


Überblick
Ich habe ein Python-Skript geschrieben, das die Geschäftslogik der PDF-Datenextraktion in funktionierenden Code übersetzt.
Das Skript wurde auf 71 Seiten PDFs mit Depotbankauszügen über einen Zeitraum von 10 Monaten (Januar bis Oktober 2024) getestet. Die Verarbeitung der PDFs dauerte etwa 4 Sekunden – deutlich schneller als die manuelle Bearbeitung.

Soweit ich weiß, sieht die Ausgabe korrekt aus und im Code sind keine Fehler aufgetreten.
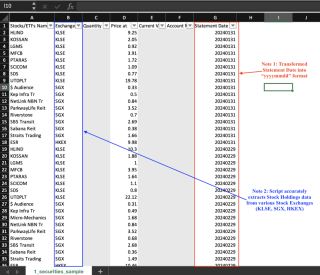
Schnappschüsse der drei CSV-Ausgaben werden unten angezeigt. Beachten Sie, dass vertrauliche Daten ausgegraut sind.
Momentaufnahme 1: Aktienbestände
Momentaufnahme 2: Fondsbestände

Momentaufnahme 3: Bargeldbestände

Dieser Workflow zeigt die allgemeinen Schritte, die ich zum Generieren der CSV-Dateien unternommen habe.
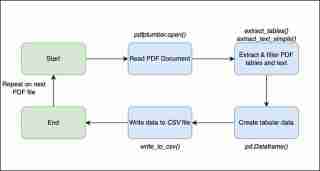
Jetzt werde ich detaillierter erläutern, wie ich die Geschäftslogik in Code in Python übersetzt habe.
Schritt 1: PDF-Dokumente lesen
Ich habe die open()-Funktion von pdfplumber verwendet.
# Open the PDF file with pdfplumber.open(file_path) as pdf:
file_path ist eine deklarierte Variable, die pdfplumber mitteilt, welche Datei geöffnet werden soll.
Schritt 2.0: Extrahieren und filtern Sie Tabellen von jeder Seite
Die Funktion extract_tables() übernimmt die harte Arbeit, alle Tabellen von jeder Seite zu extrahieren.
Obwohl ich mit der zugrunde liegenden Logik nicht wirklich vertraut bin, denke ich, dass die Funktion ziemlich gute Arbeit geleistet hat. Die beiden Schnappschüsse unten zeigen beispielsweise die extrahierte Tabelle im Vergleich zum Original (aus dem PDF)
Snapshot A: Ausgabe vom VS Code Terminal

Schnappschuss B: Tabelle im PDF

Ich musste dann jede Tabelle eindeutig beschriften, damit ich später Daten aus bestimmten Tabellen „auswählen“ konnte.
Die ideale Option bestand darin, den Titel jeder Tabelle zu verwenden. Allerdings überstieg die Bestimmung der Titelkoordinaten meine Fähigkeiten.
Um dieses Problem zu umgehen, habe ich jede Tabelle identifiziert, indem ich die Überschriften der ersten drei Spalten verkettet habe. Beispielsweise trägt die Tabelle Aktienbestände in Snapshot B die Bezeichnung Stocks/ETFsnNameExchangeQuantity.
⚠️Dieser Ansatz hat einen gravierenden Nachteil: Die ersten drei Kopfzeilennamen machen nicht alle Tabellen ausreichend eindeutig. Glücklicherweise betrifft dies nur irrelevante Tabellen.
Schritt 2.1: Extrahieren, filtern und transformieren Sie Nicht-Tabellentext
Die spezifischen Werte, die ich brauchte – Kontonummer und Kontoauszugsdatum – waren Teilzeichenfolgen auf Seite 1 jeder PDF-Datei.
Zum Beispiel enthält „Kontonummer M1234567“ die Kontonummer „M1234567“.

Ich habe die Re-Bibliothek von Python verwendet und ChatGPT dazu gebracht, geeignete reguläre Ausdrücke („Regex“) vorzuschlagen. Der reguläre Ausdruck unterteilt jede Zeichenfolge in zwei Gruppen, mit den gewünschten Daten in der zweiten Gruppe.
Regex für Zeichenfolgen mit Kontoauszugsdatum und Kontonummer
# Open the PDF file with pdfplumber.open(file_path) as pdf:
Als nächstes habe ich das Abrechnungsdatum in das Format „JJJJMMTT“ umgewandelt. Dies erleichtert das Abfragen und Sortieren von Daten.
regex_date=r'Statement for \b([A-Za-z]{3}-\d{4})\b'
regex_acc_no=r'Account Number ([A-Za-z]\d{7})'
match_date ist eine Variable, die deklariert wird, wenn eine Zeichenfolge gefunden wird, die mit dem regulären Ausdruck übereinstimmt.
Schritt 3: Erstellen Sie tabellarische Daten
Die harte Arbeit – das Extrahieren der relevanten Datenpunkte – war zu diesem Zeitpunkt so gut wie abgeschlossen.
Als nächstes habe ich die DataFrame()-Funktion von Pandas verwendet, um Tabellendaten basierend auf der Ausgabe in Schritt 2 und Schritt 3 zu erstellen. Ich habe diese Funktion auch verwendet, um unnötige Spalten und Zeilen zu löschen.
Das Endergebnis kann dann einfach in eine CSV-Datei geschrieben oder in einer Datenbank gespeichert werden.
Schritt 4: Daten in eine CSV-Datei schreiben
Ich habe die Funktion write_to_csv() von Python verwendet, um jeden Datenrahmen in eine CSV-Datei zu schreiben.
if match_date:
# Convert string to a mmm-yyyy date
date_obj=datetime.strptime(match_date.group(1),"%b-%Y")
# Get last day of the month
last_day=calendar.monthrange(date_obj.year,date_obj.month[1]
# Replace day with last day of month
last_day_of_month=date_obj.replace(day=last_day)
statement_date=last_day_of_month.strftime("%Y%m%d")
df_cash_selected ist der Cash-Bestände-Datenrahmen, während file_cash_holdings der Dateiname der Cash-Bestände-CSV-Datei ist.
➡️ Ich werde die Daten in eine geeignete Datenbank schreiben, sobald ich mir etwas Datenbank-Know-how angeeignet habe.
Nächste Schritte
Es ist jetzt ein funktionierendes Skript zum Extrahieren von Tabellen- und Textdaten aus der PDF-Datei mit der Depotbankerklärung vorhanden.
Bevor ich fortfahre, werde ich einige Tests durchführen, um zu sehen, ob das Skript wie erwartet funktioniert.
--Ende
Das obige ist der detaillierte Inhalt von# | PDF-Datenextraktion automatisieren: Erstellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Wie wirkt sich die Auswahl zwischen Listen und Arrays auf die Gesamtleistung einer Python -Anwendung aus, die sich mit großen Datensätzen befasst?May 03, 2025 am 12:11 AM
Wie wirkt sich die Auswahl zwischen Listen und Arrays auf die Gesamtleistung einer Python -Anwendung aus, die sich mit großen Datensätzen befasst?May 03, 2025 am 12:11 AMForHandlinglargedatasetsinpython, Usenumpyarraysforbetterperformance.1) Numpyarraysarememory-Effiction und FasterFornumericaloperations.2) meidenunnötiger Anbieter.3) HebelVectorisationFecedTimeComplexity.4) ManagemememoryusageSageWithEffizienceDeffictureWitheseffizienz
 Erklären Sie, wie das Speicher für Listen gegenüber Arrays in Python zugewiesen wird.May 03, 2025 am 12:10 AM
Erklären Sie, wie das Speicher für Listen gegenüber Arrays in Python zugewiesen wird.May 03, 2025 am 12:10 AMInpython, listEUSUutsynamicMemoryAllocationWithover-Accocation, whilenumpyarraysalcodeFixedMemory.1) ListSallocatemoremoryThanneded intellig, vereitelte, dass die sterbliche Größe von Zeitpunkte, OfferingPredictableSageStoageStloseflexeflexibilität.
 Wie geben Sie den Datentyp der Elemente in einem Python -Array an?May 03, 2025 am 12:06 AM
Wie geben Sie den Datentyp der Elemente in einem Python -Array an?May 03, 2025 am 12:06 AMInpython, youcansspecthedatatypeyFelemeremodelerernspant.1) Usenpynernrump.1) Usenpynerp.dloatp.Ploatm64, Formor -Präzise -Preciscontrolatatypen.
 Was ist Numpy und warum ist es wichtig für das numerische Computing in Python?May 03, 2025 am 12:03 AM
Was ist Numpy und warum ist es wichtig für das numerische Computing in Python?May 03, 2025 am 12:03 AMNumpyisessentialfornumericalComputingInpythonduetoitsSpeed, GedächtnisEffizienz und kompetentiertemaMatematical-Funktionen.1) ITSFACTBECAUSPERFORMATIONSOPERATIONS.2) NumpyarraysSaremoremory-Effecthonpythonlists.3) iTofferSAgyarraysAremoremory-Effizieren
 Diskutieren Sie das Konzept der 'zusammenhängenden Speicherzuweisung' und seine Bedeutung für Arrays.May 03, 2025 am 12:01 AM
Diskutieren Sie das Konzept der 'zusammenhängenden Speicherzuweisung' und seine Bedeutung für Arrays.May 03, 2025 am 12:01 AMContInuuousMemoryAllocationScrucialforAraysBecauseAltoLowsFofficy und Fastelement Access.1) iTenablesconstantTimeAccess, O (1), Duetodirectaddresscalculation.2) itimProvesefficienceByallowing -MultipleTeLementFetchesperCacheline.3) Es wird gestellt
 Wie schneiden Sie eine Python -Liste?May 02, 2025 am 12:14 AM
Wie schneiden Sie eine Python -Liste?May 02, 2025 am 12:14 AMSlicingPapythonListisDoneUsingthesyntaxlist [Start: Stop: Stufe] .here'Showitworks: 1) StartIndexoFtheFirstelementtoinclude.2) stopiStheIndexoFtheFirstelementtoexclude.3) StepisTheincrementBetweenelesfulFulForForforexcractioningPorporionsporporionsPorporionsporporesporsporsporsporsporsporsporsporsporionsporsPorsPorsPorsPorsporsporsporsporsporsporsAntionsporsporesporesporesporsPorsPorsporsPorsPorsporsporspors,
 Was sind einige gängige Operationen, die an Numpy -Arrays ausgeführt werden können?May 02, 2025 am 12:09 AM
Was sind einige gängige Operationen, die an Numpy -Arrays ausgeführt werden können?May 02, 2025 am 12:09 AMNumpyallowsforvariousoperationssonarrays: 1) BasicarithmeticliKeaddition, Subtraktion, Multiplikation und Division; 2) AdvancedoperationssuchasmatrixMultiplication;
 Wie werden Arrays in der Datenanalyse mit Python verwendet?May 02, 2025 am 12:09 AM
Wie werden Arrays in der Datenanalyse mit Python verwendet?May 02, 2025 am 12:09 AMArraysinpython, insbesondere ThroughNumpyandpandas, areessentialfordataanalyse, öfterspeedandeffizienz.1) numpyarraysenableAnalysHandlingoflargedatasets und CompompexoperationslikemovingAverages.2) Pandasextendsnumpy'ScapaBilitiesWithDaTataforsForstruc


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

