


Wenn Sie in die Welt von Big Data eintauchen, haben Sie wahrscheinlich schon von Apache Spark gehört, einem leistungsstarken verteilten Computersystem. PySpark, die Python-Bibliothek für Apache Spark, ist aufgrund ihrer Kombination aus Geschwindigkeit, Skalierbarkeit und Benutzerfreundlichkeit bei Datenbegeisterten beliebt. Aber die Einrichtung auf Ihrem lokalen Computer kann zunächst etwas einschüchternd wirken.
Keine Angst – dieser Artikel führt Sie durch den gesamten Prozess, geht auf häufige Fragen ein und macht den Weg so unkompliziert wie möglich.
Was ist PySpark und warum sollte es Sie interessieren?
Bevor wir mit der Installation beginnen, wollen wir verstehen, was PySpark ist. Mit PySpark können Sie die enorme Rechenleistung von Apache Spark mithilfe von Python nutzen. Egal, ob Sie Terabytes an Daten analysieren, Modelle für maschinelles Lernen erstellen oder ETL-Pipelines (Extrahieren, Transformieren, Laden) ausführen, mit PySpark können Sie damit arbeiten Daten effizienter als je zuvor.
Da Sie nun PySpark verstanden haben, gehen wir den Installationsprozess durch.
Schritt 1: Stellen Sie sicher, dass Ihr System die Anforderungen erfüllt
PySpark läuft auf verschiedenen Maschinen, darunter Windows, macOS und Linux. Folgendes benötigen Sie für eine erfolgreiche Installation:
- Java Development Kit (JDK): PySpark erfordert Java (Version 8 oder 11 wird empfohlen).
- Python: Stellen Sie sicher, dass Sie Python 3.6 oder höher haben.
- Apache Spark Binary: Sie werden dies während des Installationsvorgangs herunterladen.
So überprüfen Sie die Bereitschaft Ihres Systems:
- Öffnen Sie Ihr Terminal oder Ihre Eingabeaufforderung.
- Geben Sie java -version und python –version ein, um Java- und Python-Installationen zu bestätigen.
Wenn Sie Java oder Python nicht installiert haben, befolgen Sie diese Schritte:
- Für Java: Laden Sie es von der offiziellen Website von Oracle herunter.
- Für Python: Besuchen Sie die Download-Seite von Python.
Schritt 2: Java installieren
Java ist das Rückgrat von Apache Spark. So installieren Sie es:
1.Java herunterladen: Besuchen Sie die Downloadseite des Java SE Development Kit. Wählen Sie die passende Version für Ihr Betriebssystem.
2.Java installieren: Führen Sie das Installationsprogramm aus und befolgen Sie die Anweisungen. Unter Windows müssen Sie die Umgebungsvariable JAVA_HOME festlegen. Um dies zu tun:
- Kopieren Sie die Pfadvariable, gehen Sie zur lokalen Festplatte auf Ihrem Computer, wählen Sie Programmdateien und suchen Sie nach dem Java-Ordner Wenn Sie es öffnen, sehen Sie jdk-17 (Ihre eigene Version möglicherweise nicht). 17 sein). Öffnen Sie es und Sie können Ihren Pfad sehen und wie unten kopieren
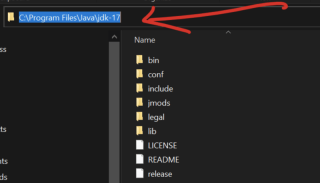
Suchen Sie nach Umgebungsvariablen in der Windows-Suchleiste.
Klicken Sie unter Systemvariablen auf Neu und legen Sie den Variablennamen auf JAVA_HOME und den Wert auf Ihren Java-Installationspfad fest, den Sie oben kopiert haben (z. B. C:Programm DateienJavajdk-17).
3.Installation überprüfen: Öffnen Sie ein Terminal oder eine Eingabeaufforderung und geben Sie java-version.
einSchritt 3: Installieren Sie Apache Spark
1.Spark herunterladen: Besuchen Sie die Website von Apache Spark und wählen Sie die Version aus, die Ihren Anforderungen entspricht. Verwenden Sie das vorgefertigte Paket für Hadoop (eine häufige Kombination mit Spark).
2.Extrahieren Sie die Dateien:
- Verwenden Sie unter Windows ein Tool wie WinRAR oder 7-Zip, um die Datei zu extrahieren.
- Verwenden Sie unter macOS/Linux den Befehl tar -xvf spark-.tgz
3.Umgebungsvariablen festlegen:
- Für Windows: Fügen Sie das bin-Verzeichnis von Spark zur PATH-Variablen Ihres Systems hinzu.
- Für macOS/Linux: Fügen Sie die folgenden Zeilen zu Ihrer Datei .bashrc oder .zshrc hinzu :
export SPARK_HOME=/path/to/spark export PATH=$SPARK_HOME/bin:$PATH
4.Installation überprüfen: Öffnen Sie ein Terminal und geben Sie spark-shell ein. Sie sollten sehen, wie die interaktive Shell von Spark startet.
Schritt 4: Hadoop installieren (optional, aber empfohlen)
Während Spark Hadoop nicht unbedingt benötigt, installieren es viele Benutzer wegen der HDFS-Unterstützung (Hadoop Distributed File System). So installieren Sie Hadoop:
- Laden Sie Hadoop-Binärdateien von der Apache Hadoop-Website herunter.
- Extrahieren Sie die Dateien und richten Sie die Umgebungsvariable HADOOP_HOME ein.
Schritt 5: Installieren Sie PySpark über Pip
Die Installation von PySpark ist mit dem Pip-Tool von Python ein Kinderspiel. Führen Sie einfach aus:
pip install pyspark
Öffnen Sie zur Überprüfung eine Python-Shell und geben Sie Folgendes ein:
pip install pysparkark.__version__)
Wenn Sie eine Versionsnummer sehen, herzlichen Glückwunsch! PySpark ist installiert ?
Schritt 6: Testen Sie Ihre PySpark-Installation
Hier beginnt der Spaß. Sorgen wir dafür, dass alles reibungslos funktioniert:
Erstellen Sie ein einfaches Skript:
Öffnen Sie einen Texteditor und fügen Sie den folgenden Code ein:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("PySparkTest").getOrCreate()
data = [("Alice", 25), ("Bob", 30), ("Cathy", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
df.show()
Speichern Sie es als test_pyspark.py
Führen Sie das Skript aus:
Navigieren Sie in Ihrem Terminal zum Verzeichnis des Skripts und geben Sie Folgendes ein:
export SPARK_HOME=/path/to/spark export PATH=$SPARK_HOME/bin:$PATH
Sie sollten eine übersichtliche Tabelle mit den Namen und dem Alter sehen.
Beheben häufiger Probleme
Selbst mit den besten Anweisungen kann es zu Schluckauf kommen. Hier sind einige häufige Probleme und Lösungen:
Problem: java.lang.NoClassDefFoundError
Lösung: Überprüfen Sie Ihre JAVA_HOME- und PATH-Variablen noch einmal.Problem: Die PySpark-Installation war erfolgreich, aber das Testskript ist fehlgeschlagen.
Lösung: Stellen Sie sicher, dass Sie die richtige Python-Version verwenden. Manchmal können virtuelle Umgebungen Konflikte verursachen.Problem: Der Spark-Shell-Befehl funktioniert nicht.
Lösung: Stellen Sie sicher, dass das Spark-Verzeichnis korrekt zu Ihrem PATH hinzugefügt wurde.
Warum PySpark lokal verwenden?
Viele Benutzer fragen sich, warum sie sich die Mühe machen sollten, PySpark auf ihrem lokalen Computer zu installieren, wenn es hauptsächlich in verteilten Systemen verwendet wird. Hier ist der Grund:
- Lernen: Experimentieren und lernen Sie Spark-Konzepte, ohne dass ein Cluster erforderlich ist.
- Prototyping: Testen Sie kleine Datenjobs lokal, bevor Sie sie in einer größeren Umgebung bereitstellen.
- Komfort: Beheben Sie Probleme und entwickeln Sie Anwendungen ganz einfach.
Steigern Sie Ihre PySpark-Produktivität
Um das Beste aus PySpark herauszuholen, beachten Sie die folgenden Tipps:
Richten Sie eine virtuelle Umgebung ein: Verwenden Sie Tools wie venv oder conda, um Ihre PySpark-Installation zu isolieren.
Integration mit IDEs: Tools wie PyCharm und Jupyter Notebook machen die PySpark-Entwicklung interaktiver.
Nutzen Sie die PySpark-Dokumentation: Besuchen Sie die Dokumentation von Apache Spark für ausführliche Anleitungen.
Treten Sie der PySpark-Community bei
Störungen sind normal, insbesondere mit einem leistungsstarken Tool wie PySpark. Bitten Sie die lebendige PySpark-Community um Hilfe:
Foren beitreten: Websites wie Stack Overflow verfügen über spezielle Spark-Tags.
Nehmen Sie an Meetups teil: Spark- und Python-Communitys veranstalten oft Veranstaltungen, bei denen Sie lernen und sich vernetzen können.
Blogs folgen: Viele Datenexperten teilen ihre Erfahrungen und Tutorials online.
Abschluss
Die Installation von PySpark auf Ihrem lokalen Computer mag zunächst entmutigend erscheinen, aber die Befolgung dieser Schritte macht es überschaubar und lohnend. Egal, ob Sie gerade erst mit Ihrer Datenreise beginnen oder Ihre Fähigkeiten verbessern, PySpark stattet Sie mit den Tools aus, mit denen Sie reale Datenprobleme angehen können.
PySpark, die Python-API für Apache Spark, revolutioniert die Datenanalyse und -verarbeitung. Obwohl das Potenzial enorm ist, kann die Einrichtung auf Ihrem lokalen Computer eine Herausforderung sein. In diesem Artikel wird der Prozess Schritt für Schritt beschrieben und alles von der Installation von Java über das Herunterladen von Spark bis hin zum Testen Ihres Setups mit einem einfachen Skript behandelt.
Wenn PySpark lokal installiert ist, können Sie Daten-Workflows prototypisieren, die Funktionen von Spark erlernen und kleine Projekte testen, ohne dass ein vollständiger Cluster erforderlich ist.
Das obige ist der detaillierte Inhalt vonSo installieren Sie PySpark auf Ihrem lokalen Computer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python: Automatisierung, Skript- und AufgabenverwaltungApr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und AufgabenverwaltungApr 16, 2025 am 12:14 AMPython zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python und Zeit: Machen Sie das Beste aus Ihrer StudienzeitApr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer StudienzeitApr 14, 2025 am 12:02 AMUm die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AMPython zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AMPython eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AMSie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AM
Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AMPython wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PMSie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AMWie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

