
 Backend-EntwicklungPython-TutorialLokaler Workflow: Orchestrierung der Datenaufnahme in Airtable
Backend-EntwicklungPython-TutorialLokaler Workflow: Orchestrierung der Datenaufnahme in Airtable
Einführung
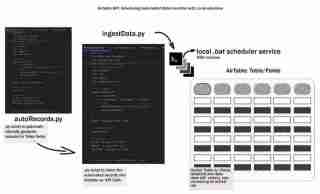
Der gesamte Datenlebenszyklus beginnt mit der Generierung von Daten und deren Speicherung auf irgendeine Art und Weise. Nennen wir dies den frühen Datenlebenszyklus und untersuchen, wie die Datenaufnahme in Airtable mithilfe eines lokalen Workflows automatisiert werden kann. Wir behandeln das Einrichten einer Entwicklungsumgebung, das Entwerfen des Aufnahmeprozesses, das Erstellen eines Batch-Skripts und das Planen des Arbeitsablaufs – damit die Dinge einfach, lokal/reproduzierbar und zugänglich bleiben.
Lassen Sie uns zunächst über Airtable sprechen. Airtable ist ein leistungsstarkes und flexibles Tool, das die Einfachheit einer Tabellenkalkulation mit der Struktur einer Datenbank verbindet. Ich finde es perfekt zum Organisieren von Informationen, zum Verwalten von Projekten und zum Verfolgen von Aufgaben, und es gibt eine kostenlose Stufe!
Vorbereitung der Umgebung
Einrichten der Entwicklungsumgebung
Wir würden dieses Projekt mit Python entwickeln, also nutzen Sie Ihre Lieblings-IDE und erstellen Sie eine virtuelle Umgebung
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
Um mit Airtable zu beginnen, besuchen Sie die Website von Airtable. Sobald Sie sich für ein kostenloses Konto angemeldet haben, müssen Sie einen neuen Arbeitsbereich erstellen. Stellen Sie sich einen Arbeitsbereich als einen Container für alle Ihre zugehörigen Tabellen und Daten vor.
Als nächstes erstellen Sie eine neue Tabelle in Ihrem Arbeitsbereich. Eine Tabelle ist im Wesentlichen eine Tabelle, in der Sie Ihre Daten speichern. Definieren Sie die Felder (Spalten) in Ihrer Tabelle so, dass sie der Struktur Ihrer Daten entsprechen.
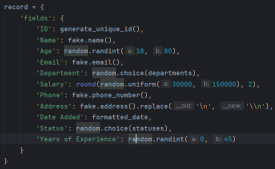
Hier ist ein Ausschnitt der im Tutorial verwendeten Felder, es ist eine Kombination aus Texten, Daten und Zahlen:
Um Ihr Skript mit Airtable zu verbinden, müssen Sie einen API-Schlüssel oder ein persönliches Zugriffstoken generieren. Dieser Schlüssel fungiert als Passwort und ermöglicht Ihrem Skript die Interaktion mit Ihren Airtable-Daten. Um einen Schlüssel zu generieren, navigieren Sie zu Ihren Airtable-Kontoeinstellungen, suchen Sie den API-Bereich und befolgen Sie die Anweisungen zum Erstellen eines neuen Schlüssels.
*Denken Sie daran, Ihren API-Schlüssel sicher aufzubewahren. Vermeiden Sie es, es öffentlich zu teilen oder an öffentliche Repositories zu übergeben. *
Installieren notwendiger Abhängigkeiten (Python, Bibliotheken usw.)
Als nächstes tippen Sie auf „requirements.txt“. Fügen Sie in dieser .txt-Datei die folgenden Pakete ein:
pyairtable schedule faker python-dotenv
Führen Sie jetzt pip install -r require.txt aus, um die erforderlichen Pakete zu installieren.
Organisation der Projektstruktur
In diesem Schritt erstellen wir die Skripte, in .env speichern wir unsere Anmeldeinformationen, autoRecords.py – um zufällig Daten für die definierten Felder und die ingestData.py, um die Datensätze in Airtable einzufügen.
Entwerfen des Aufnahmeprozesses: Umgebungsvariablen
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
Entwerfen des Aufnahmeprozesses: Automatisierte Aufzeichnungen
Hört sich gut an, lassen Sie uns einen fokussierten Unterthemeninhalt für Ihren Blogbeitrag zu diesem Mitarbeiterdatengenerator zusammenstellen.
Generierung realistischer Mitarbeiterdaten für Ihre Projekte
Bei der Arbeit an Projekten, die Mitarbeiterdaten beinhalten, ist es oft hilfreich, eine zuverlässige Möglichkeit zu haben, realistische Beispieldaten zu generieren. Ganz gleich, ob Sie ein HR-Managementsystem, ein Mitarbeiterverzeichnis oder irgendetwas dazwischen aufbauen, der Zugriff auf robuste Testdaten kann Ihre Entwicklung rationalisieren und Ihre Anwendung widerstandsfähiger machen.
In diesem Abschnitt untersuchen wir ein Python-Skript, das zufällige Mitarbeiterdatensätze mit einer Vielzahl relevanter Felder generiert. Dieses Tool kann von großem Nutzen sein, wenn Sie Ihre Anwendung schnell und einfach mit realistischen Daten füllen müssen.
Generieren eindeutiger IDs
Der erste Schritt in unserem Datengenerierungsprozess besteht darin, eindeutige Kennungen für jeden Mitarbeiterdatensatz zu erstellen. Dies ist eine wichtige Überlegung, da Ihre Bewerbung wahrscheinlich eine Möglichkeit benötigen wird, jeden einzelnen Mitarbeiter eindeutig zu referenzieren. Unser Skript enthält eine einfache Funktion zum Generieren dieser IDs:
pyairtable schedule faker python-dotenv
Diese Funktion generiert eine eindeutige ID im Format „N-#####“, wobei die Zahl ein zufälliger 5-stelliger Wert ist. Sie können dieses Format an Ihre spezifischen Bedürfnisse anpassen.
Generieren zufälliger Mitarbeiterdatensätze
Als nächstes schauen wir uns die Kernfunktion an, die die Mitarbeiterdatensätze selbst generiert. Die Funktion „generate_random_records()“ verwendet die Anzahl der zu erstellenden Datensätze als Eingabe und gibt eine Liste von Wörterbüchern zurück, wobei jedes Wörterbuch einen Mitarbeiter mit verschiedenen Feldern darstellt:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
Diese Funktion nutzt die Faker-Bibliothek, um realistisch aussehende Daten für verschiedene Mitarbeiterfelder wie Name, E-Mail, Telefonnummer und Adresse zu generieren. Es beinhaltet auch einige grundlegende Einschränkungen, wie z. B. die Begrenzung der Altersspanne und der Gehaltsspanne auf angemessene Werte.
Die Funktion gibt eine Liste von Wörterbüchern zurück, wobei jedes Wörterbuch einen Mitarbeiterdatensatz in einem Format darstellt, das mit Airtable kompatibel ist.
Vorbereiten von Daten für Airtable
Schließlich schauen wir uns die Funktion „prepare_records_for_airtable()“ an, die die Liste der Mitarbeiterdatensätze nimmt und den „Felder“-Teil jedes Datensatzes extrahiert. Dies ist das Format, das Airtable für den Datenimport erwartet:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
Diese Funktion vereinfacht die Datenstruktur und erleichtert so die Arbeit bei der Integration der generierten Daten mit Airtable oder anderen Systemen.
Alles zusammenfügen
Um dieses Datengenerierungstool zu verwenden, können wir die Funktion „generate_random_records()“ mit der gewünschten Anzahl von Datensätzen aufrufen und dann die resultierende Liste an die Funktion „prepare_records_for_airtable()“ übergeben:
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
Dadurch werden zwei zufällige Mitarbeiterdatensätze generiert, in ihrem Originalformat gedruckt und anschließend im flachen Format, das für Airtable geeignet ist.
Ausführen:
pyairtable schedule faker python-dotenv
Ausgabe:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
Generierte Daten mit Airtable integrieren
Neben der Generierung realistischer Mitarbeiterdaten bietet unser Skript auch Funktionen zur nahtlosen Integration dieser Daten in Airtable
Einrichten der Airtable-Verbindung
Bevor wir mit dem Einfügen unserer generierten Daten in Airtable beginnen können, müssen wir eine Verbindung zur Plattform herstellen. Unser Skript verwendet die pyairtable-Bibliothek, um mit der Airtable-API zu interagieren. Wir beginnen mit dem Laden der erforderlichen Umgebungsvariablen, einschließlich des Airtable-API-Schlüssels sowie der Basis-ID und des Tabellennamens, in dem wir die Daten speichern möchten:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
Mit diesen Anmeldeinformationen können wir dann den Airtable-API-Client initialisieren und einen Verweis auf die spezifische Tabelle erhalten, mit der wir arbeiten möchten:
def generate_random_records(num_records=10):
"""
Generate random records with reasonable constraints
:param num_records: Number of records to generate
:return: List of records formatted for Airtable
"""
records = []
# Constants
departments = ['Sales', 'Engineering', 'Marketing', 'HR', 'Finance', 'Operations']
statuses = ['Active', 'On Leave', 'Contract', 'Remote']
for _ in range(num_records):
# Generate date in the correct format
random_date = datetime.now() - timedelta(days=random.randint(0, 365))
formatted_date = random_date.strftime('%Y-%m-%dT%H:%M:%S.000Z')
record = {
'fields': {
'ID': generate_unique_id(),
'Name': fake.name(),
'Age': random.randint(18, 80),
'Email': fake.email(),
'Department': random.choice(departments),
'Salary': round(random.uniform(30000, 150000), 2),
'Phone': fake.phone_number(),
'Address': fake.address().replace('\n', '\n'), # Escape newlines
'Date Added': formatted_date,
'Status': random.choice(statuses),
'Years of Experience': random.randint(0, 45)
}
}
records.append(record)
return records
Einfügen der generierten Daten
Da wir nun die Verbindung eingerichtet haben, können wir die Funktion „generate_random_records()“ aus dem vorherigen Abschnitt verwenden, um einen Stapel von Mitarbeiterdatensätzen zu erstellen und diese dann in Airtable einzufügen:
def prepare_records_for_airtable(records):
"""Convert records from nested format to flat format for Airtable"""
return [record['fields'] for record in records]
Die Funktion „prep_for_insertion()“ ist für die Konvertierung des von „generate_random_records()“ zurückgegebenen verschachtelten Datensatzformats in das von der Airtable-API erwartete flache Format verantwortlich. Sobald die Daten vorbereitet sind, verwenden wir die Methode table.batch_create(), um die Datensätze in einem einzigen Massenvorgang einzufügen.
Fehlerbehandlung und Protokollierung
Um sicherzustellen, dass unser Integrationsprozess robust und einfach zu debuggen ist, haben wir auch einige grundlegende Fehlerbehandlungs- und Protokollierungsfunktionen integriert. Wenn während des Dateneinfügungsvorgangs Fehler auftreten, protokolliert das Skript die Fehlermeldung, um bei der Fehlerbehebung zu helfen:
if __name__ == "__main__":
records = generate_random_records(2)
print(records)
prepared_records = prepare_records_for_airtable(records)
print(prepared_records)
Durch die Kombination der leistungsstarken Datengenerierungsfunktionen unseres früheren Skripts mit den hier gezeigten Integrationsfunktionen können Sie Ihre Airtable-basierten Anwendungen schnell und zuverlässig mit realistischen Mitarbeiterdaten füllen.
Planen der automatisierten Datenaufnahme mit einem Batch-Skript
Um den Datenaufnahmeprozess vollständig zu automatisieren, können wir ein Batch-Skript (.bat-Datei) erstellen, das das Python-Skript regelmäßig ausführt. Dadurch können Sie die Datenerfassung so einrichten, dass sie automatisch und ohne manuellen Eingriff erfolgt.
Hier ist ein Beispiel für ein Batch-Skript, das zum Ausführen des ingestData.py-Skripts verwendet werden kann:
python autoRecords.py
Lassen Sie uns die wichtigsten Teile dieses Skripts aufschlüsseln:
- @echo off: Diese Zeile unterdrückt die Ausgabe jedes Befehls auf der Konsole, wodurch die Ausgabe sauberer wird.
- echo Starting Airtable Automated Data Ingestion Service...: Diese Zeile gibt eine Nachricht an die Konsole aus, die angibt, dass das Skript gestartet wurde.
- cd /d C:UsersbuascPycharmProjectsscrapEngineering: Diese Zeile ändert das aktuelle Arbeitsverzeichnis in das Projektverzeichnis, in dem sich das ingestData.py-Skript befindet.
- call C:UsersbuascPycharmProjectsscrapEngineeringvenv_airtableScriptsactivate.bat: Diese Zeile aktiviert die virtuelle Umgebung, in der die notwendigen Python-Abhängigkeiten installiert sind.
- python ingestData.py: Diese Zeile führt das Python-Skript ingestData.py aus.
- if %ERRORLEVEL% NEQ 0 (...): Dieser Block prüft, ob im Python-Skript ein Fehler aufgetreten ist (d. h. ob ERRORLEVEL nicht Null ist). Wenn ein Fehler aufgetreten ist, wird eine Fehlermeldung gedruckt und das Skript angehalten, sodass Sie das Problem untersuchen können.
Um die automatische Ausführung dieses Batch-Skripts zu planen, können Sie den Windows-Taskplaner verwenden. Hier ist eine kurze Übersicht über die Schritte:
- Öffnen Sie das Startmenü und suchen Sie nach „Aufgabenplaner“.
Oder
Windows R und

- Erstellen Sie im Taskplaner eine neue Aufgabe und geben Sie ihr einen aussagekräftigen Namen (z. B. „Airtable Data Ingestion“).
- Fügen Sie auf der Registerkarte „Aktionen“ eine neue Aktion hinzu und geben Sie den Pfad zu Ihrem Batch-Skript an (z. B. C:UsersbuascPycharmProjectsscrapEngineeringestData.bat).
- Konfigurieren Sie den Zeitplan für die Ausführung des Skripts, z. B. täglich, wöchentlich oder monatlich.
- Speichern Sie die Aufgabe und aktivieren Sie sie.

Jetzt führt der Windows-Taskplaner das Batch-Skript automatisch in den angegebenen Intervallen aus und stellt so sicher, dass Ihre Airtable-Daten regelmäßig ohne manuelles Eingreifen aktualisiert werden.
Abschluss
Dies kann ein unschätzbares Werkzeug für Test-, Entwicklungs- und sogar Demonstrationszwecke sein.
In diesem Leitfaden haben Sie gelernt, wie Sie die erforderliche Entwicklungsumgebung einrichten, einen Aufnahmeprozess entwerfen, ein Batch-Skript zur Automatisierung der Aufgabe erstellen und den Workflow für die unbeaufsichtigte Ausführung planen. Jetzt haben wir ein solides Verständnis dafür, wie wir die Leistungsfähigkeit der lokalen Automatisierung nutzen können, um unsere Datenerfassungsvorgänge zu rationalisieren und wertvolle Erkenntnisse aus einem Airtable -basierten Datenökosystem zu gewinnen.
Da Sie nun den automatisierten Datenerfassungsprozess eingerichtet haben, gibt es viele Möglichkeiten, wie Sie auf dieser Grundlage aufbauen und noch mehr Wert aus Ihren Airtable-Daten erschließen können. Ich ermutige Sie, mit dem Code zu experimentieren, neue Anwendungsfälle zu erkunden und Ihre Erfahrungen mit der Community zu teilen.
Hier sind einige Ideen für den Einstieg:
- Passen Sie die Datengenerierung an
- Nutzen Sie die aufgenommenen Daten [Markdown-basierte explorative Datenanalyse (EDA), erstellen Sie interaktive Dashboards oder Visualisierungen mit Tools wie Tableau, Power BI oder Plotly, experimentieren Sie mit Arbeitsabläufen für maschinelles Lernen (Prognose der Mitarbeiterfluktuation oder Identifizierung von Top-Performern)]
- Integration mit anderen Systemen [Cloud-Funktionen, Webhooks oder Data Warehouses]
Die Möglichkeiten sind endlos! Ich bin gespannt, wie Sie auf diesem automatisierten Datenerfassungsprozess aufbauen und neue Erkenntnisse und Werte aus Ihren Airtable-Daten erschließen. Zögern Sie nicht, zu experimentieren, zusammenzuarbeiten und Ihre Fortschritte zu teilen. Ich bin hier, um Sie auf Ihrem Weg zu unterstützen.
Den vollständigen Code finden Sie unter https://github.com/AkanimohOD19A/scheduling_airtable_insertion. Das vollständige Video-Tutorial ist in Vorbereitung.
Das obige ist der detaillierte Inhalt vonLokaler Workflow: Orchestrierung der Datenaufnahme in Airtable. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AMSie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AM
Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AMPython wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PMSie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AMWie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AM
Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?Apr 02, 2025 am 07:15 AMWie kann man nicht erkannt werden, wenn Sie Fiddlereverywhere für Man-in-the-Middle-Lesungen verwenden, wenn Sie FiddLereverywhere verwenden ...
 Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AM
Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?Apr 02, 2025 am 07:12 AMLaden Sie Gurkendateien in Python 3.6 Umgebungsbericht Fehler: ModulenotFoundError: Nomodulennamen ...
 Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AM
Wie verbessert man die Genauigkeit der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse?Apr 02, 2025 am 07:09 AMWie löste ich das Problem der Jiebeba -Wortsegmentierung in der malerischen Spot -Kommentaranalyse? Wenn wir malerische Spot -Kommentare und -analysen durchführen, verwenden wir häufig das Jieba -Word -Segmentierungstool, um den Text zu verarbeiten ...
 Wie benutze ich den regulären Ausdruck, um das erste geschlossene Tag zu entsprechen und anzuhalten?Apr 02, 2025 am 07:06 AM
Wie benutze ich den regulären Ausdruck, um das erste geschlossene Tag zu entsprechen und anzuhalten?Apr 02, 2025 am 07:06 AMWie benutze ich den regulären Ausdruck, um das erste geschlossene Tag zu entsprechen und anzuhalten? Im Umgang mit HTML oder anderen Markup -Sprachen sind häufig regelmäßige Ausdrücke erforderlich, um ...


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

