
Heim >Backend-Entwicklung >Python-Tutorial >ClassiSage: Terraform IaC Automatisiertes AWS SageMaker-basiertes HDFS-Protokollklassifizierungsmodell
ClassiSage: Terraform IaC Automatisiertes AWS SageMaker-basiertes HDFS-Protokollklassifizierungsmodell

- Barbara StreisandOriginal
- 2024-10-26 05:04:30623Durchsuche
ClassiSage
Ein maschinelles Lernmodell, das mit AWS SageMaker und seinem Python SDK zur Klassifizierung von HDFS-Protokollen mithilfe von Terraform zur Automatisierung der Infrastruktureinrichtung erstellt wurde.
Link: GitHub
Sprache: HCL (Terraform), Python
Inhalt
- Übersicht: Projektübersicht.
- Systemarchitektur: Systemarchitekturdiagramm
- ML-Modell: Modellübersicht.
- Erste Schritte: So führen Sie das Projekt aus.
- Konsolenbeobachtungen: Änderungen an Instanzen und Infrastruktur, die während der Ausführung des Projekts beobachtet werden können.
- Endung und Bereinigung: Es fallen keine zusätzlichen Kosten an.
- Automatisch erstellte Objekte: Dateien und Ordner, die während des Ausführungsprozesses erstellt wurden.
- Befolgen Sie zunächst die Verzeichnisstruktur für eine bessere Projekteinrichtung.
- Nehmen Sie zum besseren Verständnis wichtige Referenzen aus dem in GitHub hochgeladenen Projekt-Repository von ClassiSage.
Überblick
- Das Modell wird mit AWS SageMaker zur Klassifizierung von HDFS-Protokollen zusammen mit S3 zum Speichern von Datensätzen, Notebook-Dateien (mit Code für die SageMaker-Instanz) und Modellausgabe erstellt.
- Die Einrichtung der Infrastruktur wird mithilfe von Terraform automatisiert, einem von HashiCorp erstellten Tool zur Bereitstellung von Infrastructure-as-Code
- Der verwendete Datensatz ist HDFS_v1.
- Das Projekt implementiert SageMaker Python SDK mit dem Modell XGBoost Version 1.2
Systemarchitektur
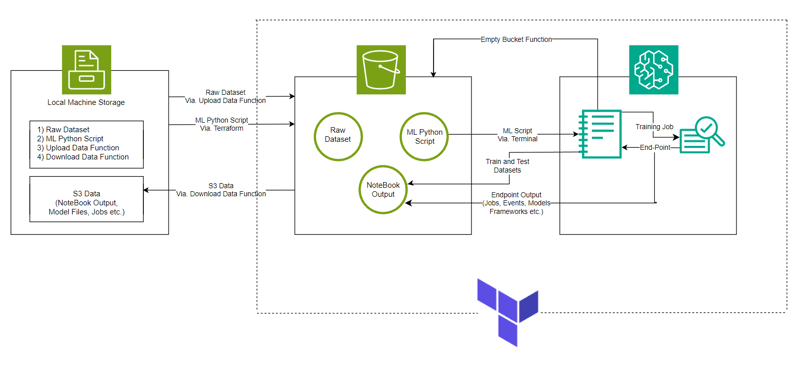
ML-Modell
- Bild-URI
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')

- Hyperparameter- und Estimator-Aufruf an den Container wird initialisiert
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).

- Ausbildungsjob
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- Bereitstellung
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')

- Validierung
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
Erste Schritte
- Klonen Sie das Repository mit Git Bash / laden Sie eine ZIP-Datei herunter / forken Sie das Repository.
- Gehen Sie zu Ihrer AWS-Managementkonsole, klicken Sie oben rechts auf Ihr Kontoprofil und wählen Sie im Dropdown-Menü „Meine Sicherheitsanmeldeinformationen“ aus.
- Zugriffsschlüssel erstellen: Klicken Sie im Abschnitt „Zugriffsschlüssel“ auf „Neuen Zugriffsschlüssel erstellen“. Ein Dialogfeld mit Ihrer Zugriffsschlüssel-ID und Ihrem geheimen Zugriffsschlüssel wird angezeigt.
- Schlüssel herunterladen oder kopieren: (WICHTIG) Laden Sie die CSV-Datei herunter oder kopieren Sie die Schlüssel an einen sicheren Ort. Dies ist das einzige Mal, dass Sie den geheimen Zugangsschlüssel sehen können.
- Öffnen Sie das geklonte Repo. in Ihrem VS-Code
- Erstellen Sie unter ClassiSage eine Datei als terraform.tfvars mit dem Inhalt als
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
- Laden Sie alle Abhängigkeiten für die Verwendung von Terraform und Python herunter und installieren Sie sie.
Geben Sie im Terminal terraform init ein bzw. fügen Sie es ein, um das Backend zu initialisieren.
Dann geben Sie „Terraform Plan“ ein bzw. fügen Sie ihn ein, um den Plan anzuzeigen, oder bestätigen Sie einfach „Terraform“, um sicherzustellen, dass kein Fehler vorliegt.
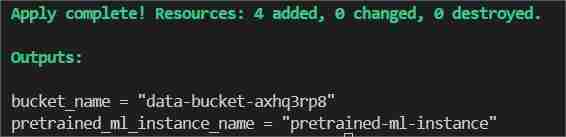
Schließlich im Terminal „Terraform apply --auto-approve“ eingeben/einfügen
Dadurch werden zwei Ausgaben angezeigt, eine als Bucket_Name und die andere als Pretrained_ML_Instance_Name (Die dritte Ressource ist der Variablenname, der dem Bucket gegeben wird, da es sich um globale Ressourcen handelt).
- Nachdem die Fertigstellung des Befehls im Terminal angezeigt wird, navigieren Sie zu ClassiSage/ml_ops/function.py und in die 11. Zeile der Datei mit dem Code
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
und ändern Sie es in den Pfad, in dem sich das Projektverzeichnis befindet, und speichern Sie es.
- Führen Sie dann auf ClassiSageml_opsdata_upload.ipynb alle Codezellen bis Zelle Nummer 25 mit dem Code aus
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')
zum Hochladen des Datensatzes in den S3-Bucket.
- Ausgabe der Codezellenausführung

- Nach der Ausführung des Notebooks öffnen Sie Ihre AWS-Managementkonsole erneut.
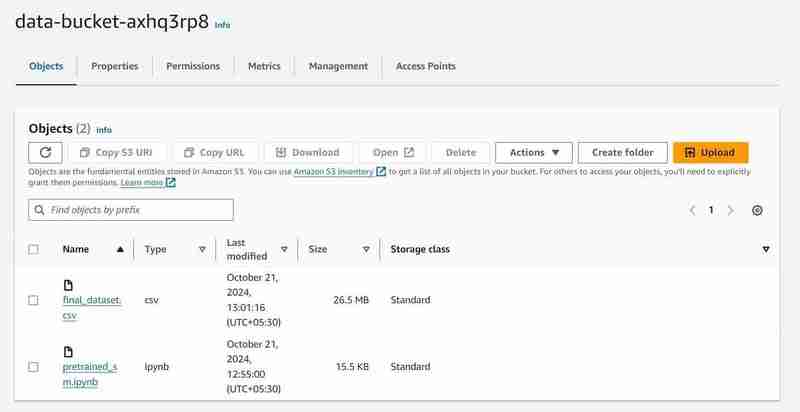
- Sie können nach S3- und Sagemaker-Diensten suchen und sehen eine Instanz jedes initiierten Dienstes (einen S3-Bucket und ein SageMaker-Notebook)
S3-Bucket mit dem Namen „data-bucket-“ mit 2 hochgeladenen Objekten, einem Datensatz und der Datei pretrained_sm.ipynb mit Modellcode.

- Gehen Sie zur Notebook-Instanz im AWS SageMaker, klicken Sie auf die erstellte Instanz und dann auf „Jupyter öffnen“.
- Klicken Sie anschließend oben rechts im Fenster auf „Neu“ und wählen Sie „Terminal“ aus.
- Dadurch wird ein neues Terminal erstellt.
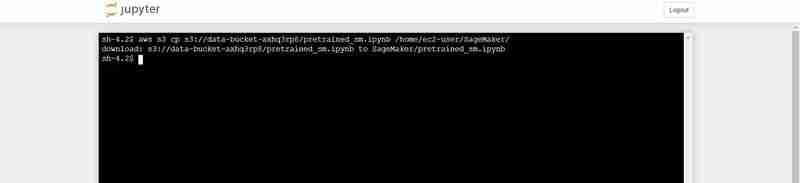
- Fügen Sie im Terminal Folgendes ein (ersetzen Sie es durch die Ausgabe „bucket_name“, die in der Terminalausgabe des VS-Codes angezeigt wird):
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
Terminalbefehl zum Hochladen von pretrained_sm.ipynb von S3 in die Jupyter-Umgebung von Notebook
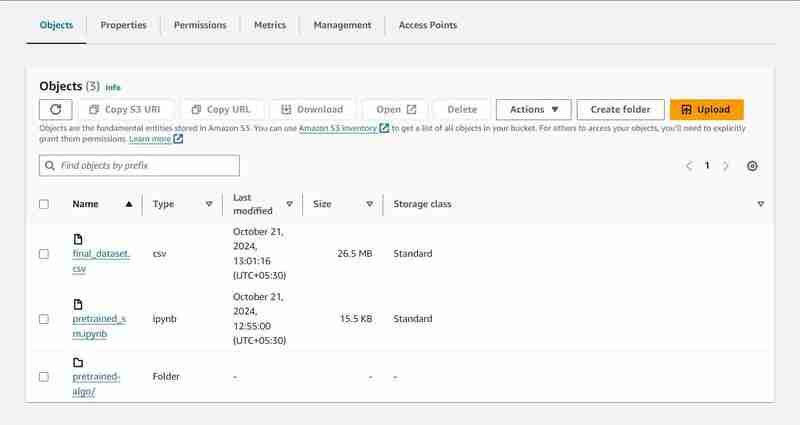
- Gehen Sie zurück zur geöffneten Jupyter-Instanz und klicken Sie auf die Datei pretrained_sm.ipynb, um sie zu öffnen und ihr einen conda_python3-Kernel zuzuweisen.
- Scrollen Sie nach unten zur 4. Zelle und ersetzen Sie den Wert der Variable „bucket_name“ durch die Terminalausgabe des VS-Codes für „bucket_name = „
““
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
Ausgabe der Codezellenausführung

- Führen Sie oben in der Datei einen Neustart durch, indem Sie zur Registerkarte „Kernel“ gehen.
- Führen Sie das Notebook bis zur Codezelle Nummer 27 mit dem Code aus
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
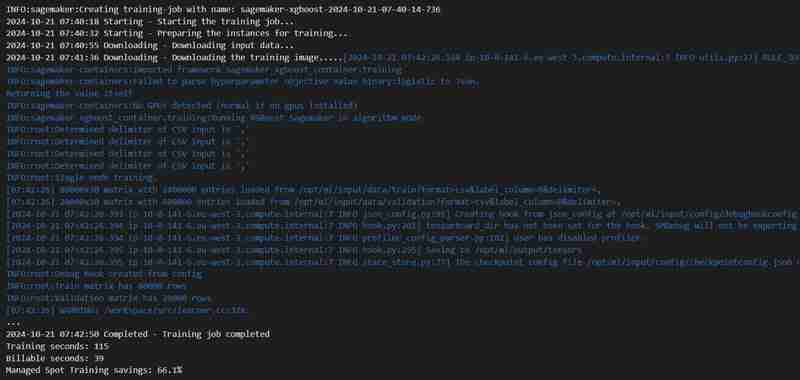
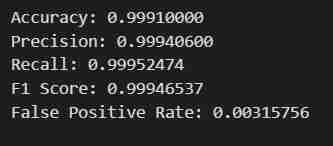
- Sie erhalten das gewünschte Ergebnis. Die Daten werden abgerufen, in Trainings- und Testsätze aufgeteilt, nachdem sie für Beschriftungen und Features mit einem definierten Ausgabepfad angepasst wurden. Anschließend wird ein Modell mit dem Python SDK von SageMaker trainiert, als Endpunkt bereitgestellt und validiert, um verschiedene Metriken zu liefern.
Anmerkungen zur Konsolenbeobachtung
Ausführung der 8. Zelle
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')
- Ein Ausgabepfad wird im S3 eingerichtet, um Modelldaten zu speichern.

Hinrichtung der 23. Zelle
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
- Ein Trainingsjob wird gestartet, Sie können ihn unter der Registerkarte „Training“ überprüfen.

- Nach einiger Zeit (schätzungsweise 3 Minuten) ist es abgeschlossen und wird dasselbe anzeigen.

Ausführung der 24. Codezelle
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
- Ein Endpunkt wird auf der Registerkarte „Inferenz“ bereitgestellt.
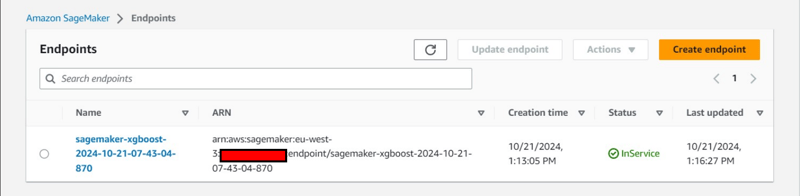
Zusätzliche Konsolenbeobachtung:
- Erstellung einer Endpunktkonfiguration auf der Registerkarte „Inferenz“.

- Erstellung eines Modells auch unter der Registerkarte „Inferenz“.
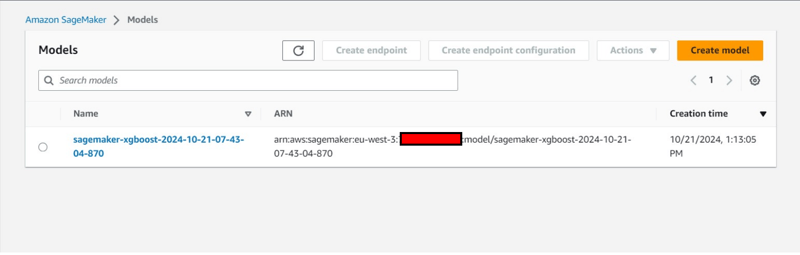
Ende und Aufräumen
- Im VS-Code kehren Sie zu data_upload.ipynb zurück, um die letzten beiden Codezellen auszuführen und die Daten des S3-Buckets in das lokale System herunterzuladen.
- Der Ordner erhält den Namen „downloaded_bucket_content“. Verzeichnisstruktur des heruntergeladenen Ordners.
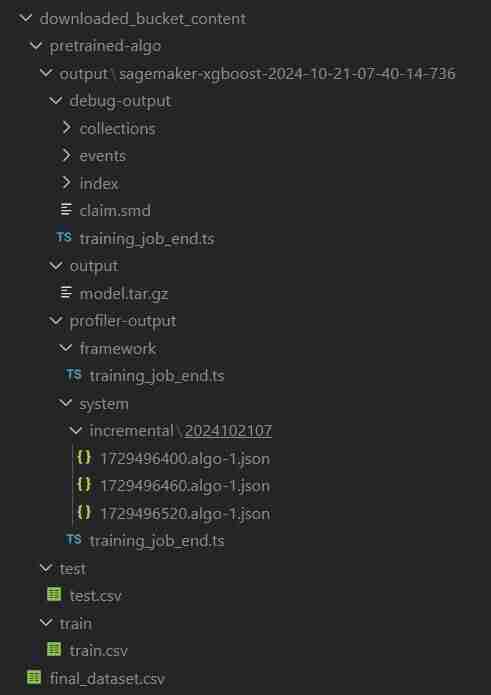
- In der Ausgabezelle erhalten Sie ein Protokoll der heruntergeladenen Dateien. Es enthält ein rohes pretrained_sm.ipynb, final_dataset.csv und einen Modellausgabeordner namens „pretrained-algo“ mit den Ausführungsdaten der Sagemaker-Codedatei.
- Gehen Sie abschließend in pretrained_sm.ipynb, das in der SageMaker-Instanz vorhanden ist, und führen Sie die letzten beiden Codezellen aus. Der Endpunkt und die Ressourcen im S3-Bucket werden gelöscht, um sicherzustellen, dass keine zusätzlichen Kosten anfallen.
- Löschen des Endpunkts
estimator.fit({'train': s3_input_train,'validation': s3_input_test})

- Löschen von S3: (Erforderlich, um die Instanz zu zerstören)
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')
- Kehren Sie zum VS Code-Terminal für die Projektdatei zurück und geben Sie dann terraform destroy --auto-approve ein und fügen Sie es ein
- Alle erstellten Ressourceninstanzen werden gelöscht.
Automatisch erstellte Objekte
ClassiSage/downloaded_bucket_content
ClassiSage/.terraform
ClassiSage/ml_ops/pycache
ClassiSage/.terraform.lock.hcl
ClassiSage/terraform.tfstate
ClassiSage/terraform.tfstate.backup
HINWEIS:
Wenn Ihnen die Idee und die Implementierung dieses maschinellen Lernprojekts unter Verwendung von AWS Cloud S3 und SageMaker für die HDFS-Protokollklassifizierung unter Verwendung von Terraform für IaC (Infrastruktur-Setup-Automatisierung) gefallen haben, denken Sie bitte darüber nach, diesen Beitrag zu liken und zu markieren, nachdem Sie sich das Projekt-Repository auf GitHub angesehen haben .
Das obige ist der detaillierte Inhalt vonClassiSage: Terraform IaC Automatisiertes AWS SageMaker-basiertes HDFS-Protokollklassifizierungsmodell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!