
Heim >Backend-Entwicklung >Python-Tutorial >So durchsuchen Sie Google-Suchergebnisse mit Python
So durchsuchen Sie Google-Suchergebnisse mit Python

- Susan SarandonOriginal
- 2024-12-05 12:31:10620Durchsuche
Scraping Google Search bietet wichtige SERP-Analyse-, SEO-Optimierungs- und Datenerfassungsfunktionen. Moderne Schabewerkzeuge machen diesen Prozess schneller und zuverlässiger.
Eines unserer Community-Mitglieder hat diesen Blog als Beitrag zum Crawlee-Blog geschrieben. Wenn Sie solche Blogs zum Crawlee-Blog beitragen möchten, kontaktieren Sie uns bitte auf unserem Discord-Kanal.
In dieser Anleitung erstellen wir mit Crawlee für Python einen Google-Such-Scraper, der das Ergebnisranking und die Paginierung verarbeiten kann.
Wir erstellen einen Schaber, der:
- Extrahiert Titel, URLs und Beschreibungen aus Suchergebnissen
- Verarbeitet mehrere Suchanfragen
- Verfolgt Ranglistenpositionen
- Verarbeitet mehrere Ergebnisseiten
- Speichert Daten in einem strukturierten Format
Voraussetzungen
- Python 3.7 oder höher
- Grundlegendes Verständnis von HTML- und CSS-Selektoren
- Vertrautheit mit Web-Scraping-Konzepten
- Crawlee für Python v0.4.2 oder höher
Projektaufbau
-
Installieren Sie Crawlee mit den erforderlichen Abhängigkeiten:
pipx install crawlee[beautifulsoup,curl-impersonate]
-
Erstellen Sie ein neues Projekt mit Crawlee CLI:
pipx run crawlee create crawlee-google-search
Wenn Sie dazu aufgefordert werden, wählen Sie „Beautifulsoup“ als Vorlagentyp aus.
-
Navigieren Sie zum Projektverzeichnis und schließen Sie die Installation ab:
cd crawlee-google-search poetry install
Entwicklung des Google Search Scrapers in Python
1. Daten für die Extraktion definieren
Zuerst definieren wir unseren Extraktionsbereich. Die Suchergebnisse von Google umfassen jetzt Karten, bemerkenswerte Personen, Unternehmensdetails, Videos, häufig gestellte Fragen und viele andere Elemente. Wir konzentrieren uns auf die Analyse von Standardsuchergebnissen mit Rankings.
Das extrahieren wir:

Lassen Sie uns überprüfen, ob wir die erforderlichen Daten aus dem HTML-Code der Seite extrahieren können oder ob wir eine tiefergehende Analyse oder JS-Rendering benötigen. Beachten Sie, dass diese Überprüfung empfindlich auf HTML-Tags reagiert:

Basierend auf den von der Seite erhaltenen Daten sind alle notwendigen Informationen im HTML-Code vorhanden. Daher können wir beautifulsoup_crawler verwenden.
Die Felder, die wir extrahieren werden:
- Suchergebnistitel
- URLs
- Beschreibungstext
- Ranking-Positionen
2. Konfigurieren Sie den Crawler
Erstellen wir zunächst die Crawler-Konfiguration.
Wir verwenden CurlImpersonateHttpClient als unseren http_client mit voreingestellten Headern und Imitationen, die für den Chrome-Browser relevant sind.
Wir konfigurieren auch ConcurrencySettings, um die Scraping-Aggressivität zu steuern. Dies ist wichtig, um eine Blockierung durch Google zu vermeiden.
Wenn Sie Daten intensiver extrahieren müssen, sollten Sie die Einrichtung von ProxyConfiguration in Betracht ziehen.
pipx install crawlee[beautifulsoup,curl-impersonate]
3. Implementierung der Datenextraktion
Lassen Sie uns zunächst den HTML-Code der Elemente analysieren, die wir extrahieren müssen:

Es gibt einen offensichtlichen Unterschied zwischen lesbaren ID-Attributen und generierten Klassennamen und anderen Attributen. Beim Erstellen von Selektoren für die Datenextraktion sollten Sie alle generierten Attribute ignorieren. Selbst wenn Sie gelesen haben, dass Google seit N Jahren ein bestimmtes generiertes Tag verwendet, sollten Sie sich nicht darauf verlassen – dies spiegelt Ihre Erfahrung beim Schreiben von robustem Code wider.
Da wir nun die HTML-Struktur verstanden haben, implementieren wir die Extraktion. Da unser Crawler nur einen Seitentyp verarbeitet, können wir ihn mit router.default_handler verarbeiten. Innerhalb des Handlers verwenden wir BeautifulSoup, um jedes Suchergebnis zu durchlaufen und Daten wie Titel, URL und text_widget zu extrahieren, während wir die Ergebnisse speichern.
pipx run crawlee create crawlee-google-search
4. Umgang mit Paginierung
Da die Google-Ergebnisse von der IP-Geolokalisierung der Suchanfrage abhängen, können wir uns bei der Paginierung nicht auf den Linktext verlassen. Wir müssen einen ausgefeilteren CSS-Selektor erstellen, der unabhängig von Geolokalisierung und Spracheinstellungen funktioniert.
Der Parameter max_crawl_ Depth steuert, wie viele Seiten unser Crawler scannen soll. Sobald wir unseren robusten Selektor haben, müssen wir nur noch den Link zur nächsten Seite abrufen und ihn zur Warteschlange des Crawlers hinzufügen.
Um effizientere Selektoren zu schreiben, lernen Sie die Grundlagen der CSS- und XPath-Syntax.
cd crawlee-google-search poetry install
5. Exportieren von Daten in das CSV-Format
Da wir alle Suchergebnisdaten in einem praktischen Tabellenformat wie CSV speichern möchten, können wir einfach den Methodenaufruf export_data direkt nach dem Ausführen des Crawlers hinzufügen:
from crawlee.beautifulsoup_crawler import BeautifulSoupCrawler
from crawlee.http_clients.curl_impersonate import CurlImpersonateHttpClient
from crawlee import ConcurrencySettings, HttpHeaders
async def main() -> None:
concurrency_settings = ConcurrencySettings(max_concurrency=5, max_tasks_per_minute=200)
http_client = CurlImpersonateHttpClient(impersonate="chrome124",
headers=HttpHeaders({"referer": "https://www.google.com/",
"accept-language": "en",
"accept-encoding": "gzip, deflate, br, zstd",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}))
crawler = BeautifulSoupCrawler(
max_request_retries=1,
concurrency_settings=concurrency_settings,
http_client=http_client,
max_requests_per_crawl=10,
max_crawl_depth=5
)
await crawler.run(['https://www.google.com/search?q=Apify'])
6. Fertigstellung des Google Search Scrapers
Obwohl unsere zentrale Crawler-Logik funktioniert, haben Sie vielleicht bemerkt, dass unseren Ergebnissen derzeit Informationen zur Rangfolge fehlen. Um unseren Scraper zu vervollständigen, müssen wir eine ordnungsgemäße Verfolgung der Rangfolge implementieren, indem wir Daten zwischen Anfragen mithilfe von „user_data“ in „Request“ weitergeben.
Ändern wir das Skript, um mehrere Abfragen zu verarbeiten und Ranking-Positionen für die Analyse der Suchergebnisse zu verfolgen. Wir legen auch die Crawling-Tiefe als Variable der obersten Ebene fest. Verschieben wir router.default_handler nachroutes.py, damit es der Projektstruktur entspricht:
@crawler.router.default_handler
async def default_handler(context: BeautifulSoupCrawlingContext) -> None:
"""Default request handler."""
context.log.info(f'Processing {context.request} ...')
for item in context.soup.select("div#search div#rso div[data-hveid][lang]"):
data = {
'title': item.select_one("h3").get_text(),
"url": item.select_one("a").get("href"),
"text_widget": item.select_one("div[style*='line']").get_text(),
}
await context.push_data(data)
Ändern wir auch den Handler, um die Felder query und order_no sowie eine grundlegende Fehlerbehandlung hinzuzufügen:
await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a")
Und wir sind fertig!
Unser Google-Such-Crawler ist fertig. Schauen wir uns die Ergebnisse in der Datei google_ranked.csv an:
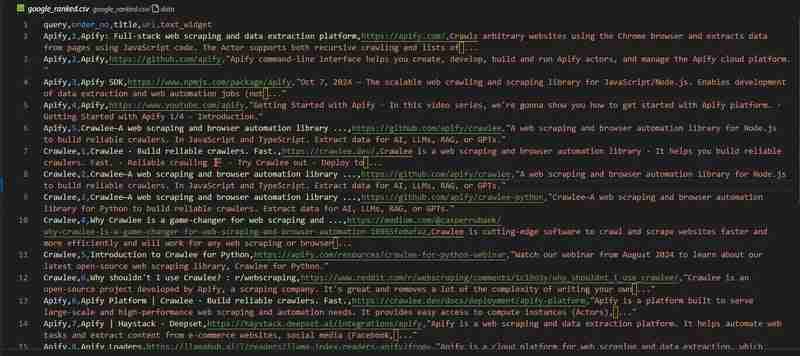
Das Code-Repository ist auf GitHub verfügbar
Scrapen Sie die Google-Suchergebnisse mit Apify
Wenn Sie an einem Großprojekt arbeiten, das Millionen von Datenpunkten erfordert, wie das in diesem Artikel über die Google-Ranking-Analyse vorgestellte Projekt, benötigen Sie möglicherweise eine fertige Lösung.
Erwägen Sie die Verwendung des Google Search Results Scraper vom Apify-Team.
Es bietet wichtige Funktionen wie:
- Proxy-Unterstützung
- Skalierbarkeit für die Extraktion großer Datenmengen
- Geolocation-Kontrolle
- Integration mit externen Diensten wie Zapier, Make, Airbyte, LangChain und anderen
Mehr erfahren Sie im Apify-Blog
Was wirst du kratzen?
In diesem Blog haben wir Schritt für Schritt untersucht, wie man einen Crawler für die Google-Suche erstellt, der Ranking-Daten sammelt. Wie Sie diesen Datensatz analysieren, liegt bei Ihnen!
Zur Erinnerung: Den vollständigen Projektcode finden Sie auf GitHub.
Ich würde gerne glauben, dass ich in 5 Jahren einen Artikel zum Thema „Wie extrahiert man Daten aus der besten Suchmaschine für LLMs“ schreiben muss, aber ich vermute, dass dieser Artikel in 5 Jahren immer noch relevant sein wird.
Das obige ist der detaillierte Inhalt vonSo durchsuchen Sie Google-Suchergebnisse mit Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!