

 Web-Frontendjs-TutorialBereinigen Sie HTML-Inhalte für die Retrieval-Augmented Generation mit Readability.js
Web-Frontendjs-TutorialBereinigen Sie HTML-Inhalte für die Retrieval-Augmented Generation mit Readability.jsBereinigen Sie HTML-Inhalte für die Retrieval-Augmented Generation mit Readability.js

Web Scraping ist eine gängige Methode zum Sammeln von Inhalten für Ihre RAG-Anwendung (Retrieval-Augmented Generation). Das Parsen von Webseiteninhalten kann jedoch eine Herausforderung sein.
Mozillas Open-Source-Bibliothek Readability.js bietet eine praktische Lösung zum Extrahieren nur der wesentlichen Teile einer Webseite. Lassen Sie uns die Integration in eine Datenaufnahmepipeline für eine RAG-Anwendung untersuchen.
Unstrukturierte Daten aus Webseiten extrahieren
Webseiten sind reichhaltige Quellen unstrukturierter Daten, ideal für RAG-Anwendungen. Webseiten enthalten jedoch häufig irrelevante Informationen wie Kopfzeilen, Seitenleisten und Fußzeilen. Dieser zusätzliche Inhalt ist zwar nützlich zum Durchsuchen, lenkt jedoch vom Hauptthema der Seite ab.
Für optimale RAG-Daten müssen irrelevante Inhalte entfernt werden. Während Tools wie Cheerio HTML basierend auf der bekannten Struktur einer Website analysieren können, ist dieser Ansatz für das Scraping verschiedener Website-Layouts ineffizient. Um nur relevante Inhalte zu extrahieren, ist eine robuste Methode erforderlich.
Nutzung der Reader View-Funktionalität
Die meisten Browser verfügen über eine Leseransicht, die alles außer dem Titel und Inhalt des Artikels entfernt. Das folgende Bild veranschaulicht den Unterschied zwischen dem Standard-Browsing und dem Lesemodus, der auf einen DataStax-Blogbeitrag angewendet wird:

Mozilla stellt Readability.js, die Bibliothek hinter dem Lesemodus von Firefox, als eigenständiges Open-Source-Modul bereit. Dadurch können wir Readability.js in eine Datenpipeline integrieren, um irrelevante Inhalte zu entfernen und die Scraping-Ergebnisse zu verbessern.
Scraping von Daten mit Node.js und Readability.js
Lassen Sie uns den Scraping-Artikelinhalt aus einem früheren Blogbeitrag über das Erstellen von Vektoreinbettungen in Node.js veranschaulichen. Der folgende JavaScript-Code ruft den HTML-Code der Seite ab:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
Dazu gehört der gesamte HTML-Code, einschließlich Navigation, Fußzeilen und andere auf Websites übliche Elemente.
Alternativ können Sie Cheerio verwenden, um bestimmte Elemente auszuwählen:
npm install cheerio
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
Dies ergibt den Titel und den Artikeltext. Dieser Ansatz setzt jedoch die Kenntnis der HTML-Struktur voraus, was nicht immer machbar ist.
Ein besserer Ansatz besteht in der Installation von Readability.js und jsdom:
npm install @mozilla/readability jsdom
Readability.js arbeitet in einer Browserumgebung und erfordert, dass jsdom dies in Node.js simuliert. Wir können den geladenen HTML-Code in ein Dokument konvertieren und Readability.js verwenden, um den Inhalt zu analysieren:
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
Das article-Objekt enthält verschiedene analysierte Elemente:
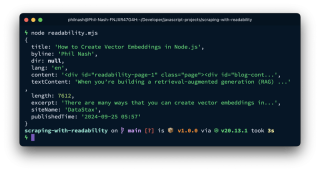
Dazu gehören der Titel, der Autor, der Auszug, der Zeitpunkt der Veröffentlichung sowie sowohl HTML (content) als auch einfacher Text (textContent). textContent ist bereit für die Aufteilung, Einbettung und Speicherung, während content Links und Bilder zur weiteren Verarbeitung behält.
Mit der Funktion isProbablyReaderable können Sie feststellen, ob das Dokument für Readability.js geeignet ist:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
Ungeeignete Seiten sollten zur Überprüfung markiert werden.
Integration der Lesbarkeit mit LangChain.js
Readability.js lässt sich nahtlos in LangChain.js integrieren. Das folgende Beispiel verwendet LangChain.js, um eine Seite zu laden, Inhalte mit MozillaReadabilityTransformer zu extrahieren, Text mit RecursiveCharacterTextSplitter zu teilen, Einbettungen mit OpenAI zu erstellen und Daten in Astra DB zu speichern.
Erforderliche Abhängigkeiten:
npm install cheerio
Sie benötigen Astra DB-Anmeldeinformationen ( ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_API_ENDPOINT) und einen OpenAI-API-Schlüssel (OPENAI_API_KEY) als Umgebungsvariablen.
Notwendige Module importieren:
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
Komponenten initialisieren:
npm install @mozilla/readability jsdom
Dokumente laden, transformieren, teilen, einbetten und speichern:
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
Verbesserte Web-Scraping-Genauigkeit mit Readability.js
Readability.js, eine robuste Bibliothek, die den Lesemodus von Firefox unterstützt, extrahiert effizient relevante Daten aus Webseiten und verbessert so die RAG-Datenqualität. Es kann direkt oder über MozillaReadabilityTransformer.
Dies ist nur die Anfangsphase Ihrer Aufnahmepipeline. Chunking, Einbettung und Astra DB-Speicher sind nachfolgende Schritte beim Erstellen Ihrer RAG-Anwendung.
Verwenden Sie andere Methoden zum Bereinigen von Webinhalten in Ihren RAG-Anwendungen? Teilen Sie Ihre Techniken!
Das obige ist der detaillierte Inhalt vonBereinigen Sie HTML-Inhalte für die Retrieval-Augmented Generation mit Readability.js. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 JavaScript -Datentypen: Gibt es einen Unterschied zwischen Browser und NodeJs?May 14, 2025 am 12:15 AM
JavaScript -Datentypen: Gibt es einen Unterschied zwischen Browser und NodeJs?May 14, 2025 am 12:15 AMJavaScript -Kerndatentypen sind in Browsern und Knoten.js konsistent, werden jedoch unterschiedlich als die zusätzlichen Typen behandelt. 1) Das globale Objekt ist ein Fenster im Browser und global in node.js. 2) Node.js 'eindeutiges Pufferobjekt, das zur Verarbeitung von Binärdaten verwendet wird. 3) Es gibt auch Unterschiede in der Leistung und Zeitverarbeitung, und der Code muss entsprechend der Umgebung angepasst werden.
 JavaScript -Kommentare: Eine Anleitung zur Verwendung // und / * * /May 13, 2025 pm 03:49 PM
JavaScript -Kommentare: Eine Anleitung zur Verwendung // und / * * /May 13, 2025 pm 03:49 PMJavaScriptUSESTWOTYPESOFCOMMENMENTEN: Einzelzeilen (//) und Multi-Linie (//). 1) Verwendung // Forquicknotesorsingle-Linexplanationen.2 Verwendung // ForlongerExPlanationsCompomentingingoutblocks-
 Python gegen JavaScript: Eine vergleichende Analyse für EntwicklerMay 09, 2025 am 12:22 AM
Python gegen JavaScript: Eine vergleichende Analyse für EntwicklerMay 09, 2025 am 12:22 AMDer Hauptunterschied zwischen Python und JavaScript sind die Typ -System- und Anwendungsszenarien. 1. Python verwendet dynamische Typen, die für wissenschaftliche Computer- und Datenanalysen geeignet sind. 2. JavaScript nimmt schwache Typen an und wird in Front-End- und Full-Stack-Entwicklung weit verbreitet. Die beiden haben ihre eigenen Vorteile bei der asynchronen Programmierung und Leistungsoptimierung und sollten bei der Auswahl gemäß den Projektanforderungen entschieden werden.
 Python vs. JavaScript: Auswählen des richtigen Tools für den JobMay 08, 2025 am 12:10 AM
Python vs. JavaScript: Auswählen des richtigen Tools für den JobMay 08, 2025 am 12:10 AMOb die Auswahl von Python oder JavaScript vom Projekttyp abhängt: 1) Wählen Sie Python für Datenwissenschafts- und Automatisierungsaufgaben aus; 2) Wählen Sie JavaScript für die Entwicklung von Front-End- und Full-Stack-Entwicklung. Python ist für seine leistungsstarke Bibliothek in der Datenverarbeitung und -automatisierung bevorzugt, während JavaScript für seine Vorteile in Bezug auf Webinteraktion und Full-Stack-Entwicklung unverzichtbar ist.
 Python und JavaScript: Verständnis der Stärken der einzelnenMay 06, 2025 am 12:15 AM
Python und JavaScript: Verständnis der Stärken der einzelnenMay 06, 2025 am 12:15 AMPython und JavaScript haben jeweils ihre eigenen Vorteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1. Python ist leicht zu erlernen, mit prägnanter Syntax, die für Datenwissenschaft und Back-End-Entwicklung geeignet ist, aber eine langsame Ausführungsgeschwindigkeit hat. 2. JavaScript ist überall in der Front-End-Entwicklung und verfügt über starke asynchrone Programmierfunktionen. Node.js macht es für die Entwicklung der Vollstapel geeignet, die Syntax kann jedoch komplex und fehleranfällig sein.
 JavaScripts Kern: Ist es auf C oder C aufgebaut?May 05, 2025 am 12:07 AM
JavaScripts Kern: Ist es auf C oder C aufgebaut?May 05, 2025 am 12:07 AMJavaScriptisnotbuiltoncorc; Es ist angehört, dass sich JavaScriptWasdedeSthatrunsonGineoFtencninc.
 JavaScript-Anwendungen: Von Front-End bis Back-EndMay 04, 2025 am 12:12 AM
JavaScript-Anwendungen: Von Front-End bis Back-EndMay 04, 2025 am 12:12 AMJavaScript kann für die Entwicklung von Front-End- und Back-End-Entwicklung verwendet werden. Das Front-End verbessert die Benutzererfahrung durch DOM-Operationen, und die Back-End-Serveraufgaben über node.js. 1. Beispiel für Front-End: Ändern Sie den Inhalt des Webseitentextes. 2. Backend Beispiel: Erstellen Sie einen Node.js -Server.
 Python vs. JavaScript: Welche Sprache sollten Sie lernen?May 03, 2025 am 12:10 AM
Python vs. JavaScript: Welche Sprache sollten Sie lernen?May 03, 2025 am 12:10 AMDie Auswahl von Python oder JavaScript sollte auf Karriereentwicklung, Lernkurve und Ökosystem beruhen: 1) Karriereentwicklung: Python ist für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet, während JavaScript für die Entwicklung von Front-End- und Full-Stack-Entwicklung geeignet ist. 2) Lernkurve: Die Python -Syntax ist prägnant und für Anfänger geeignet; Die JavaScript -Syntax ist flexibel. 3) Ökosystem: Python hat reichhaltige wissenschaftliche Computerbibliotheken und JavaScript hat ein leistungsstarkes Front-End-Framework.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

