
 Backend-EntwicklungPython-TutorialAufbau einer Zustandsmaschinenbibliothek mit Hilfe von KI-Tools
Backend-EntwicklungPython-TutorialAufbau einer Zustandsmaschinenbibliothek mit Hilfe von KI-Tools
Während ich auf meine Folgeinterviews wartete, baute ich aus Langeweile eine State-Machine-Bibliothek auf, die von genruler unterstützt wurde. Ich habe früher eines gebaut, genauer gesagt, während meines ersten Jobs nach dem Studium. Diese Implementierung basiert lose auf dem Entwurf, den mein Vorgesetzter damals entworfen hat. Das Projekt zielte auch darauf ab, zu zeigen, wie die Regel DSL genutzt werden kann.
Laut der hilfreichen Zusammenfassung, die eine Google-Suche nach endlichen Zustandsmaschinen ergab (Hervorhebung von mir)
Eine „Finite-State-Machine“ bezeichnet ein Rechenmodell, bei dem sich ein System zu einem bestimmten Zeitpunkt nur in einer begrenzten Anzahl unterschiedlicher Zustände befinden kann und Übergänge zwischen diesen Zuständen durch bestimmte Eingaben ausgelöst werden, was im Wesentlichen ermöglicht Es dient dazu, Informationen auf der Grundlage einer Reihe definierter Bedingungen zu verarbeiten, ohne dass eine unendliche Anzahl von Zuständen möglich ist. „endlich“ bezieht sich hier auf die begrenzte Menge möglicher Zustände, in denen das System existieren kann.
Die Bibliothek erhält ein Wörterbuch, das das Schema der endlichen Zustandsmaschine darstellt. Wir möchten zum Beispiel ein System zur Auftragsverfolgung aufbauen
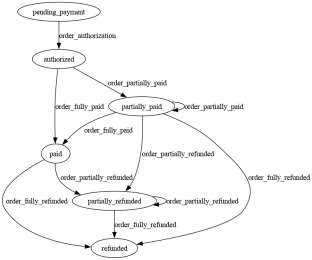
Von Graphviz generiertes Finite-State-Machine-Diagramm
Und das Schema würde in etwa so aussehen (aus Gründen der Übersichtlichkeit in gekürzter YAML-Form)
machine:
initial_state: pending_payment
states:
pending_payment:
name: pending payment
transitions:
order_authorization:
name: order is authorized
destination: authorized
rule: (condition.equal (basic.field "is_authorized") (boolean.tautology))
authorized:
name: authorized
action: authorize_order
transitions:
order_partially_paid:
name: order is partially paid
destination: partially_paid
rule: (boolean.tautology)
order_fully_paid:
name: order is fully paid
destination: paid
rule: (boolean.tautology)
...
Um alles einzurichten, rufen wir an
import genstates
import yaml
import order_processor
with open("states.yaml") as schema:
machine = genstates.Machine(yaml.safe_load(schema), order_processor)
In diesem fiktiven Beispiel erhalten wir also immer dann eine Nutzlast, wenn sich die Reihenfolge ändert. Wenn der Verkäufer beispielsweise die Bestellung bestätigt, erhalten wir
{
"is_authorized": true,
...
}
Wir können dann in der Bibliothek nachsehen
state = machine.initial # assume the order is created transition = machine.get_transition(state, "order_authorization") assert transition.check_condition(payload)
Die Prüfung führt auch eine zusätzliche Validierungsprüfung durch, sofern im Schema definiert. Dies ist hilfreich, wenn Sie dem Anrufer eine Fehlermeldung zurücksenden möchten.
try: assert transition.check_condition(payload) except ValidationFailedError as e: logger.exception(e)
Manchmal wissen wir, dass jedes Mal, wenn die Nutzlast ankommt, sie einen Übergang auslösen sollte, aber wir wissen nicht immer, welcher. Deshalb übergeben wir es einfach an Machine.progress
try: state = machine.progress(state, payload) except ValidationFailedError as e: logger.exception(e)
Sobald wir wissen, welchen Status die Bestellung haben soll, können wir mit dem Schreiben von Code beginnen, um an der Logik zu arbeiten
# fetch the order from database
order = Order.get(id=payload["order_id"])
current_state = machine.states[order.state]
# fetch next state
try:
new_state = machine.progress(current_state, payload)
except ValidationFailedError as e:
# validation failed, do something
logger.exception(e)
return
except MissingTransitionError as e:
# can't find a valid transition from given payload
logger.exception(e)
return
except DuplicateTransitionError as e:
# found more than one transition from given payload
logger.exception(e)
return
# do processing (example)
log = Log.create(order=order, **payload)
log.save()
order.state = new_state.key
order.save()
Idealerweise kann ich auch die Verarbeitungslogik extrahieren, weshalb ich am Anfang order_processor importiert habe. In der Definition des Autorisierungsstatus haben wir auch eine Aktion definiert
authorized:
name: authorized
action: authorize_order
...
Also definieren wir im Modul „order_processor“ eine neue Funktion namens „authorized_order“
def authorize_order(payload):
# do the processing here instead
pass
Damit Folgendes möglich ist, wobei der Statusverwaltungscode vom Rest der Verarbeitungslogik getrennt ist
machine:
initial_state: pending_payment
states:
pending_payment:
name: pending payment
transitions:
order_authorization:
name: order is authorized
destination: authorized
rule: (condition.equal (basic.field "is_authorized") (boolean.tautology))
authorized:
name: authorized
action: authorize_order
transitions:
order_partially_paid:
name: order is partially paid
destination: partially_paid
rule: (boolean.tautology)
order_fully_paid:
name: order is fully paid
destination: paid
rule: (boolean.tautology)
...
Allerdings arbeite ich noch daran und sollte es in der nächsten Version schaffen. Mittlerweile ist es auch in der Lage, etwas Ähnliches wie Kartieren und Reduzieren zu tun, wenn für jeden Zustand eine Aktion definiert ist. Schauen Sie sich gerne den Entwicklungsfortschritt des Projekts an. Und sowohl Genruler als auch Genstates sind jetzt auf PyPI, juhu!
Wie wäre es nun mit der KI-Sache?
Ich habe Codeium Windsurf heruntergeladen, nachdem die Bibliothek einigermaßen benutzbar war. Ich habe es schließlich verwendet, um die Abhängigkeit von Genruler zu beseitigen, und habe dem Projekt Dokumentation und README hinzugefügt. Für Genstates habe ich Cascade verwendet, um Dokumentation, README und Tests zu generieren. Insgesamt kommt es mir so vor, als hätte ich einen mittleren bis höheren Programmierer an meiner Seite, der mir bei Aufgaben hilft, die ich meinen Praktikanten oder sogar Junioren zuweisen würde.
Der größte Teil der Kernlogik stammt immer noch von meiner Seite. So intelligent das Sprachmodell im Moment auch ist, es machen immer noch hier und da Fehler und erfordern daher Aufsicht. Ich habe auch mit dem Modell qwen2.5-coder:7b experimentiert und es funktioniert ziemlich gut, wenn auch aufgrund meiner schlechten Workstation ziemlich langsam. Ich finde den Preis, den Codeium verlangt, fair, wenn ich mein eigenes Produkt bauen und damit Geld verdienen kann.
Während die Generierungsteile gut funktionieren, ist das Schreiben von tatsächlichem Code nicht so toll. Ich bin mir nicht sicher, ob Pylance dort ordnungsgemäß funktioniert, da es proprietär ist, oder ob es an der Vervollständigung von Magic Windsurf liegt. Mein Editor ist nicht mehr in der Lage, Bibliotheken automatisch zu importieren, wenn ich Code schreibe. Wenn ich beispielsweise die Funktion „reduce()“ in meinem Code automatisch vervollständige, wird sie in vscode automatisch aus dem Import von „functools“ in meinen Code eingefügt. Dies ist jedoch beim Windsurfen nicht der Fall, was es etwas irritierend macht. Da dies jedoch neu ist, sollte das Codierungserlebnis im Laufe der Zeit verbessert werden.
Andererseits bin ich immer noch auf der Suche nach einem einfacheren Editor, und Zed erregt meine Aufmerksamkeit. Da mein Surface Book 2 jedoch kürzlich den Geist aufgegeben hat, bleibt mir nur noch ein Samsung Galaxy Tab S7FE, wenn ich nicht im Homeoffice bin. Daher ist vscode mit einem Web-Frontend (und es ist überraschend benutzerfreundlich), das mit meiner Workstation verbunden ist, immer noch mein Haupteditor (es funktioniert sogar mit der Neovim-Erweiterung).
Die von LLM unterstützte generative KI verändert unser Leben rasant, es macht keinen Sinn, sich ihr zu widersetzen. Meiner Meinung nach sollten wir jedoch auch etwas Selbstbeherrschung haben, um es nicht für alles zu verwenden. Es sollte wirklich als Ergänzung zu innovativer oder kreativer Arbeit verwendet werden, nicht als Ersatz für Innovation und Kreativität.
Wir sollten auch wissen, was es ausgibt, anstatt blind zu akzeptieren, was es tut. Zum Beispiel habe ich in Genruler dafür gesorgt, dass meine ursprüngliche README-Datei durch ausführlichere Beispiele verbessert wurde. Anstatt es so zu akzeptieren, wie es ist, habe ich es geschafft, Tests für alle Beispiele zu generieren, die es in der README-Datei generiert, sodass der Beispielcode funktioniert und funktioniert, wie ich es beabsichtigt hatte.
Im Großen und Ganzen denke ich, dass diese Editoren mit generativer KI das Geld wert sind, das sie verlangen. Letztlich handelt es sich hierbei um Hilfsmittel, sie sollen eine Arbeitshilfe bieten und nicht den Menschen ersetzen, der die Tastatur drückt.
Das obige ist der detaillierte Inhalt vonAufbau einer Zustandsmaschinenbibliothek mit Hilfe von KI-Tools. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AMPython eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AMSie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AM
Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AMPython wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PMSie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AMWie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AM
Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AMWie kann man nicht erkannt werden, wenn Sie Fiddlereverywhere für Man-in-the-Middle-Lesungen verwenden, wenn Sie FiddLereverywhere verwenden ...
 Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AM
Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AMLaden Sie Gurkendateien in Python 3.6 Umgebungsbericht Fehler: ModulenotFoundError: Nomodulennamen ...
 Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AM
Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AMWie löste ich das Problem der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse? Wenn wir malerische Spot -Kommentare und -analysen durchführen, verwenden wir häufig das Jieba -Word -Segmentierungstool, um den Text zu verarbeiten ...


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

