

 Backend-EntwicklungPython-TutorialVergleichende Analyse von Klassifizierungstechniken: Naive Bayes, Entscheidungsbäume und Zufallswälder
Backend-EntwicklungPython-TutorialVergleichende Analyse von Klassifizierungstechniken: Naive Bayes, Entscheidungsbäume und Zufallswälder
Dinosaurier-Geheimnisse mit maschinellem Lernen entschlüsseln: Ein Modellvergleich
Maschinelles Lernen ermöglicht es uns, verborgene Muster in Daten aufzudecken, was zu aufschlussreichen Vorhersagen und Lösungen für reale Probleme führt. Lassen Sie uns diese Kraft erforschen, indem wir sie auf die faszinierende Welt der Dinosaurier anwenden! In diesem Artikel werden drei beliebte Modelle für maschinelles Lernen – Naive Bayes, Decision Trees und Random Forests – verglichen, während sie einen einzigartigen Dinosaurier-Datensatz bearbeiten. Wir werden durch die Datenexploration, Vorbereitung und Modellbewertung gehen und dabei die Leistung jedes Modells und die gewonnenen Erkenntnisse hervorheben.
-
Dinosaurier-Datensatz: Eine prähistorische Schatzkammer
Unser Datensatz ist eine umfangreiche Sammlung von Dinosaurierinformationen, einschließlich Ernährung, geologischer Periode, Standort und Größe. Jeder Eintrag stellt einen einzigartigen Dinosaurier dar und bietet eine Mischung aus kategorialen und numerischen Daten, die zur Analyse bereit sind.

Schlüsselattribute:
- Name: Dinosaurierart (kategorisch).
- Ernährung:Ernährungsgewohnheiten (z. B. Pflanzenfresser, Fleischfresser).
- Zeitraum:Geologischer Existenzzeitraum.
- gelebt_in:Geografische Region bewohnt.
- Länge: Ungefähre Größe (numerisch).
- Taxonomie:Taxonomische Klassifikation.
Datensatzquelle: Jurassic Park – Der umfassende Dinosaurier-Datensatz
-
Datenvorbereitung und -exploration: Aufdeckung prähistorischer Trends
2.1 Datensatzübersicht:
Unsere erste Analyse ergab ein Klassenungleichgewicht, wobei Pflanzenfresser deutlich zahlreicher sind als andere Ernährungstypen. Dieses Ungleichgewicht stellte eine Herausforderung dar, insbesondere für das Naive-Bayes-Modell, das von einer gleichberechtigten Klassenrepräsentation ausgeht.
2.2 Datenbereinigung:
Um die Datenqualität sicherzustellen, haben wir Folgendes durchgeführt:
- Imputation fehlender Werte mit geeigneten statistischen Methoden.
- Identifizierung und Verwaltung von Ausreißern in numerischen Attributen wie „Länge“.
2.3 Explorative Datenanalyse (EDA):
EDA enthüllte faszinierende Muster und Zusammenhänge:
- Pflanzenfressende Dinosaurier kamen in der Jurazeit häufiger vor.
- Es gab erhebliche Größenunterschiede zwischen verschiedenen Arten, was sich im Attribut „Länge“ widerspiegelt.
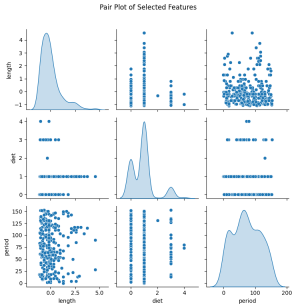
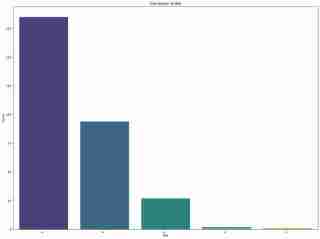
-
Feature Engineering: Verfeinerung der Daten für optimale Leistung
Um die Modellgenauigkeit zu verbessern, haben wir Feature-Engineering-Techniken eingesetzt:
- Skalierung und Normalisierung:Standardisierte numerische Merkmale (wie „Länge“) für konsistente Modelleingabe.
- Funktionsauswahl: Priorisierte einflussreiche Attribute wie „Ernährung“, „Taxonomie“ und „Zeitraum“, um sich auf die relevantesten Daten zu konzentrieren.
-
Modelltraining und Leistungsvergleich: Ein prähistorischer Showdown
Unser Hauptziel war es, die Leistung von drei Modellen im Dinosaurier-Datensatz zu vergleichen.
4.1 Naive Bayes:
Dieses Wahrscheinlichkeitsmodell geht von Merkmalsunabhängigkeit aus. Seine Einfachheit macht es recheneffizient, aber seine Leistung litt unter dem Klassenungleichgewicht des Datensatzes, was zu weniger genauen Vorhersagen für unterrepräsentierte Klassen führte.
4.2 Entscheidungsbaum:
Entscheidungsbäume zeichnen sich durch die Erfassung nichtlinearer Beziehungen durch hierarchische Verzweigung aus. Es schnitt besser ab als Naive Bayes und identifizierte komplexe Muster effektiv. Es zeigte sich jedoch eine Anfälligkeit für eine Überanpassung, wenn die Baumtiefe nicht sorgfältig kontrolliert wurde.
4.3 Zufälliger Wald:
Diese Ensemble-Methode, die mehrere Entscheidungsbäume kombiniert, erwies sich als die robusteste. Durch die Aggregation von Vorhersagen wurde eine Überanpassung minimiert und die Komplexität des Datensatzes effektiv gehandhabt, wodurch höchste Genauigkeit erreicht wurde.
-
Ergebnisse und Analyse: Interpretation der Ergebnisse
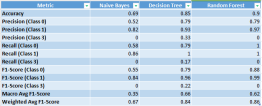
Wichtige Erkenntnisse:
- Random Forest erzielte über alle Metriken hinweg eine überragende Genauigkeit und ausgewogene Leistung und demonstrierte damit seine Stärke im Umgang mit komplexen Dateninteraktionen.
- Decision Tree zeigte eine angemessene Leistung, blieb jedoch bei der Vorhersagegenauigkeit leicht hinter Random Forest zurück.
- Naive Bayes hatte mit den unausgeglichenen Daten zu kämpfen, was zu einer geringeren Genauigkeit und geringeren Erinnerung führte.
Herausforderungen und zukünftige Verbesserungen:
- Die Behebung von Klassenungleichgewichten mithilfe von Techniken wie SMOTE oder Resampling könnte die Modellleistung für unterrepräsentierte Dinosauriertypen verbessern.
- Hyperparameter-Tuning für Entscheidungsbäume und Zufallswälder könnte die Genauigkeit weiter verbessern.
- Die Erforschung alternativer Ensemble-Methoden wie Boosting könnte zusätzliche Erkenntnisse liefern.

Fazit: Eine Reise durch Zeit- und Datenwissenschaft
Diese vergleichende Analyse zeigte die unterschiedliche Leistung von Modellen für maschinelles Lernen an einem einzigartigen Dinosaurier-Datensatz. Der Prozess, von der Datenaufbereitung bis zur Modellevaluierung, zeigte die Stärken und Grenzen jedes einzelnen auf:
- Naive Bayes:Einfach und schnell, aber empfindlich gegenüber Klassenungleichgewichten.
- Entscheidungsbaum: Interpretierbar und intuitiv, aber anfällig für Überanpassung.
- Random Forest: Der genaueste und robusteste, der die Leistungsfähigkeit des Ensemble-Lernens hervorhebt.
Random Forest erwies sich als das zuverlässigste Modell für diesen Datensatz. Zukünftige Forschungen werden fortschrittliche Techniken wie Boosting und verfeinertes Feature-Engineering untersuchen, um die Vorhersagegenauigkeit weiter zu verbessern.
Viel Spaß beim Codieren! ?
Weitere Informationen finden Sie in meinem GitHub-Repository.
Das obige ist der detaillierte Inhalt vonVergleichende Analyse von Klassifizierungstechniken: Naive Bayes, Entscheidungsbäume und Zufallswälder. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AMPython eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AMSie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AM
Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AMPython wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PMSie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AMWie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AM
Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AMWie kann man nicht erkannt werden, wenn Sie Fiddlereverywhere für Man-in-the-Middle-Lesungen verwenden, wenn Sie FiddLereverywhere verwenden ...
 Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AM
Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AMLaden Sie Gurkendateien in Python 3.6 Umgebungsbericht Fehler: ModulenotFoundError: Nomodulennamen ...
 Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AM
Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AMWie löste ich das Problem der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse? Wenn wir malerische Spot -Kommentare und -analysen durchführen, verwenden wir häufig das Jieba -Word -Segmentierungstool, um den Text zu verarbeiten ...


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

