
 Backend-EntwicklungPython-TutorialPython-Cache: So beschleunigen Sie Ihren Code durch effektives Caching
Backend-EntwicklungPython-TutorialPython-Cache: So beschleunigen Sie Ihren Code durch effektives Caching
Dieser Blog wurde ursprünglich im Crawlbase Blog gepostet
Effizienter und schneller Code ist wichtig für die Schaffung einer großartigen Benutzererfahrung in Softwareanwendungen. Benutzer warten nicht gerne auf langsame Antworten, sei es beim Laden einer Webseite, beim Trainieren eines maschinellen Lernmodells oder beim Ausführen eines Skripts. Eine Möglichkeit, Ihren Code zu beschleunigen, ist das Caching.
Der Zweck des Caching besteht darin, häufig verwendete Daten vorübergehend zwischenzuspeichern, damit Ihr Programm schneller darauf zugreifen kann, ohne sie mehrmals neu berechnen oder abrufen zu müssen. Caching kann die Reaktionszeiten beschleunigen, die Belastung reduzieren und das Benutzererlebnis verbessern.
In diesem Blog werden Caching-Prinzipien, seine Rolle, Anwendungsfälle, Strategien und reale Beispiele für Caching in Python behandelt. Fangen wir an!
Caching in Python implementieren
Caching kann in Python auf verschiedene Arten erfolgen. Schauen wir uns zwei gängige Methoden an: die Verwendung eines manuellen Decorators für das Caching und Pythons integrierten functools.lru_cache.
1. Manueller Decorator für Caching
Ein Dekorator ist eine Funktion, die eine andere Funktion umschließt. Wir können einen Caching-Dekorator erstellen, der das Ergebnis von Funktionsaufrufen im Speicher speichert und das zwischengespeicherte Ergebnis zurückgibt, wenn dieselbe Eingabe erneut aufgerufen wird. Hier ist ein Beispiel:
import requests
# Manual caching decorator
def memoize(func):
cache = {}
def wrapper(*args):
if args in cache:
return cache[args]
result = func(*args)
cache[args] = result
return result
return wrapper
# Function to get data from a URL
@memoize
def get_html(url):
response = requests.get(url)
return response.text
# Example usage
print(get_html('https://crawlbase.com'))
In diesem Beispiel werden beim ersten Aufruf von get_html die Daten von der URL abgerufen und zwischengespeichert. Bei nachfolgenden Aufrufen mit derselben URL wird das zwischengespeicherte Ergebnis zurückgegeben.
- Verwendung von Pythons functools.lru_cache
Python bietet einen integrierten Caching-Mechanismus namens lru_cache aus dem functools-Modul. Dieser Dekorator speichert Funktionsaufrufe zwischen und entfernt die zuletzt verwendeten Elemente, wenn der Cache voll ist. So verwenden Sie es:
from functools import lru_cache
@lru_cache(maxsize=128)
def expensive_computation(x, y):
return x * y
# Example usage
print(expensive_computation(5, 6))
In diesem Beispiel speichert lru_cache das Ergebnis von teuer_computation zwischen. Wenn die Funktion erneut mit denselben Argumenten aufgerufen wird, gibt sie das zwischengespeicherte Ergebnis zurück, anstatt eine Neuberechnung durchzuführen.
Leistungsvergleich von Caching-Strategien
Bei der Auswahl einer Caching-Strategie müssen Sie berücksichtigen, wie diese unter verschiedenen Bedingungen funktioniert. Die Leistung von Caching-Strategien hängt von der Anzahl der Cache-Treffer (wenn Daten im Cache gefunden werden) und der Größe des Caches ab.
Hier ist ein Vergleich gängiger Caching-Strategien:
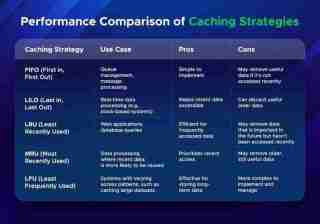
Die Wahl der richtigen Caching-Strategie hängt von den Datenzugriffsmustern und Leistungsanforderungen Ihrer Anwendung ab.
Letzte Gedanken
Caching kann für Ihre Apps sehr nützlich sein. Es kann die Datenabrufzeit und die Systemlast reduzieren. Egal, ob Sie eine Web-App oder ein maschinelles Lernprojekt erstellen oder Ihr System beschleunigen möchten, durch intelligentes Caching kann Ihr Code schneller ausgeführt werden.
Caching-Methoden wie FIFO, LRU und LFU haben unterschiedliche Anwendungsfälle. LRU eignet sich beispielsweise gut für Web-Apps, die häufig aufgerufene Daten speichern müssen, während LFU für Programme geeignet ist, die Daten über einen längeren Zeitraum speichern müssen.
Durch die korrekte Implementierung des Cachings können Sie schnellere und effizientere Apps entwerfen und eine bessere Leistung und Benutzererfahrung erzielen.
Das obige ist der detaillierte Inhalt vonPython-Cache: So beschleunigen Sie Ihren Code durch effektives Caching. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Warum sind Arrays im Allgemeinen speichereffizienter als Listen für das Speichern numerischer Daten?May 05, 2025 am 12:15 AM
Warum sind Arrays im Allgemeinen speichereffizienter als Listen für das Speichern numerischer Daten?May 05, 2025 am 12:15 AMARRAYSAREGENERARYMOREMORY-effizientesThanlistsforstoringNumericalDataduetototototheirfixed-SizenReanddirectMemoryAccess.1) ArraysStoreElementsInacontuTouNDdirectMemoryAccess.
 Wie können Sie eine Python -Liste in ein Python -Array konvertieren?May 05, 2025 am 12:10 AM
Wie können Sie eine Python -Liste in ein Python -Array konvertieren?May 05, 2025 am 12:10 AMToconvertapythonListtoanArray, UsethearrayModule: 1) ImportThearrayModule, 2) Kreatelist, 3) Usearray (Typcode, Liste) Toconvertit, spezifizieren thetypecodelik'i'i'i'i'i'i'i'i'Itingers.ThiskonversionoptimizesMorySageForHomoGeenousData, EnhancingIntationSerance -Formance -FormanceConconcompomp
 Können Sie verschiedene Datentypen in derselben Python -Liste speichern? Geben Sie ein Beispiel an.May 05, 2025 am 12:10 AM
Können Sie verschiedene Datentypen in derselben Python -Liste speichern? Geben Sie ein Beispiel an.May 05, 2025 am 12:10 AMPython -Listen können verschiedene Arten von Daten speichern. Die Beispielliste enthält Ganzzahlen, Saiten, schwimmende Punktzahlen, Boolesche, verschachtelte Listen und Wörterbücher. Die Listenflexibilität ist bei der Datenverarbeitung und -prototypung wertvoll, muss jedoch mit Vorsicht verwendet werden, um die Lesbarkeit und Wartbarkeit des Codes sicherzustellen.
 Was ist der Unterschied zwischen Arrays und Listen in Python?May 05, 2025 am 12:06 AM
Was ist der Unterschied zwischen Arrays und Listen in Python?May 05, 2025 am 12:06 AMPythondoesnothavebuilt-In-In-In-In-Grad; UsethearraymoduleformemoryeffizientHomogenousDatastorage, whilelistareversatileformixedDatatypes
 Welches Modul wird gewöhnlich verwendet, um Arrays in Python zu erstellen?May 05, 2025 am 12:02 AM
Welches Modul wird gewöhnlich verwendet, um Arrays in Python zu erstellen?May 05, 2025 am 12:02 AMThemostcommonlyusedModuleforcreatreatraysinpythonisnumpy.1) NumpyprovideseffictionToolsforArrayoperationen, IdealfornicericalData.2) ArraysCanbesedusednp.Array () for1dand2dstructures.3) numpyexcelsusingnp.Array () und -Antenoperationen
 Wie können Sie Elemente an eine Python -Liste anhängen?May 04, 2025 am 12:17 AM
Wie können Sie Elemente an eine Python -Liste anhängen?May 04, 2025 am 12:17 AMToAppendElementStoapythonList, UsTheAppend () methodForsingleElelements, Extend () FormultipleElements, und INSERSt () FORSPECIFIFICEPosition.1) UseAppend () ForaddingOneElementattheend.2) usextend () toaddmultiElementsefficction.3) useInsert () toaddanelementataspeci
 Wie erstellt man eine Python -Liste? Geben Sie ein Beispiel an.May 04, 2025 am 12:16 AM
Wie erstellt man eine Python -Liste? Geben Sie ein Beispiel an.May 04, 2025 am 12:16 AMTocreateApythonList, usequarebrackets [] andsparateItemswithcommas.1) ListaredynamicandcanholdmixedDatatypes.2) UseAppend (), REME () und SSLICINGFORMIPLUMILATION.3) LISTCOMPRAUMENS
 Diskutieren Sie reale Anwendungsfälle, in denen eine effiziente Speicherung und Verarbeitung numerischer Daten von entscheidender Bedeutung ist.May 04, 2025 am 12:11 AM
Diskutieren Sie reale Anwendungsfälle, in denen eine effiziente Speicherung und Verarbeitung numerischer Daten von entscheidender Bedeutung ist.May 04, 2025 am 12:11 AMIn den Bereichen Finanzen, wissenschaftliche Forschung, medizinische Versorgung und KI ist es entscheidend, numerische Daten effizient zu speichern und zu verarbeiten. 1) In der Finanzierung kann die Verwendung von Speicherzuordnungsdateien und Numpy -Bibliotheken die Datenverarbeitungsgeschwindigkeit erheblich verbessern. 2) Im Bereich der wissenschaftlichen Forschung sind HDF5 -Dateien für die Datenspeicherung und -abnahme optimiert. 3) In der medizinischen Versorgung verbessern die Datenbankoptimierungstechnologien wie die Indexierung und die Partitionierung die Leistung der Datenabfrage. 4) In AI beschleunigen Daten, die Sharding und das verteilte Training beschleunigen, Modelltraining. Die Systemleistung und Skalierbarkeit können erheblich verbessert werden, indem die richtigen Tools und Technologien ausgewählt und Kompromisse zwischen Speicher- und Verarbeitungsgeschwindigkeiten abgewogen werden.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

