

 Backend-EntwicklungPython-TutorialVorhersage der Chemie von NBA-Spielern mithilfe graphischer neuronaler Netze
Backend-EntwicklungPython-TutorialVorhersage der Chemie von NBA-Spielern mithilfe graphischer neuronaler NetzeVorhersage der Chemie von NBA-Spielern mithilfe graphischer neuronaler Netze


Hallo zusammen, mein Name ist sea_turt1e.
In diesem Artikel werden der Prozess und die Ergebnisse des Aufbaus eines maschinellen Lernmodells zur Vorhersage der Spielerchemie in der National Basketball League (NBA) vorgestellt, einer Sportart, die ich sehr liebe.
Übersicht
- Prognostizieren Sie die Spielerchemie mithilfe von graphischen neuronalen Netzen (GNN).
- Die Fläche unter der Kurve (AUC) wird als Bewertungsmaßstab verwendet.
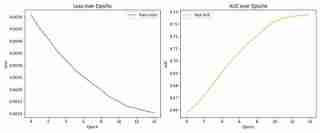
- Die AUC bei Konvergenz beträgt ungefähr 0,73.
- Die Trainingsdaten umfassen die Saison 1996–97 bis zur Saison 2021–22, und die Daten aus der Saison 2022–23 werden für Tests verwendet.
Hinweis: Über NBA
Für Leser, die mit der NBA nicht vertraut sind, sind Teile dieses Artikels möglicherweise schwer zu verstehen. „Chemische Reaktion“ kann aus einer intuitiveren Perspektive verstanden werden. Obwohl sich dieser Artikel auf die NBA konzentriert, könnte die Methode auch auf andere Sportarten und sogar auf die Vorhersage der zwischenmenschlichen Chemie angewendet werden.
Ergebnisse der Vorhersage chemischer Reaktionen
Sehen wir uns zunächst die Vorhersageergebnisse an. Auf den Datensatz und die technischen Details gehe ich später genauer ein.
Erklärung von Seiten und Brüchen
Bei der Vorhersage chemischer Reaktionen weisen rote Kanten auf gute chemische Reaktionen hin, schwarze Kanten auf mäßige chemische Reaktionen und blaue Kanten auf schlechte chemische Reaktionen.
Der Bruch auf der Seite stellt den Wert der chemischen Reaktion dar und reicht von 0 bis 1.
Chemievorhersagen für Starspieler
Hier sind die Chemie-Vorhersagen für Starspieler. Die Grafik enthält nur Paare von Spielern, die nie für dasselbe Team gespielt haben.
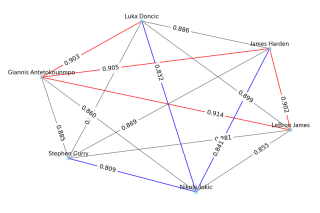
Wenn man sich die Vorhersagen von Starspielern ansieht, die noch nie zusammen gespielt haben, sind die Ergebnisse möglicherweise nicht immer intuitiv.
Beispielsweise zeigten LeBron James und Stephen Curry bei den Olympischen Spielen eine hervorragende Koordination, was auf eine gute Chemie schließen lässt. Auf der anderen Seite wird Nikola Jokic überraschenderweise eine schlechte Chemie mit anderen Spielern vorhergesagt.
Chemievorhersagen für wichtige Trades in der Saison 2022-23
Um die Vorhersagen der Realität näher zu bringen, habe ich die Chemie zwischen den Spielern in tatsächlichen Trades für die Saison 2022-23 getestet.
Da Daten aus der Saison 2022-23 nicht in den Trainingsdaten enthalten sind, können Vorhersagen, die mit realistischen Eindrücken übereinstimmen, Hinweise auf die Wirksamkeit des Modells geben.
In der Saison 2022–23 finden mehrere wichtige Trades statt.
Hier sind die Vorhersagen für Schlüsselspieler, darunter Kevin Durant, Kyrie Irving und Rui Hachimura.
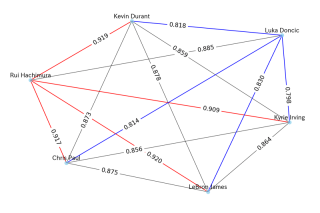
Die Chemie-Prognosen für ihr neues Team lauten wie folgt:
- Lakers: Rui Hachimura – LeBron James (roter Rand: gute Chemie)
- Sonnen: Kevin Durant – Chris Paul (Schwarze Seite: Mittlere Chemie)
- Mavericks: Kyrie Irving – Luka Doncic (blaue Seite: schlechte Chemie)
Diese Ergebnisse scheinen angesichts der Dynamik der Saison 2022-23 ziemlich genau zu sein. (Obwohl sich die Dinge für die Suns und Mavericks in der folgenden Saison änderten.)
Technische Details
Als nächstes werde ich die technischen Aspekte erläutern, einschließlich des GNN-Frameworks und der Datensatzvorbereitung.
Was ist GNN?
GNN (Graph Neural Network) ist ein Netzwerk zur Verarbeitung graphstrukturierter Daten.
In diesem Modell werden „chemische Reaktionen zwischen Spielern“ als Diagrammkanten dargestellt und der Lernprozess ist wie folgt:
- Direkte Seite: Das Spielerpaar mit der höheren Anzahl an Assists.
- Negative Seite: Ein Spielerpaar mit einer geringeren Anzahl an Assists.
Bei negativen Kanten gibt das Modell „Teamkollegen mit geringen Assists“ den Vorrang und schwächt den Einfluss von „Spielern aus verschiedenen Teams“.
Was ist AUC?
AUC (Fläche unter der Kurve) bezieht sich auf die Fläche unter der ROC-Kurve und wird als Metrik zur Bewertung der Modellleistung verwendet.
Je näher die AUC bei 1 liegt, desto höher ist die Genauigkeit. In dieser Studie betrug die AUC des Modells etwa 0,73 – ein mittleres bis überdurchschnittliches Ergebnis.
Lernkurve und AUC-Fortschritt
Das Folgende ist die Lernkurve und der AUC-Fortschritt während des Trainingsprozesses:
Datensatz
Die wesentliche Neuerung liegt in der Konstruktion des Datensatzes.
Um die Chemie zu quantifizieren, gehe ich davon aus, dass „hohe Assists“ eine gute Chemie bedeutet. Basierend auf dieser Annahme ist der Datensatz wie folgt aufgebaut:
- Positiv: Spieler mit vielen Assists.
- Negative Seite: Spieler mit geringen Assists.
Darüber hinaus wird ausdrücklich davon ausgegangen, dass Teamkollegen mit einer geringen Assist-Anzahl eine schlechte Chemie haben.
Codedetails
Der gesamte Code ist auf GitHub verfügbar.
Wenn Sie den Anweisungen in der README-Datei folgen, sollten Sie in der Lage sein, den Trainingsprozess nachzubilden und die hier beschriebenen Diagramme darzustellen.
https://www.php.cn/link/867079fcaff2dfddeb29ca1f27853ef7
Zukunftsausblick
Es gibt noch Raum für Verbesserungen und ich habe vor, folgende Ziele zu erreichen:
-
Erweitern Sie die Definition einer chemischen Reaktion
- Beziehen Sie Faktoren ein, die über die Hilfsmittel hinausgehen, um Spielerbeziehungen genauer zu erfassen.
-
Genauigkeit verbessern
- Verbesserung der AUC durch bessere Trainingsmethoden und erweiterte Datensätze.
-
Integrierte Verarbeitung natürlicher Sprache
- Analysieren Sie Spielerinterviews und Social-Media-Beiträge, um neue Perspektiven hinzuzufügen.
-
Schreiben Sie einen Artikel auf Englisch
- Veröffentlichen Sie Inhalte auf Englisch, um ein breiteres internationales Publikum zu erreichen.
-
Entwicklung einer GUI für die Diagrammvisualisierung
- Erstellen Sie eine Webanwendung, die es Benutzern ermöglicht, die Spielerchemie interaktiv zu erkunden.
Fazit
In diesem Artikel beschreibe ich meine Versuche, die Chemie zwischen NBA-Spielern vorherzusagen.
Während sich das Modell noch in der Entwicklung befindet, hoffe ich, mit weiteren Verbesserungen spannendere Ergebnisse zu erzielen.
Lassen Sie gerne Ihre Gedanken und Vorschläge im Kommentarbereich!
Wenn Sie weitere Verbesserungen benötigen, lassen Sie es mich bitte wissen!
Das obige ist der detaillierte Inhalt vonVorhersage der Chemie von NBA-Spielern mithilfe graphischer neuronaler Netze. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Was sind die Alternativen zur Verkettung von zwei Listen in Python?May 09, 2025 am 12:16 AM
Was sind die Alternativen zur Verkettung von zwei Listen in Python?May 09, 2025 am 12:16 AMEs gibt viele Methoden, um zwei Listen in Python zu verbinden: 1. Verwenden Sie Operatoren, die in großen Listen einfach, aber ineffizient sind; 2. Verwenden Sie die Erweiterungsmethode, die effizient ist, die ursprüngliche Liste jedoch ändert. 3.. Verwenden Sie den operator =, der sowohl effizient als auch lesbar ist; 4. Verwenden Sie die Funktion iterertools.chain, die Speichereffizient ist, aber zusätzlichen Import erfordert. 5. Verwenden Sie List Parsing, die elegant ist, aber zu komplex sein kann. Die Auswahlmethode sollte auf dem Codekontext und den Anforderungen basieren.
 Python: Effiziente Möglichkeiten, zwei Listen zusammenzuführenMay 09, 2025 am 12:15 AM
Python: Effiziente Möglichkeiten, zwei Listen zusammenzuführenMay 09, 2025 am 12:15 AMEs gibt viele Möglichkeiten, Python -Listen zusammenzuführen: 1. Verwenden von Operatoren, die einfach, aber nicht für große Listen effizient sind; 2. Verwenden Sie die Erweiterungsmethode, die effizient ist, die ursprüngliche Liste jedoch ändert. 3. Verwenden Sie iTertools.chain, das für große Datensätze geeignet ist. 4. Verwenden Sie * Operator, fusionieren Sie kleine bis mittelgroße Listen in einer Codezeile. 5. Verwenden Sie Numpy.concatenate, das für große Datensätze und Szenarien mit hohen Leistungsanforderungen geeignet ist. 6. Verwenden Sie die Append -Methode, die für kleine Listen geeignet ist, aber ineffizient ist. Bei der Auswahl einer Methode müssen Sie die Listengröße und die Anwendungsszenarien berücksichtigen.
 Kompiliert gegen interpretierte Sprachen: Vor- und NachteileMay 09, 2025 am 12:06 AM
Kompiliert gegen interpretierte Sprachen: Vor- und NachteileMay 09, 2025 am 12:06 AMCompiledLanguageOfferSpeedandSecurity, während interpretedLanguagesProvideaseofuseAnDportabilität.1) kompiledlanguageslikec areFasterandSecurebuthavelongerDevelopmentCyclesandplatformDependency.2) InterpretedLanguages -pythonareaToReAndoreAndorePortab
 Python: Für und während Schleifen der vollständigste LeitfadenMay 09, 2025 am 12:05 AM
Python: Für und während Schleifen der vollständigste LeitfadenMay 09, 2025 am 12:05 AMIn Python wird eine für die Schleife verwendet, um iterable Objekte zu durchqueren, und eine WHHE -Schleife wird verwendet, um Operationen wiederholt durchzuführen, wenn die Bedingung erfüllt ist. 1) Beispiel für Schleifen: Überqueren Sie die Liste und drucken Sie die Elemente. 2) Während des Schleifens Beispiel: Erraten Sie das Zahlenspiel, bis Sie es richtig erraten. Mastering -Zyklusprinzipien und Optimierungstechniken können die Code -Effizienz und -zuverlässigkeit verbessern.
 Python verkettet listet in eine Zeichenfolge aufMay 09, 2025 am 12:02 AM
Python verkettet listet in eine Zeichenfolge aufMay 09, 2025 am 12:02 AMUm eine Liste in eine Zeichenfolge zu verkettet, ist die Verwendung der join () -Methode in Python die beste Wahl. 1) Verwenden Sie die monjoy () -Methode, um die Listelemente in eine Zeichenfolge wie "" .Join (my_list) zu verkettet. 2) Für eine Liste, die Zahlen enthält, konvertieren Sie die Karte (STR, Zahlen) in eine Zeichenfolge, bevor Sie verkettet werden. 3) Sie können Generatorausdrücke für komplexe Formatierung verwenden, wie z. 4) Verwenden Sie bei der Verarbeitung von Mischdatentypen MAP (STR, MIXED_LIST), um sicherzustellen, dass alle Elemente in Zeichenfolgen konvertiert werden können. 5) Verwenden Sie für große Listen '' .Join (large_li
 Pythons Hybridansatz: Zusammenstellung und Interpretation kombiniertMay 08, 2025 am 12:16 AM
Pythons Hybridansatz: Zusammenstellung und Interpretation kombiniertMay 08, 2025 am 12:16 AMPythonusesahybridapproach, kombinierte CompilationTobyteCodeAnDinterpretation.1) codiscompiledtoplatform-unintenpendentBytecode.2) BytecodeIsinterpretedBythepythonvirtualMachine, EnhancingEfficiency und Portablabilität.
 Erfahren Sie die Unterschiede zwischen Pythons 'für' und 'while the' LoopsMay 08, 2025 am 12:11 AM
Erfahren Sie die Unterschiede zwischen Pythons 'für' und 'while the' LoopsMay 08, 2025 am 12:11 AMDie Keedifferzences -zwischen Pythons "für" und "während" Loopsare: 1) "für" LoopsareideAlForiteratingOvercesorknownowniterations, während 2) "LoopsarebetterForContiningUtilAconditionismethoutnredefineditInations.un
 Python verkettet Listen mit DuplikatenMay 08, 2025 am 12:09 AM
Python verkettet Listen mit DuplikatenMay 08, 2025 am 12:09 AMIn Python können Sie Listen anschließen und doppelte Elemente mit einer Vielzahl von Methoden verwalten: 1) Verwenden von Operatoren oder erweitert (), um alle doppelten Elemente beizubehalten; 2) Konvertieren in Sets und kehren Sie dann zu Listen zurück, um alle doppelten Elemente zu entfernen. Die ursprüngliche Bestellung geht jedoch verloren. 3) Verwenden Sie Schleifen oder listen Sie Verständnisse auf, um Sätze zu kombinieren, um doppelte Elemente zu entfernen und die ursprüngliche Reihenfolge zu verwalten.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

