


Kauf mir einen Kaffee☕
*Mein Beitrag erklärt Caltech 101.
Caltech101() kann den Caltech 101-Datensatz wie unten gezeigt verwenden:
*Memos:
- Das 1. Argument ist root(Required-Type:str oder pathlib.Path). *Ein absoluter oder relativer Pfad ist möglich.
- Das 2. Argument ist target_type(Optional-Default:"category"-Type:str oder Tupel oder Liste von str). *„Kategorie“ und/oder „Anmerkung“ können darauf eingestellt werden.
- Das dritte Argument ist transform(Optional-Default:None-Type:callable).
- Das 4. Argument ist target_transform(Optional-Default:None-Type:callable).
- Das 5. Argument ist download(Optional-Default:False-Type:bool):
*Memos:
- Wenn es wahr ist, wird der Datensatz aus dem Internet heruntergeladen und in das Stammverzeichnis extrahiert (entpackt).
- Wenn es „True“ ist und der Datensatz bereits heruntergeladen wurde, wird er extrahiert.
- Wenn es „True“ ist und der Datensatz bereits heruntergeladen und extrahiert wurde, passiert nichts.
- Es sollte False sein, wenn der Datensatz bereits heruntergeladen und extrahiert wurde, da es schneller ist.
- Sie können den Datensatz (101_ObjectCategories.tar.gz und Annotations.tar) manuell herunterladen und von hier nach data/caltech101/ extrahieren.
- Zu den Kategorien der Bildindizes: Faces(0) ist 0~434, Faces_easy(1) ist 435~869, Leopards(2 ) ist 870~1069, Motorräder(3) ist 1070~1867, Akkordeon(4) ist 1868~1922, Flugzeuge(5) ist 1923~2722, Anker(6) ist 2723~2764, ant(7) ist 2765~2806, barrel(8) ist 2807~2853, bass(9) ist 2854~2907 usw .
from torchvision.datasets import Caltech101
category_data = Caltech101(
root="data"
)
category_data = Caltech101(
root="data",
target_type="category",
transform=None,
target_transform=None,
download=False
)
annotation_data = Caltech101(
root="data",
target_type="annotation"
)
all_data = Caltech101(
root="data",
target_type=["category", "annotation"]
)
len(category_data), len(annotation_data), len(all_data)
# (8677, 8677, 8677)
category_data
# Dataset Caltech101
# Number of datapoints: 8677
# Root location: data\caltech101
# Target type: ['category']
category_data.root
# 'data/caltech101'
category_data.target_type
# ['category']
print(category_data.transform)
# None
print(category_data.target_transform)
# None
category_data.download
# <bound method caltech101.download of dataset caltech101 number datapoints: root location: data target type:>
len(category_data.categories)
# 101
category_data.categories
# ['Faces', 'Faces_easy', 'Leopards', 'Motorbikes', 'accordion',
# 'airplanes', 'anchor', 'ant', 'barrel', 'bass', 'beaver',
# 'binocular', 'bonsai', 'brain', 'brontosaurus', 'buddha',
# 'butterfly', 'camera', 'cannon', 'car_side', 'ceiling_fan',
# 'cellphone', 'chair', 'chandelier', 'cougar_body', 'cougar_face', ...]
len(category_data.annotation_categories)
# 101
category_data.annotation_categories
# ['Faces_2', 'Faces_3', 'Leopards', 'Motorbikes_16', 'accordion',
# 'Airplanes_Side_2', 'anchor', 'ant', 'barrel', 'bass',
# 'beaver', 'binocular', 'bonsai', 'brain', 'brontosaurus',
# 'buddha', 'butterfly', 'camera', 'cannon', 'car_side',
# 'ceiling_fan', 'cellphone', 'chair', 'chandelier', 'cougar_body', ...]
category_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">, 0)
category_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">, 0)
category_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">, 0)
category_data[435]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="290x334">, 1)
category_data[870]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="192x128">, 2)
annotation_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">,
# array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],
# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))
annotation_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">,
# array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],
# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))
annotation_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">,
# array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],
# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))
annotation_data[435]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="290x334">,
# array([[64.52631579, 95.31578947, 123.26315789, 149.31578947, ...],
# [15.42105263, 8.31578947, 10.21052632, 28.21052632, ...]]))
annotation_data[870]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="192x128">,
# array([[2.96536524, 7.55604534, 19.45780856, 33.73992443, ...],
# [23.63413098, 32.13539043, 33.83564232, 8.84193955, ...]]))
all_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">,
# (0, array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],
# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))
all_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">,
# (0, array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],
# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))
all_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">,
# (0, array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],
# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))
all_data[3]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="538x355">,
# (0, array([[19.54035088, 18.57894737, 26.27017544, 38.2877193, ...],
# [131.49122807, 100.24561404, 74.2877193, 49.29122807, ...]]))
all_data[4]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="528x349">,
# (0, array([[11.87982456, 11.87982456, 13.86578947, 15.35526316, ...],
# [128.34649123, 105.50789474, 91.60614035, 76.71140351, ...]]))
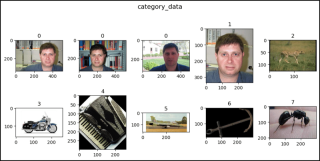
import matplotlib.pyplot as plt
def show_images(data, main_title=None):
plt.figure(figsize=(10, 5))
plt.suptitle(t=main_title, y=1.0, fontsize=14)
ims = (0, 1, 2, 435, 870, 1070, 1868, 1923, 2723, 2765, 2807, 2854)
for i, j in enumerate(ims, start=1):
plt.subplot(2, 5, i)
if len(data.target_type) == 1:
if data.target_type[0] == "category":
im, lab = data[j]
plt.title(label=lab)
elif data.target_type[0] == "annotation":
im, (px, py) = data[j]
plt.scatter(x=px, y=py)
plt.imshow(X=im)
elif len(data.target_type) == 2:
if data.target_type[0] == "category":
im, (lab, (px, py)) = data[j]
elif data.target_type[0] == "annotation":
im, ((px, py), lab) = data[j]
plt.title(label=lab)
plt.imshow(X=im)
plt.scatter(x=px, y=py)
if i == 10:
break
plt.tight_layout()
plt.show()
show_images(data=category_data, main_title="category_data")
show_images(data=annotation_data, main_title="annotation_data")
show_images(data=all_data, main_title="all_data")
</pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></bound>


Das obige ist der detaillierte Inhalt vonCaltech in PyTorch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python vs. C: Verständnis der wichtigsten UnterschiedeApr 21, 2025 am 12:18 AM
Python vs. C: Verständnis der wichtigsten UnterschiedeApr 21, 2025 am 12:18 AMPython und C haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1) Python ist aufgrund seiner prägnanten Syntax und der dynamischen Typisierung für die schnelle Entwicklung und Datenverarbeitung geeignet. 2) C ist aufgrund seiner statischen Tipp- und manuellen Speicherverwaltung für hohe Leistung und Systemprogrammierung geeignet.
 Python vs. C: Welche Sprache für Ihr Projekt zu wählen?Apr 21, 2025 am 12:17 AM
Python vs. C: Welche Sprache für Ihr Projekt zu wählen?Apr 21, 2025 am 12:17 AMDie Auswahl von Python oder C hängt von den Projektanforderungen ab: 1) Wenn Sie eine schnelle Entwicklung, Datenverarbeitung und Prototypdesign benötigen, wählen Sie Python. 2) Wenn Sie eine hohe Leistung, eine geringe Latenz und eine schließende Hardwarekontrolle benötigen, wählen Sie C.
 Erreichen Sie Ihre Python -Ziele: Die Kraft von 2 Stunden täglichApr 20, 2025 am 12:21 AM
Erreichen Sie Ihre Python -Ziele: Die Kraft von 2 Stunden täglichApr 20, 2025 am 12:21 AMIndem Sie täglich 2 Stunden Python -Lernen investieren, können Sie Ihre Programmierkenntnisse effektiv verbessern. 1. Lernen Sie neues Wissen: Lesen Sie Dokumente oder sehen Sie sich Tutorials an. 2. Üben: Schreiben Sie Code und vollständige Übungen. 3. Überprüfung: Konsolidieren Sie den Inhalt, den Sie gelernt haben. 4. Projektpraxis: Wenden Sie an, was Sie in den tatsächlichen Projekten gelernt haben. Ein solcher strukturierter Lernplan kann Ihnen helfen, Python systematisch zu meistern und Karriereziele zu erreichen.
 Maximieren 2 Stunden: Effektive Strategien für Python -LernstrategienApr 20, 2025 am 12:20 AM
Maximieren 2 Stunden: Effektive Strategien für Python -LernstrategienApr 20, 2025 am 12:20 AMZu den Methoden zum effizienten Erlernen von Python innerhalb von zwei Stunden gehören: 1. Überprüfen Sie das Grundkenntnis und stellen Sie sicher, dass Sie mit der Python -Installation und der grundlegenden Syntax vertraut sind. 2. Verstehen Sie die Kernkonzepte von Python wie Variablen, Listen, Funktionen usw.; 3.. Master Basic und Advanced Nutzung unter Verwendung von Beispielen; 4.. Lernen Sie gemeinsame Fehler und Debugging -Techniken; 5. Wenden Sie Leistungsoptimierung und Best Practices an, z. B. die Verwendung von Listenfunktionen und dem Befolgen des Pep8 -Stilhandbuchs.
 Wählen Sie zwischen Python und C: Die richtige Sprache für SieApr 20, 2025 am 12:20 AM
Wählen Sie zwischen Python und C: Die richtige Sprache für SieApr 20, 2025 am 12:20 AMPython ist für Anfänger und Datenwissenschaften geeignet und C für Systemprogramme und Spieleentwicklung geeignet. 1. Python ist einfach und einfach zu bedienen, geeignet für Datenwissenschaft und Webentwicklung. 2.C bietet eine hohe Leistung und Kontrolle, geeignet für Spieleentwicklung und Systemprogrammierung. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Python vs. C: Eine vergleichende Analyse von ProgrammiersprachenApr 20, 2025 am 12:14 AM
Python vs. C: Eine vergleichende Analyse von ProgrammiersprachenApr 20, 2025 am 12:14 AMPython eignet sich besser für Datenwissenschaft und schnelle Entwicklung, während C besser für Hochleistungen und Systemprogramme geeignet ist. 1. Python -Syntax ist prägnant und leicht zu lernen, geeignet für die Datenverarbeitung und wissenschaftliches Computer. 2.C hat eine komplexe Syntax, aber eine hervorragende Leistung und wird häufig in der Spieleentwicklung und der Systemprogrammierung verwendet.
 2 Stunden am Tag: Das Potenzial des Python -LernensApr 20, 2025 am 12:14 AM
2 Stunden am Tag: Das Potenzial des Python -LernensApr 20, 2025 am 12:14 AMEs ist machbar, zwei Stunden am Tag zu investieren, um Python zu lernen. 1. Lernen Sie neues Wissen: Lernen Sie in einer Stunde neue Konzepte wie Listen und Wörterbücher. 2. Praxis und Übung: Verwenden Sie eine Stunde, um Programmierübungen durchzuführen, z. B. kleine Programme. Durch vernünftige Planung und Ausdauer können Sie die Kernkonzepte von Python in kurzer Zeit beherrschen.
 Python vs. C: Lernkurven und BenutzerfreundlichkeitApr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und BenutzerfreundlichkeitApr 19, 2025 am 12:20 AMPython ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

