


Kauf mir einen Kaffee☕
*Mein Beitrag erklärt EMNIST.
EMNIST() kann den EMNIST-Datensatz wie unten gezeigt verwenden:
*Memos:
- Das 1. Argument ist root(Required-Type:str oder pathlib.Path). *Ein absoluter oder relativer Pfad ist möglich.
- Das 2. Argument ist split(Required-Type:str). *Es können „byclass“, „bymerge“, „balanced“, „letters“, „digits“ oder „mnist“ eingestellt werden.
- Es gibt ein Zugargument (Optional-Default:False-Type:float):
*Memos:
- Für split="byclass" und split="byclass" werden, wenn es „True“ ist, Trainingsdaten (697.932 Bilder) verwendet, während, wenn es „False“ ist, Testdaten (116.323 Bilder) verwendet werden.
- Für split="balanced" werden, wenn es „True“ ist, Trainingsdaten (112.800 Bilder) verwendet, während, wenn es „False“ ist, Testdaten (188.00 Bilder) verwendet werden.
- Wenn „split="letters“ wahr ist, werden Trainingsdaten (124.800 Bilder) verwendet, während bei „falsch" Testdaten (20.800 Bilder) verwendet werden.
- Wenn „split="digits" „True“ ist, werden Trainingsdaten (240.000 Bilder) verwendet, während bei „False“ Testdaten (40.000 Bilder) verwendet werden.
- Wenn „split="mnist" wahr ist, werden Trainingsdaten (60.000 Bilder) verwendet, während bei „falsch“ Testdaten (10.000 Bilder) verwendet werden.
- Es gibt ein Transformationsargument (Optional-Default:None-Type:callable).
- Es gibt das Argument target_transform (Optional-Default:None-Type:callable).
- Es gibt ein Download-Argument (Optional-Default:False-Type:bool):
*Memos:
- Wenn es wahr ist, wird der Datensatz aus dem Internet heruntergeladen und in das Stammverzeichnis extrahiert (entpackt).
- Wenn es „True“ ist und der Datensatz bereits heruntergeladen wurde, wird er extrahiert.
- Wenn es „True“ ist und der Datensatz bereits heruntergeladen und extrahiert wurde, passiert nichts.
- Es sollte „False“ sein, wenn der Datensatz bereits heruntergeladen und extrahiert wurde, da es schneller ist.
- Sie können den Datensatz hier manuell herunterladen und extrahieren, um ihn z. data/EMNIST/raw/.
- Es gibt den Fehler, dass die Bilder standardmäßig gespiegelt und um 90 Grad gegen den Uhrzeigersinn gedreht werden, sodass sie transformiert werden sollten.
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass"
)
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=None,
target_transform=None,
download=False
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
len(train_data), len(test_data)
# 697932 116323
train_data
# Dataset EMNIST
# Number of datapoints: 697932
# Root location: data
# Split: Train
train_data.root
# 'data'
train_data.split
# 'byclass'
train_data.train
# True
print(train_data.transform)
# None
print(train_data.target_transform)
# None
train_data.download
# <bound method emnist.download of dataset emnist number datapoints: root location: data split: train>
train_data[0]
# (<pil.image.image image mode="L" size="28x28">, 35)
train_data[1]
# (<pil.image.image image mode="L" size="28x28">, 36)
train_data[2]
# (<pil.image.image image mode="L" size="28x28">, 6)
train_data[3]
# (<pil.image.image image mode="L" size="28x28">, 3)
train_data[4]
# (<pil.image.image image mode="L" size="28x28">, 22)
train_data.classes
# ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
# 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
# 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
# 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
# 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
</pil.image.image></pil.image.image></pil.image.image></pil.image.image></pil.image.image></bound>
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass",
train=True
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
import matplotlib.pyplot as plt
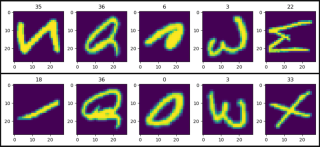
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
from torchvision.datasets import EMNIST
from torchvision.transforms import v2
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
test_data = EMNIST(
root="data",
split="byclass",
train=False,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
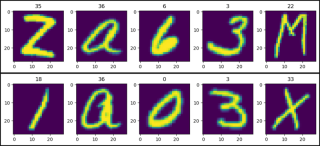
import matplotlib.pyplot as plt
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
Das obige ist der detaillierte Inhalt vonEMNIST in PyTorch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Wie wirkt sich die Auswahl zwischen Listen und Arrays auf die Gesamtleistung einer Python -Anwendung aus, die sich mit großen Datensätzen befasst?May 03, 2025 am 12:11 AM
Wie wirkt sich die Auswahl zwischen Listen und Arrays auf die Gesamtleistung einer Python -Anwendung aus, die sich mit großen Datensätzen befasst?May 03, 2025 am 12:11 AMForHandlinglargedatasetsinpython, Usenumpyarraysforbetterperformance.1) Numpyarraysarememory-Effiction und FasterFornumericaloperations.2) meidenunnötiger Anbieter.3) HebelVectorisationFecedTimeComplexity.4) ManagemememoryusageSageWithEffizienceDeffictureWitheseffizienz
 Erklären Sie, wie das Speicher für Listen gegenüber Arrays in Python zugewiesen wird.May 03, 2025 am 12:10 AM
Erklären Sie, wie das Speicher für Listen gegenüber Arrays in Python zugewiesen wird.May 03, 2025 am 12:10 AMInpython, listEUSUutsynamicMemoryAllocationWithover-Accocation, whilenumpyarraysalcodeFixedMemory.1) ListSallocatemoremoryThanneded intellig, vereitelte, dass die sterbliche Größe von Zeitpunkte, OfferingPredictableSageStoageStloseflexeflexibilität.
 Wie geben Sie den Datentyp der Elemente in einem Python -Array an?May 03, 2025 am 12:06 AM
Wie geben Sie den Datentyp der Elemente in einem Python -Array an?May 03, 2025 am 12:06 AMInpython, youcansspecthedatatypeyFelemeremodelerernspant.1) Usenpynernrump.1) Usenpynerp.dloatp.Ploatm64, Formor -Präzise -Preciscontrolatatypen.
 Was ist Numpy und warum ist es wichtig für das numerische Computing in Python?May 03, 2025 am 12:03 AM
Was ist Numpy und warum ist es wichtig für das numerische Computing in Python?May 03, 2025 am 12:03 AMNumpyisessentialfornumericalComputingInpythonduetoitsSpeed, GedächtnisEffizienz und kompetentiertemaMatematical-Funktionen.1) ITSFACTBECAUSPERFORMATIONSOPERATIONS.2) NumpyarraysSaremoremory-Effecthonpythonlists.3) iTofferSAgyarraysAremoremory-Effizieren
 Diskutieren Sie das Konzept der 'zusammenhängenden Speicherzuweisung' und seine Bedeutung für Arrays.May 03, 2025 am 12:01 AM
Diskutieren Sie das Konzept der 'zusammenhängenden Speicherzuweisung' und seine Bedeutung für Arrays.May 03, 2025 am 12:01 AMContInuuousMemoryAllocationScrucialforAraysBecauseAltoLowsFofficy und Fastelement Access.1) iTenablesconstantTimeAccess, O (1), Duetodirectaddresscalculation.2) itimProvesefficienceByallowing -MultipleTeLementFetchesperCacheline.3) Es wird gestellt
 Wie schneiden Sie eine Python -Liste?May 02, 2025 am 12:14 AM
Wie schneiden Sie eine Python -Liste?May 02, 2025 am 12:14 AMSlicingPapythonListisDoneUsingthesyntaxlist [Start: Stop: Stufe] .here'Showitworks: 1) StartIndexoFtheFirstelementtoinclude.2) stopiStheIndexoFtheFirstelementtoexclude.3) StepisTheincrementBetweenelesfulFulForForforexcractioningPorporionsporporionsPorporionsporporesporsporsporsporsporsporsporsporsporionsporsPorsPorsPorsPorsporsporsporsporsporsporsAntionsporsporesporesporesporsPorsPorsporsPorsPorsporsporspors,
 Was sind einige gängige Operationen, die an Numpy -Arrays ausgeführt werden können?May 02, 2025 am 12:09 AM
Was sind einige gängige Operationen, die an Numpy -Arrays ausgeführt werden können?May 02, 2025 am 12:09 AMNumpyallowsforvariousoperationssonarrays: 1) BasicarithmeticliKeaddition, Subtraktion, Multiplikation und Division; 2) AdvancedoperationssuchasmatrixMultiplication;
 Wie werden Arrays in der Datenanalyse mit Python verwendet?May 02, 2025 am 12:09 AM
Wie werden Arrays in der Datenanalyse mit Python verwendet?May 02, 2025 am 12:09 AMArraysinpython, insbesondere ThroughNumpyandpandas, areessentialfordataanalyse, öfterspeedandeffizienz.1) numpyarraysenableAnalysHandlingoflargedatasets und CompompexoperationslikemovingAverages.2) Pandasextendsnumpy'ScapaBilitiesWithDaTataforsForstruc


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

Dreamweaver CS6
Visuelle Webentwicklungstools

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

