


GitHub: https://github.com/chatsapi/ChatsAPI
Bibliothek: https://pypi.org/project/chatsapi/
Künstliche Intelligenz hat die Industrie verändert, doch ihr effektiver Einsatz bleibt eine gewaltige Herausforderung. Komplexe Frameworks, langsame Reaktionszeiten und steile Lernkurven stellen sowohl für Unternehmen als auch für Entwickler Hürden dar. Hier kommt ChatsAPI ins Spiel – ein bahnbrechendes, leistungsstarkes KI-Agenten-Framework, das unübertroffene Geschwindigkeit, Flexibilität und Einfachheit bietet.
In diesem Artikel erfahren Sie, was ChatsAPI einzigartig macht, warum es bahnbrechend ist und wie es Entwicklern ermöglicht, intelligente Systeme mit beispielloser Leichtigkeit und Effizienz zu erstellen.
Was macht ChatsAPI einzigartig?
ChatsAPI ist nicht nur ein weiteres KI-Framework; Es ist eine Revolution in der KI-gesteuerten Interaktion. Hier ist der Grund:
- Unübertroffene Leistung ChatsAPI nutzt SBERT-Einbettungen, HNSWlib und BM25 Hybrid Search, um das schnellste Abfrageabgleichssystem bereitzustellen, das jemals entwickelt wurde.
Geschwindigkeit: Mit Reaktionszeiten von unter einer Millisekunde ist ChatsAPI das weltweit schnellste KI-Agent-Framework. Die von HNSWlib unterstützte Suche gewährleistet einen blitzschnellen Abruf von Routen und Wissen, selbst bei großen Datenmengen.
Effizienz: Der hybride Ansatz von SBERT und BM25 kombiniert semantisches Verständnis mit traditionellen Ranking-Systemen und gewährleistet so sowohl Geschwindigkeit als auch Genauigkeit.
Nahtlose Integration mit LLMs
ChatsAPI unterstützt hochmoderne Large Language Models (LLMs) wie OpenAI, Gemini, LlamaAPI und Ollama. Es vereinfacht die Komplexität der Integration von LLMs in Ihre Anwendungen, sodass Sie sich auf die Entwicklung besserer Erfahrungen konzentrieren können.Dynamische Routenanpassung
ChatsAPI nutzt Natural Language Understanding (NLU), um Benutzeranfragen dynamisch und mit beispielloser Präzision vordefinierten Routen zuzuordnen.
Registrieren Sie Routen mühelos mit Dekoratoren wie @trigger.
Verwenden Sie die Parameterextraktion mit @extract, um die Eingabeverarbeitung zu vereinfachen, egal wie komplex Ihr Anwendungsfall ist.
- Einfachheit im Design Wir glauben, dass Kraft und Einfachheit nebeneinander existieren können. Mit ChatsAPI können Entwickler in wenigen Minuten robuste KI-gesteuerte Systeme erstellen. Kein Ringen mehr mit komplizierten Setups oder Konfigurationen.
Die Vorteile von ChatsAPI
Hochleistungsabfrageverarbeitung
Herkömmliche KI-Systeme haben entweder mit Geschwindigkeit oder Genauigkeit zu kämpfen – ChatsAPI bietet beides. Ganz gleich, ob es darum geht, die beste Übereinstimmung in einer riesigen Wissensdatenbank zu finden oder große Mengen an Anfragen zu bearbeiten, ChatsAPI zeichnet sich aus.
Flexibles Framework
ChatsAPI passt sich jedem Anwendungsfall an, unabhängig davon, ob Sie Folgendes erstellen:
- Kundensupport-Chatbots.
- Intelligente Suchsysteme.
- KI-gestützte Assistenten für E-Commerce, Gesundheitswesen oder Bildung.
Entwickelt für Entwickler
ChatsAPI wurde von Entwicklern für Entwickler entwickelt und bietet:
- Schnellstart: Richten Sie Ihre Umgebung ein, definieren Sie Routen und gehen Sie in nur wenigen Schritten live.
- Anpassung: Passen Sie das Verhalten mit Dekorateuren an und passen Sie die Leistung an Ihre spezifischen Bedürfnisse an.
- Einfache LLM-Integration: Wechseln Sie mit minimalem Aufwand zwischen unterstützten LLMs wie OpenAI oder Gemini.
Wie funktioniert ChatsAPI?
Im Kern funktioniert ChatsAPI durch einen dreistufigen Prozess:
- Routen registrieren: Verwenden Sie den @trigger-Dekorator, um Routen zu definieren und sie Ihren Funktionen zuzuordnen.
- Suchen und Abgleichen: ChatsAPI verwendet SBERT-Einbettungen und die BM25-Hybridsuche, um Benutzereingaben dynamisch mit den richtigen Routen abzugleichen.
- Parameter extrahieren: Mit dem @extract-Dekorator extrahiert und validiert ChatsAPI automatisch Parameter und erleichtert so die Handhabung komplexer Eingaben.
Das Ergebnis? Ein System, das schnell, genau und unglaublich einfach zu bedienen ist.
Anwendungsfälle
Kundensupport
Automatisieren Sie Kundeninteraktionen mit blitzschneller Anfragelösung. ChatsAPI stellt sicher, dass Benutzer sofort relevante Antworten erhalten, was die Zufriedenheit erhöht und die Betriebskosten senkt.Wissensdatenbanksuche
Ermöglichen Sie Benutzern die Suche in umfangreichen Wissensdatenbanken mit semantischem Verständnis. Der hybride SBERT-BM25-Ansatz gewährleistet genaue, kontextbezogene Ergebnisse.Konversations-KI
Erstellen Sie dialogorientierte KI-Agenten, die Benutzereingaben in Echtzeit verstehen und sich daran anpassen. ChatsAPI lässt sich nahtlos in Top-LLMs integrieren, um natürliche, ansprechende Gespräche zu führen.
Warum sollte es Sie interessieren?
Andere Frameworks versprechen Flexibilität oder Leistung – aber keines kann beides so liefern wie ChatsAPI. Wir haben ein Framework erstellt, das:
- Schneller als alles andere auf dem Markt.
- Einfacher einzurichten und zu verwenden.
- Intelligenter, mit seiner einzigartigen Hybrid-Suchmaschine, die semantische und schlüsselwortbasierte Ansätze kombiniert.
ChatsAPI ermöglicht es Entwicklern, das volle Potenzial der KI auszuschöpfen, ohne sich mit Komplexität oder langsamer Leistung herumschlagen zu müssen.
So fangen Sie an
Der Einstieg in ChatsAPI ist einfach:
- Installieren Sie das Framework:
pip install chatsapi
- Definieren Sie Ihre Routen:
from chatsapi import ChatsAPI
chat = ChatsAPI()
@chat.trigger("Hello")
async def greet(input_text):
return "Hi there!"
- Extrahieren Sie einige Daten aus der Nachricht
from chatsapi import ChatsAPI
chat = ChatsAPI()
@chat.trigger("Need help with account settings.")
@chat.extract([
("account_number", "Account number (a nine digit number)", int, None),
("holder_name", "Account holder's name (a person name)", str, None)
])
async def account_help(chat_message: str, extracted: dict):
return {"message": chat_message, "extracted": extracted}
Run your message (with no LLM)
@app.post("/chat")
async def message(request: RequestModel, response: Response):
reply = await chat.run(request.message)
return {"message": reply}
- Gespräche (mit LLM) – Vollständiges Beispiel
import os
from dotenv import load_dotenv
from fastapi import FastAPI, Request, Response
from pydantic import BaseModel
from chatsapi.chatsapi import ChatsAPI
# Load environment variables from .env file
load_dotenv()
app = FastAPI() # instantiate FastAPI or your web framework
chat = ChatsAPI( # instantiate ChatsAPI
llm_type="gemini",
llm_model="models/gemini-pro",
llm_api_key=os.getenv("GOOGLE_API_KEY"),
)
# chat trigger - 1
@chat.trigger("Want to cancel a credit card.")
@chat.extract([("card_number", "Credit card number (a 12 digit number)", str, None)])
async def cancel_credit_card(chat_message: str, extracted: dict):
return {"message": chat_message, "extracted": extracted}
# chat trigger - 2
@chat.trigger("Need help with account settings.")
@chat.extract([
("account_number", "Account number (a nine digit number)", int, None),
("holder_name", "Account holder's name (a person name)", str, None)
])
async def account_help(chat_message: str, extracted: dict):
return {"message": chat_message, "extracted": extracted}
# request model
class RequestModel(BaseModel):
message: str
# chat conversation
@app.post("/chat")
async def message(request: RequestModel, response: Response, http_request: Request):
session_id = http_request.cookies.get("session_id")
reply = await chat.conversation(request.message, session_id)
return {"message": f"{reply}"}
# set chat session
@app.post("/set-session")
def set_session(response: Response):
session_id = chat.set_session()
response.set_cookie(key="session_id", value=session_id)
return {"message": "Session set"}
# end chat session
@app.post("/end-session")
def end_session(response: Response, http_request: Request):
session_id = http_request.cookies.get("session_id")
chat.end_session(session_id)
response.delete_cookie("session_id")
return {"message": "Session ended"}
- Routen, die LLM-Abfragen einhalten – Einzelabfrage
await chat.query(request.message)
Benchmarks
Herkömmliche LLM (API)-basierte Methoden dauern in der Regel etwa vier Sekunden pro Anfrage. Im Gegensatz dazu verarbeitet ChatsAPI Anfragen in weniger als einer Sekunde, oft innerhalb von Millisekunden, ohne LLM-API-Aufrufe durchzuführen.
Durchführung einer Chat-Routing-Aufgabe innerhalb von 472 ms (kein Cache)

Durchführung einer Chat-Routing-Aufgabe innerhalb von 21 ms (nach dem Cache)

Durchführung einer Chat-Routing-Datenextraktionsaufgabe innerhalb von 862 ms (kein Cache)

Demonstration seiner Konversationsfähigkeiten mit der WhatsApp Cloud API
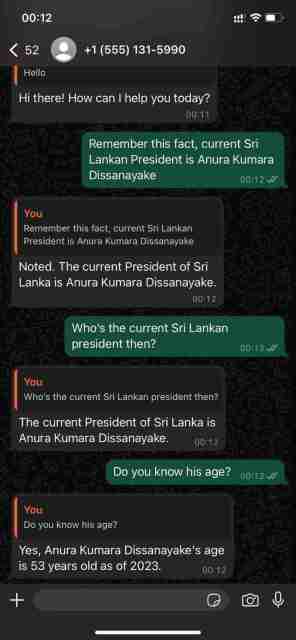
ChatsAPI – Funktionshierarchie

ChatsAPI ist mehr als nur ein Framework; Es ist ein Paradigmenwechsel in der Art und Weise, wie wir KI-Systeme aufbauen und mit ihnen interagieren. Durch die Kombination von Geschwindigkeit, Genauigkeit und Benutzerfreundlichkeit setzt ChatsAPI einen neuen Maßstab für KI-Agent-Frameworks.
Schließen Sie sich noch heute der Revolution an und erfahren Sie, warum ChatsAPI die KI-Landschaft verändert.
Bereit zum Eintauchen? Starten Sie jetzt mit ChatsAPI und erleben Sie die Zukunft der KI-Entwicklung.
Das obige ist der detaillierte Inhalt vonChatsAPI – Das weltweit schnellste KI-Agent-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python: Ein tiefes Eintauchen in Zusammenstellung und InterpretationMay 12, 2025 am 12:14 AM
Python: Ein tiefes Eintauchen in Zusammenstellung und InterpretationMay 12, 2025 am 12:14 AMPythonusesahybridmodelofCompilation und Interpretation: 1) thepythonInterPreterCompilessourceCodeIntoplatform-unintenpendentBytecode.2) Thepythonvirtualmachine (PVM) ThenexexexexecthisByTeCode, BalancingeAnsewusewithperformance.
 Ist Python eine interpretierte oder eine kompilierte Sprache, und warum ist es wichtig?May 12, 2025 am 12:09 AM
Ist Python eine interpretierte oder eine kompilierte Sprache, und warum ist es wichtig?May 12, 2025 am 12:09 AMPythonisbothinterpreted und kompiliert.1) ItscompiledToByteCodeForPortabilityAcrossplatform.2) thytecodeTheninterpreted, und das ErlaubnisfordyNamictyPingandRapidDevelopment zulässt, obwohl es sich
 Für Schleife vs während der Schleife in Python: Schlüsselunterschiede erklärtMay 12, 2025 am 12:08 AM
Für Schleife vs während der Schleife in Python: Schlüsselunterschiede erklärtMay 12, 2025 am 12:08 AMForloopsaridealWenyouKnowtHenumberofofiterationssinadvance, während whileloopsarebetterForsituationswhereyouneedtoloopuntilaconditionismet.forloopsaremoreffictionAndable, geeigneter Verfaserungsverlust, whereaswiloopsofofermorcontrolanduseusefulfulf
 Für und während Schleifen: ein praktischer LeitfadenMay 12, 2025 am 12:07 AM
Für und während Schleifen: ein praktischer LeitfadenMay 12, 2025 am 12:07 AMForloopsareusedwhenthenumberofiterationsisknowninadvance,whilewhileloopsareusedwhentheiterationsdependonacondition.1)Forloopsareidealforiteratingoversequenceslikelistsorarrays.2)Whileloopsaresuitableforscenarioswheretheloopcontinuesuntilaspecificcond
 Python: Ist es wirklich interpretiert? Die Mythen entlarvenMay 12, 2025 am 12:05 AM
Python: Ist es wirklich interpretiert? Die Mythen entlarvenMay 12, 2025 am 12:05 AMPythonisnotpurelyinterpretiert; itusesahybridapproachofByteCodecompilation undruntimeinterpretation.1) PythoncompilessourcecodeIntoBytecode, die ISthenexecutBythepythonvirtualmachine (Pvm)
 Python -Verkettungslisten mit demselben ElementMay 11, 2025 am 12:08 AM
Python -Verkettungslisten mit demselben ElementMay 11, 2025 am 12:08 AMToconcatenatelistsinpythonWithThesameElements, Verwendung: 1) Die Operatortokeepduplikate, 2) asettoremoveduplicate, or3) listenConpRectionforControloverDuplikate, EvermethodhasDifferentPerformanceInDormplocate.
 Interpretiert gegen kompilierte Sprachen: Pythons PlatzMay 11, 2025 am 12:07 AM
Interpretiert gegen kompilierte Sprachen: Pythons PlatzMay 11, 2025 am 12:07 AMPythonisaninterpretedLuage, OfferingaseofuseandflexibilitätsbutfacingPerformancelimitationsincriticalApplications.1) InterpretedLanguages LikePythonexecutine-by-Line, ermöglicht, dassmediateFeedbackandrapidPrototyping.2) CompiledLanguagesslikec/C.5.
 Für und während der Schleifen: Wann benutzt du jeweils in Python?May 11, 2025 am 12:05 AM
Für und während der Schleifen: Wann benutzt du jeweils in Python?May 11, 2025 am 12:05 AMUseforloopswhenthenumberofofiterationssisknowninadvance und wileloopswhenCiterationsDependonacondition.1) Forloopsardealforsequencelistorranges.2) Während


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

