


Imagin 3: Ein Python-Tutorial für die Erzeugung von Text-zu-Image-Erzeugung
Imaging 3 ist ein leistungsstarkes Text-zu-Image-Modell, das hochdetaillierte und stilistisch unterschiedliche Bilder generieren kann und sogar Text einbezieht. Dieses Tutorial zeigt, wie die Funktionen von Imagin 3 programmgesteuert mithilfe der generativen AI -API von Google und Python nutzen können. Wir werden die Umgebungs -Setup, die Code -Implementierung abdecken und verschiedene Optionen für Bildgenerierung untersuchen.
Zugriff auf Imageen 3 über die Google Generative AI API
Sie benötigen zu Beginn ein Google Cloud -Projekt und einen API -Schlüssel.
Einrichten Ihrer Google Cloud -Umgebung:
- Google Cloud -Konsole: Greifen Sie auf die Google Cloud -Konsole zu und melden Sie sich an.
- Neues Projekt: Erstellen Sie ein neues Projekt (z. B. "Image-Tutorial").
- Projektdetails: Füllen Sie die erforderlichen Projektdetails ein. Das Unternehmensfeld ist optional.

API -Schlüsselgenerierung:
- Navigieren Sie zur API -Tastaturseite in Google AI Studio.
- Klicken Sie auf "API -Schlüssel erstellen."
- Wählen Sie Ihr neu erstelltes Projekt aus und klicken Sie auf "Erstellen".
-
Speichern Sie Ihre API -Taste sicher.
.env
<code>GEMINI_API_KEY=<your_api_key></your_api_key></code>Abrechnungskonto Setup:
Imagin 3 ist ein bezahlter Service. Verbinden Sie ein Abrechnungskonto mit Ihrem Google Cloud -Projekt, um API -Nutzungsfehler zu vermeiden. Befolgen Sie die Eingabeaufforderungen in Google AI Studio, um ein Abrechnungskonto zu verknüpfen oder zu erstellen. Die aktuellen Kosten pro Bildgenerierung beträgt 0,03 USD (überprüfen Sie die offizielle Preisseite auf die neuesten Preise).

- Installieren Sie Anaconda:
- Anaconda herunterladen und installieren Sie von der offiziellen Website. Umgebung erstellen:
-
conda create -n imagen python=3.9 Umgebung aktivieren: -
conda activate imagen Pakete installieren: -
pip install -q -U google-genai pillow python-dotenv
Erstellen Sie ein Python -Skript (z. B.
) im selben Verzeichnis wie Ihre Datei. gen_image.py
.env
# Import necessary libraries
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
import os
from dotenv import load_dotenv
# Load API key from .env
load_dotenv()
api_key = os.getenv("GEMINI_API_KEY")
# Initialize the client
client = genai.Client(api_key=api_key)
# Generate an image
prompt = """A dog surfing at the beach"""
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(number_of_images=1)
)
# Display the image
for generated_image in response.generated_images:
image = Image.open(BytesIO(generated_image.image.image_bytes))
image.show()

Das Objekt
ermöglicht die Anpassung:-
number_of_images: Mehrere Bilder generieren (Standard: 4). -
aspect_ratio: Kontrolle des Seitenverhältnisses (z. B. "9:16" für vertikale Bilder). -
safety_filter_level: Derzeit unterstützt derzeit nurBLOCK_LOW_AND_ABOVE. -
person_generation: Kontrolle, ob Personen im Bild zulässig sind (ALLOW_ADULToderDONT_ALLOW).
Effektive Eingabeaufforderung Engineering:
Basteln effektive Eingabeaufforderungen sind entscheidend. Verwenden Sie die beschreibende Sprache, geben Sie Stile an und fügen Sie Details zu Beleuchtung, Kameraeinstellungen und künstlerischen Techniken hinzu, um bessere Ergebnisse zu erzielen. In der offiziellen Dokumentation 3 -Dokumentation finden Sie detaillierte Eingabeaufentwicklungsrichtlinien.
Bildbearbeitung und -anpassung (derzeit eingeschränkter Zugriff):
Imagin 3 bietet Bildbearbeitungs- und Anpassungsfunktionen, aber der Zugriff ist derzeit eingeschränkt.
Schlussfolgerung:
Dieses Tutorial bietet eine Grundlage für die Verwendung von Imageen 3 über die Google Generative AI API und Python. Experimentieren Sie mit unterschiedlichen Eingabeaufforderungen und Konfigurationsoptionen, um das volle Potenzial dieses leistungsstarken Text-zu-Image-Modells freizuschalten. Denken Sie daran, immer die offizielle Dokumentation auf die aktuellsten Informationen und Preise zu überprüfen.
Das obige ist der detaillierte Inhalt vonBild 3: Eine Anleitung mit Beispielen in der Gemini -API. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Eine KI -Weltraumfirma wird geborenMay 12, 2025 am 11:07 AM
Eine KI -Weltraumfirma wird geborenMay 12, 2025 am 11:07 AMDieser Artikel zeigt, wie KI die Weltraumindustrie revolutioniert und morgen.IO als Hauptbeispiel revolutioniert. Im Gegensatz zu etablierten Weltraumunternehmen wie SpaceX, die nicht mit KI im Kern gebaut wurden, ist Tomorrow.io ein KI-nativer Unternehmen. Lassen Sie uns erkunden
 10 Praktika für maschinelles Lernen in Indien (2025)May 12, 2025 am 10:47 AM
10 Praktika für maschinelles Lernen in Indien (2025)May 12, 2025 am 10:47 AMLegen Sie Ihr Traummaschinen -Lernpraktikum in Indien (2025)! Für Studenten und Fachkräfte für die frühen Karriere ist ein Praktikum für maschinelles Lernen das perfekte Launchpad für eine lohnende Karriere. Indische Unternehmen in verschiedenen Sektoren-von modernen Gena
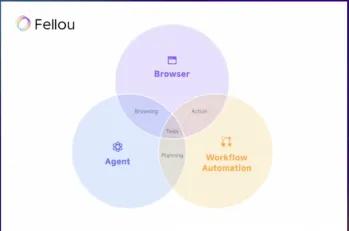 Versuchen Sie Fellou Ai und verabschieden Sie sich von Google und ChatgptMay 12, 2025 am 10:26 AM
Versuchen Sie Fellou Ai und verabschieden Sie sich von Google und ChatgptMay 12, 2025 am 10:26 AMDie Landschaft des Online -Surfens hat im vergangenen Jahr eine bedeutende Transformation erfahren. Diese Verschiebung begann mit verbesserten, personalisierten Suchergebnissen von Plattformen wie Verwirrigkeit und Copilot und wurde mit der Integration von Webs durch Chatgpt beschleunigt
 Persönliches Hacking wird ein ziemlich heftiger Bär seinMay 11, 2025 am 11:09 AM
Persönliches Hacking wird ein ziemlich heftiger Bär seinMay 11, 2025 am 11:09 AMCyberangriffe entwickeln sich weiter. Vorbei sind die Tage generischer Phishing -E -Mails. Die Zukunft der Cyberkriminalität ist hyperpersonalisiert und nutzt leicht verfügbare Online-Daten und KI, um hoch gezielte Angriffe zu erzeugen. Stellen Sie sich einen Betrüger vor, der Ihren Job kennt, Ihr F.
 Papst Leo XIV zeigt, wie KI seine Namenswahl beeinflusst hatMay 11, 2025 am 11:07 AM
Papst Leo XIV zeigt, wie KI seine Namenswahl beeinflusst hatMay 11, 2025 am 11:07 AMIn seiner Eröffnungsrede an das College of Cardinals diskutierte der in Chicago geborene Robert Francis Prevost, der neu gewählte Papst Leo XIV, den Einfluss seines Namensvetters, Papst Leo XIII., Dessen Papsttum (1878-1903) mit der Dämmerung des Automobils und der Dämmerung des Automobils und des Automobils zusammenfiel
 FASTAPI -MCP -Tutorial für Anfänger und Experten - Analytics VidhyaMay 11, 2025 am 10:56 AM
FASTAPI -MCP -Tutorial für Anfänger und Experten - Analytics VidhyaMay 11, 2025 am 10:56 AMDieses Tutorial zeigt, wie Sie Ihr großes Sprachmodell (LLM) mit dem Modellkontextprotokoll (MCP) und Fastapi in externe Tools integrieren. Wir erstellen eine einfache Webanwendung mit Fastapi und konvertieren sie in einen MCP -Server, um Ihr L zu aktivieren
 DIA-1.6B TTS: Bestes Modell zur Generierung von Text zu Dialogue-Analytics VidhyaMay 11, 2025 am 10:27 AM
DIA-1.6B TTS: Bestes Modell zur Generierung von Text zu Dialogue-Analytics VidhyaMay 11, 2025 am 10:27 AMEntdecken Sie DIA-1.6B: Ein bahnbrechendes Text-zu-Sprach-Modell, das von zwei Studenten ohne Finanzierung entwickelt wurde! Dieses 1,6 -Milliarden -Parametermodell erzeugt eine bemerkenswert realistische Sprache, einschließlich nonverbaler Hinweise wie Lachen und Niesen. Dieser Artikelhandbuch
 3 Wege KI kann Mentoring sinnvoller als je zuvor machenMay 10, 2025 am 11:17 AM
3 Wege KI kann Mentoring sinnvoller als je zuvor machenMay 10, 2025 am 11:17 AMIch stimme voll und ganz zu. Mein Erfolg ist untrennbar mit der Anleitung meiner Mentoren verbunden. Ihre Einsichten, insbesondere in Bezug auf das Geschäftsmanagement, bildeten das Fundament meiner Überzeugungen und Praktiken. Diese Erfahrung unterstreicht mein Engagement für Mentor


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

Dreamweaver Mac
Visuelle Webentwicklungstools

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

