System zeigt die Flexibilität und Robustheit des Heuheustack -Frameworks mit seiner Kraft, Komponenten und Pipelines zu kombinieren. Dieser Lappen kann durch Bereitstellung auf der Web-Service-Plattform und der Verwendung besser bezahlter LLM wie OpenAI und Nthropic hergestellt werden. Sie können eine Benutzeroberfläche mit streamlit- oder react-basierten Web-Spa für ein besseres Benutzererlebnis erstellen.
Sie finden alle im Artikel verwendeten Code hier.
Key Takeaways
- Agentenlappensysteme liefern intelligentere und flexiblere Reaktionen als herkömmlicher Lappen.
- Haystacks Pipeline -Architektur ermöglicht komplexe, modulare Workflows.
- Router ermöglichen eine dynamische Entscheidungsfindung als Reaktionsgenerierung.
- Verbindungsdiagramme liefern flexible und wartbare Wechselwirkungen zwischen Komponenten.
- Integration mehrerer Wissensquellen verbessert die Reaktionsqualität.
Die in diesem Artikel gezeigten Medien sind nicht im Besitz von Analytics Vidhya und wird nach Ermessen des Autors .
verwendet.häufig gestellte Frage Q1. Wie handelt das System mit unbekannten Abfragen?
a. Das System verwendet seine Routerkomponente, um automatisch auf die Websuche zurückzukehren, wenn lokales Wissen nicht ausreicht, um eine umfassende Abdeckung zu gewährleisten. Q2. Welche Vorteile bietet die Pipeline -Architektur?
a. Die Pipeline -Architektur ermöglicht die modulare Entwicklung, einfache Tests und flexible Komponentenanordnung, wodurch das System aufrechterhalten und erweiterbar ist. Q3. Wie verbessert der Verbindungsdiagramm die Systemfunktionalität?
a. Das Verbindungsdiagramm ermöglicht komplexe Datenflüsse und parallele Verarbeitung, Verbesserung der Systemeffizienz und Flexibilität beim Umgang mit verschiedenen Arten von Abfragen.
Q4. Kann ich andere LLM -APIs verwenden?a. Ja, es ist sehr einfach, einfach das erforderliche Integrationspaket für die jeweilige LLM -API wie Gemini, Anthropic und COQ zu installieren und es mit Ihren API -Tasten zu verwenden.
Das obige ist der detaillierte Inhalt vonSo erstellen Sie das QA -Lag -System des Agenten mithilfe des Haystack -Frameworks. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!Mar 20, 2025 pm 03:34 PMDie Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 So verwenden Sie Dall-E 3: Tipps, Beispiele und FunktionenMar 09, 2025 pm 01:00 PM
So verwenden Sie Dall-E 3: Tipps, Beispiele und FunktionenMar 09, 2025 pm 01:00 PMDall-e 3: Ein generatives KI-Bilderstellungstool Generative AI revolutioniert die Erstellung von Inhalten, und Dall-E 3, das neueste Bildgenerierungsmodell von OpenAI, steht vor der Spitze. Veröffentlicht im Oktober 2023 baut es auf seinen Vorgängern Dall-E und Dall-E 2 auf
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!Mar 22, 2025 am 10:58 AMFebruar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?Mar 22, 2025 am 11:07 AMYolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
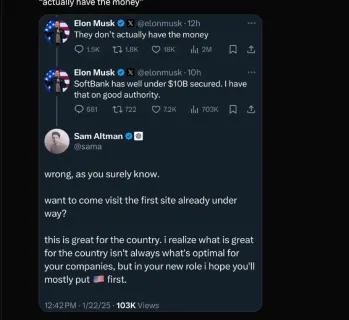 Elon Musk & Sam Altman kämpfen über 500 Milliarden US -Dollar Stargate -ProjektMar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman kämpfen über 500 Milliarden US -Dollar Stargate -ProjektMar 08, 2025 am 11:15 AMDas 500 -Milliarden -Dollar -Stargate AI -Projekt, das von Tech -Giganten wie Openai, Softbank, Oracle und Nvidia unterstützt und von der US -Regierung unterstützt wird, zielt darauf ab, die amerikanische KI -Führung zu festigen. Dieses ehrgeizige Unternehmen verspricht eine Zukunft, die von AI Advanceme geprägt ist
 Sora vs Veo 2: Welches erstellt realistischere Videos?Mar 10, 2025 pm 12:22 PM
Sora vs Veo 2: Welches erstellt realistischere Videos?Mar 10, 2025 pm 12:22 PMGoogle's Veo 2 und Openais Sora: Welcher AI -Videogenerator regiert oberste? Beide Plattformen erzeugen beeindruckende KI -Videos, aber ihre Stärken liegen in verschiedenen Bereichen. Dieser Vergleich unter Verwendung verschiedener Eingabeaufforderungen zeigt, welches Werkzeug Ihren Anforderungen am besten entspricht. T
 Gencast von Google: Wettervorhersage mit Gencast Mini DemoMar 16, 2025 pm 01:46 PM
Gencast von Google: Wettervorhersage mit Gencast Mini DemoMar 16, 2025 pm 01:46 PMGencast von Google Deepmind: Eine revolutionäre KI für die Wettervorhersage Die Wettervorhersage wurde einer dramatischen Transformation unterzogen, die sich von rudimentären Beobachtungen zu ausgefeilten AI-angetriebenen Vorhersagen überschreitet. Google DeepMinds Gencast, ein Bodenbrei
 Welche KI ist besser als Chatgpt?Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?Mar 18, 2025 pm 06:05 PMDer Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

