


Übersicht
Im digitalen Zeitalter sind Spam-E-Mails ein ständiges Ärgernis, das die Posteingänge überfüllt und ein Sicherheitsrisiko darstellt. Um dem entgegenzuwirken, können wir künstliche Intelligenz nutzen, um eine Anwendung zur Spam-Erkennung zu erstellen. In diesem Blogbeitrag führen wir Sie durch den Prozess der Bereitstellung einer mit Python und Flask erstellten KI-Spam-Erkennungs-App auf einer AWS EC2-Instanz. Diese Anwendung nutzt maschinelles Lernen, um E-Mails als Spam oder Nicht-Spam zu klassifizieren und bietet so eine praktische Lösung für ein häufiges Problem.
Was Sie lernen werden
- So richten Sie eine AWS EC2-Instanz ein
- So installieren Sie die erforderliche Software und Abhängigkeiten
- So stellen Sie eine Flask-Anwendung mit Gunicorn bereit
- So konfigurieren Sie Sicherheitseinstellungen für Ihre Anwendung
Voraussetzungen
Bevor wir mit dem Bereitstellungsprozess beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- AWS-Konto: Wenn Sie noch keins haben, können Sie ein kostenloses Konto erstellen. Erstellen Sie hier ein AWS-Konto
- Grundkenntnisse über Terminalbefehle: Vertrautheit mit Befehlszeilenschnittstellen ist hilfreich.
Schritt 1: Starten Sie die Ubuntu EC2-Instanz
1) Melden Sie sich bei Ihrer AWS-Managementkonsole an.
2) Navigieren Sie zum EC2-Dashboard.
3) Klicken Sie auf Instanz starten.
4) Wählen Sie ein Ubuntu-Server-AMI (z. B. Ubuntu 20.04 LTS).
5) Wählen Sie einen Instanztyp (z. B. t2.micro für die kostenlose Stufe).
6) Erstellen Sie ein Schlüsselpaar (.pem)
7) Sicherheitsgruppen konfigurieren:
- SSH zulassen (Port 22).
- Fügen Sie eine Regel für HTTP (Port 80) hinzu.
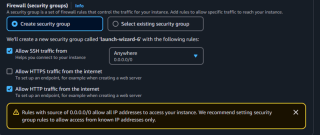
8) Starten Sie die Instanz und stellen Sie eine Verbindung über EC2 Instance Connect her
Schritt 2: Aktualisieren Sie die Instanz
Sobald Sie mit Ihrer EC2-Instanz verbunden sind, empfiehlt es sich, die Paketlisten zu aktualisieren und die installierten Pakete zu aktualisieren:
sudo apt update sudo apt upgrade -y
Schritt 3: Python und Pip installieren
1) Als nächstes müssen wir Python und Pip installieren, die für die Ausführung unserer Flask-Anwendung unerlässlich sind:
sudo apt install python3-pip -y
2) Überprüfen Sie die Installation:
sudo apt update sudo apt upgrade -y
Schritt 4: Einrichten der Flask-App
1) Klonen Sie das Flask-App-Repository: Verwenden Sie Git, um das Repository mit der Spam-Erkennungs-App zu klonen. Ersetzen Sie diese durch die tatsächliche URL Ihres GitHub-Repositorys.
sudo apt install python3-pip -y
2) Navigieren Sie zum Projektordner (ersetzen Sie ihn durch Ihren tatsächlichen Ordnernamen):
python3 --version pip --version
3) Überprüfen Sie die Datei „requirements.txt“: Öffnen Sie die Datei „requirements.txt“, um sicherzustellen, dass sie alle erforderlichen Abhängigkeiten auflistet.
git clone <repository-url> </repository-url>
4) Zeilenenden konvertieren: Wenn Sie Probleme mit der Datei „requirements.txt“ haben (z. B. wenn sie verschlüsselt erscheint), konvertieren Sie sie in Zeilenenden im Unix-Stil:
cd <folder-name> </folder-name>
5) Installieren Sie die Abhängigkeiten:
nano requirements.txt
Schritt 5: Führen Sie die Flask-App aus (Entwicklungsmodus)
Um die Anwendung zu testen, können Sie sie im Entwicklungsmodus ausführen:
file requirements.txt sudo apt install dos2unix -y dos2unix requirements.txt
Standardmäßig wird Flask auf Port 5000 ausgeführt. Sie können überprüfen, ob die App ausgeführt wird, indem Sie in Ihrem Webbrowser zu http://
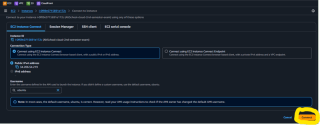
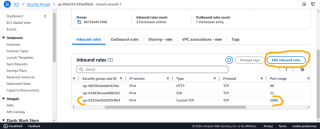
Schritt 6: Öffnen Sie Port 5000 in der Sicherheitsgruppe
Um den Zugriff auf Ihre App zu ermöglichen, müssen Sie Port 5000 in der Sicherheitsgruppe öffnen:
1) Gehen Sie zum EC2-Dashboard in AWS.
2) Wählen Sie Ihre Instanz aus und navigieren Sie zur Registerkarte „Sicherheit“.
3) Klicken Sie auf den Link Sicherheitsgruppe.
4) Bearbeiten Sie die Eingangsregeln, um TCP-Verkehr auf Port 5000 zuzulassen.
Schritt 7: Einrichten eines produktionsbereiten Servers mit Gunicorn (optional)
Um Ihre App auf einem produktionsbereiten Server auszuführen, können Sie Gunicorn verwenden:
1) Gunicorn installieren:
pip install -r requirements.txt
2) Führen Sie die App mit Gunicorn aus:
python3 app.py
Ersetzen Sie app:app durch Ihren tatsächlichen Modul- und App-Namen, falls abweichend.
Fazit
Wir haben Ihre KI-Spam-Erkennungsanwendung erfolgreich auf AWS EC2 bereitgestellt! Sie können jetzt über Ihre öffentliche EC2-IP darauf zugreifen. Erwägen Sie für weitere Verbesserungen die Implementierung von HTTPS und die Verwendung eines Reverse-Proxys wie Nginx für bessere Leistung und Sicherheit.
Schauen Sie sich hier gerne den Screenshot an, wie die App aussieht
Stellen Sie gerne Fragen oder hinterlassen Sie Ihre Kommentare?
Das obige ist der detaillierte Inhalt vonBereitstellung einer KI-Spam-Erkennungs-App auf AWS EC2. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Wie wirkt sich die Auswahl zwischen Listen und Arrays auf die Gesamtleistung einer Python -Anwendung aus, die sich mit großen Datensätzen befasst?May 03, 2025 am 12:11 AM
Wie wirkt sich die Auswahl zwischen Listen und Arrays auf die Gesamtleistung einer Python -Anwendung aus, die sich mit großen Datensätzen befasst?May 03, 2025 am 12:11 AMForHandlinglargedatasetsinpython, Usenumpyarraysforbetterperformance.1) Numpyarraysarememory-Effiction und FasterFornumericaloperations.2) meidenunnötiger Anbieter.3) HebelVectorisationFecedTimeComplexity.4) ManagemememoryusageSageWithEffizienceDeffictureWitheseffizienz
 Erklären Sie, wie das Speicher für Listen gegenüber Arrays in Python zugewiesen wird.May 03, 2025 am 12:10 AM
Erklären Sie, wie das Speicher für Listen gegenüber Arrays in Python zugewiesen wird.May 03, 2025 am 12:10 AMInpython, listEUSUutsynamicMemoryAllocationWithover-Accocation, whilenumpyarraysalcodeFixedMemory.1) ListSallocatemoremoryThanneded intellig, vereitelte, dass die sterbliche Größe von Zeitpunkte, OfferingPredictableSageStoageStloseflexeflexibilität.
 Wie geben Sie den Datentyp der Elemente in einem Python -Array an?May 03, 2025 am 12:06 AM
Wie geben Sie den Datentyp der Elemente in einem Python -Array an?May 03, 2025 am 12:06 AMInpython, youcansspecthedatatypeyFelemeremodelerernspant.1) Usenpynernrump.1) Usenpynerp.dloatp.Ploatm64, Formor -Präzise -Preciscontrolatatypen.
 Was ist Numpy und warum ist es wichtig für das numerische Computing in Python?May 03, 2025 am 12:03 AM
Was ist Numpy und warum ist es wichtig für das numerische Computing in Python?May 03, 2025 am 12:03 AMNumpyisessentialfornumericalComputingInpythonduetoitsSpeed, GedächtnisEffizienz und kompetentiertemaMatematical-Funktionen.1) ITSFACTBECAUSPERFORMATIONSOPERATIONS.2) NumpyarraysSaremoremory-Effecthonpythonlists.3) iTofferSAgyarraysAremoremory-Effizieren
 Diskutieren Sie das Konzept der 'zusammenhängenden Speicherzuweisung' und seine Bedeutung für Arrays.May 03, 2025 am 12:01 AM
Diskutieren Sie das Konzept der 'zusammenhängenden Speicherzuweisung' und seine Bedeutung für Arrays.May 03, 2025 am 12:01 AMContInuuousMemoryAllocationScrucialforAraysBecauseAltoLowsFofficy und Fastelement Access.1) iTenablesconstantTimeAccess, O (1), Duetodirectaddresscalculation.2) itimProvesefficienceByallowing -MultipleTeLementFetchesperCacheline.3) Es wird gestellt
 Wie schneiden Sie eine Python -Liste?May 02, 2025 am 12:14 AM
Wie schneiden Sie eine Python -Liste?May 02, 2025 am 12:14 AMSlicingPapythonListisDoneUsingthesyntaxlist [Start: Stop: Stufe] .here'Showitworks: 1) StartIndexoFtheFirstelementtoinclude.2) stopiStheIndexoFtheFirstelementtoexclude.3) StepisTheincrementBetweenelesfulFulForForforexcractioningPorporionsporporionsPorporionsporporesporsporsporsporsporsporsporsporsporionsporsPorsPorsPorsPorsporsporsporsporsporsporsAntionsporsporesporesporesporsPorsPorsporsPorsPorsporsporspors,
 Was sind einige gängige Operationen, die an Numpy -Arrays ausgeführt werden können?May 02, 2025 am 12:09 AM
Was sind einige gängige Operationen, die an Numpy -Arrays ausgeführt werden können?May 02, 2025 am 12:09 AMNumpyallowsforvariousoperationssonarrays: 1) BasicarithmeticliKeaddition, Subtraktion, Multiplikation und Division; 2) AdvancedoperationssuchasmatrixMultiplication;
 Wie werden Arrays in der Datenanalyse mit Python verwendet?May 02, 2025 am 12:09 AM
Wie werden Arrays in der Datenanalyse mit Python verwendet?May 02, 2025 am 12:09 AMArraysinpython, insbesondere ThroughNumpyandpandas, areessentialfordataanalyse, öfterspeedandeffizienz.1) numpyarraysenableAnalysHandlingoflargedatasets und CompompexoperationslikemovingAverages.2) Pandasextendsnumpy'ScapaBilitiesWithDaTataforsForstruc


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

