



Ein praktischer Leitfaden zum Aufbau einer Data-Engineering-ETL-Pipeline. Dieser Leitfaden bietet einen praktischen Ansatz zum Verständnis und zur Implementierung der Grundlagen des Data Engineering und deckt die Bereiche Speicherung, Verarbeitung, Automatisierung und Überwachung ab.
Was ist Data Engineering?
Data Engineering konzentriert sich auf die Organisation, Verarbeitung und Automatisierung von Datenworkflows, um Rohdaten in wertvolle Erkenntnisse für die Analyse und Entscheidungsfindung umzuwandeln. Dieser Leitfaden behandelt:
- Datenspeicherung: Definieren, wo und wie Daten gespeichert werden.
- Datenverarbeitung:Techniken zur Bereinigung und Transformation von Rohdaten.
- Workflow-Automatisierung:Implementierung einer nahtlosen und effizienten Workflow-Ausführung.
- Systemüberwachung:Gewährleistung der Zuverlässigkeit und des reibungslosen Betriebs der gesamten Datenpipeline.
Lassen Sie uns jede Phase erkunden!
Einrichten Ihrer Entwicklungsumgebung
Bevor wir beginnen, stellen Sie sicher, dass Sie Folgendes haben:
-
Umgebungseinrichtung:
- Ein Unix-basiertes System (macOS) oder ein Windows-Subsystem für Linux (WSL).
- Python 3.11 (oder höher) installiert.
- PostgreSQL-Datenbank installiert und lokal ausgeführt.
-
Voraussetzungen:
- Grundlegende Befehlszeilenkenntnisse.
- Grundlegende Python-Programmierkenntnisse.
- Administratorrechte für die Softwareinstallation und -konfiguration.
-
Architektonischer Überblick:


Das Diagramm veranschaulicht die Interaktion zwischen den Pipeline-Komponenten. Dieses modulare Design nutzt die Stärken jedes Tools: Airflow für die Workflow-Orchestrierung, Spark für die verteilte Datenverarbeitung und PostgreSQL für die strukturierte Datenspeicherung.
-
Notwendige Tools installieren:
- PostgreSQL:
brew update brew install postgresql
- PySpark:
brew install apache-spark
- Luftstrom:
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
- PostgreSQL:
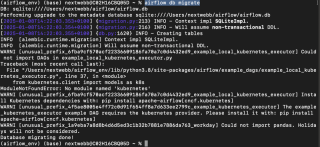
Sobald die Umgebung vorbereitet ist, gehen wir näher auf die einzelnen Komponenten ein.
1. Datenspeicherung: Datenbanken und Dateisysteme
Datenspeicherung ist die Grundlage jeder Data-Engineering-Pipeline. Wir betrachten zwei Hauptkategorien:
-
Datenbanken: Effizient organisierte Datenspeicherung mit Funktionen wie Suche, Replikation und Indizierung. Beispiele hierfür sind:
- SQL-Datenbanken: Für strukturierte Daten (z. B. PostgreSQL, MySQL).
- NoSQL-Datenbanken: Für schemalose Daten (z. B. MongoDB, Redis).
- Dateisysteme:Geeignet für unstrukturierte Daten, bietet weniger Funktionen als Datenbanken.
PostgreSQL einrichten
- Starten Sie den PostgreSQL-Dienst:
brew update brew install postgresql

- Erstellen Sie eine Datenbank, verbinden Sie sich und erstellen Sie eine Tabelle:
brew install apache-spark
- Beispieldaten einfügen:
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
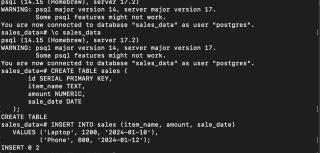
Ihre Daten sind jetzt sicher in PostgreSQL gespeichert.
2. Datenverarbeitung: PySpark und verteiltes Computing
Datenverarbeitungs-Frameworks verwandeln Rohdaten in umsetzbare Erkenntnisse. Apache Spark ist mit seinen verteilten Rechenfunktionen eine beliebte Wahl.
-
Verarbeitungsmodi:
- Stapelverarbeitung: Verarbeitet Daten in Stapeln fester Größe.
- Stream-Verarbeitung: Verarbeitet Daten in Echtzeit.
- Gemeinsame Tools:Apache Spark, Flink, Kafka, Hive.
Datenverarbeitung mit PySpark
- Java und PySpark installieren:
brew services start postgresql
- Daten aus einer CSV-Datei laden:
Erstellen Sie eine sales.csv Datei mit den folgenden Daten:
CREATE DATABASE sales_data;
\c sales_data
CREATE TABLE sales (
id SERIAL PRIMARY KEY,
item_name TEXT,
amount NUMERIC,
sale_date DATE
);
Verwenden Sie das folgende Python-Skript, um die Daten zu laden und zu verarbeiten:
INSERT INTO sales (item_name, amount, sale_date)
VALUES ('Laptop', 1200, '2024-01-10'),
('Phone', 800, '2024-01-12');

- Hochwertige Verkäufe filtern:
brew install openjdk@11 && brew install apache-spark


-
Postgres-DB-Treiber einrichten: Laden Sie bei Bedarf den PostgreSQL-JDBC-Treiber herunter und aktualisieren Sie den Pfad im Skript unten.
-
Verarbeitete Daten in PostgreSQL speichern:
brew update brew install postgresql


Die Datenverarbeitung mit Spark ist abgeschlossen.
3. Workflow-Automatisierung: Airflow
Automatisierung optimiert das Workflow-Management durch Planung und Abhängigkeitsdefinition. Tools wie Airflow, Oozie und Luigi erleichtern dies.
Automatisierung von ETL mit Airflow
- Luftstrom initialisieren:
brew install apache-spark


- Erstellen Sie einen Workflow (DAG):
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
Dieser DAG wird täglich ausgeführt, führt das PySpark-Skript aus und enthält einen Überprüfungsschritt. Bei Fehlern werden E-Mail-Benachrichtigungen gesendet.
-
Überwachen Sie den Arbeitsablauf: Platzieren Sie die DAG-Datei im
dags/-Verzeichnis von Airflow, starten Sie die Airflow-Dienste neu und überwachen Sie sie über die Airflow-Benutzeroberfläche unterhttp://localhost:8080.
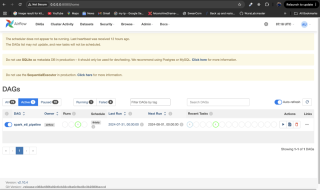
4. Systemüberwachung
Überwachung gewährleistet die Zuverlässigkeit der Pipeline. Die Alarmierung von Airflow oder die Integration mit Tools wie Grafana und Prometheus sind wirksame Überwachungsstrategien. Verwenden Sie die Airflow-Benutzeroberfläche, um Aufgabenstatus und Protokolle zu überprüfen.
Fazit
Sie haben gelernt, die Datenspeicherung einzurichten, Daten mit PySpark zu verarbeiten, Arbeitsabläufe mit Airflow zu automatisieren und Ihr System zu überwachen. Datentechnik ist ein entscheidender Bereich, und dieser Leitfaden bietet eine solide Grundlage für die weitere Erforschung. Denken Sie daran, die bereitgestellten Referenzen für detailliertere Informationen zu konsultieren.
Das obige ist der detaillierte Inhalt vonGrundlagen des Data Engineering: Ein praktischer Leitfaden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AMPython eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AMSie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AM
Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AMPython wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PMSie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AMWie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AM
Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AMWie kann man nicht erkannt werden, wenn Sie Fiddlereverywhere für Man-in-the-Middle-Lesungen verwenden, wenn Sie FiddLereverywhere verwenden ...
 Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AM
Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AMLaden Sie Gurkendateien in Python 3.6 Umgebungsbericht Fehler: ModulenotFoundError: Nomodulennamen ...
 Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AM
Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AMWie löste ich das Problem der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse? Wenn wir malerische Spot -Kommentare und -analysen durchführen, verwenden wir häufig das Jieba -Word -Segmentierungstool, um den Text zu verarbeiten ...


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Dreamweaver Mac
Visuelle Webentwicklungstools

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

PHPStorm Mac-Version
Das neueste (2018.2.1) professionelle, integrierte PHP-Entwicklungstool

