
 Backend-EntwicklungPython-TutorialJanus B: Ein einheitliches Modell für multimodale Verständnis- und Generierungsaufgaben
Backend-EntwicklungPython-TutorialJanus B: Ein einheitliches Modell für multimodale Verständnis- und GenerierungsaufgabenJanus B: Ein einheitliches Modell für multimodale Verständnis- und Generierungsaufgaben

Janus 1.3B
Janus ist ein neues autoregressives Framework, das multimodales Verständnis und Generierung integriert. Im Gegensatz zu früheren Modellen, die einen einzigen visuellen Encoder sowohl für Verständnis- als auch für Generierungsaufgaben verwendeten, führt Janus zwei separate visuelle Codierungspfade für diese Funktionen ein.
Unterschiede in der Kodierung für Verständnis und Generierung
- Bei multimodalen Verständnisaufgaben extrahiert der visuelle Encoder semantische Informationen auf hoher Ebene wie Objektkategorien und visuelle Attribute. Dieser Encoder konzentriert sich auf die Ableitung komplexer Bedeutungen und betont höherdimensionale semantische Elemente.
- Andererseits liegt bei visuellen Generierungsaufgaben der Schwerpunkt auf der Generierung feiner Details und der Aufrechterhaltung der Gesamtkonsistenz. Daher ist eine niedrigerdimensionale Kodierung erforderlich, die räumliche Strukturen und Texturen erfassen kann.
Einrichten der Umgebung
Hier sind die Schritte zum Ausführen von Janus in Google Colab:
git clone https://github.com/deepseek-ai/Janus cd Janus pip install -e . # If needed, install the following as well # pip install wheel # pip install flash-attn --no-build-isolation
Sehaufgaben
Laden des Modells
Verwenden Sie den folgenden Code, um das erforderliche Modell für Vision-Aufgaben zu laden:
import torch from transformers import AutoModelForCausalLM from janus.models import MultiModalityCausalLM, VLChatProcessor from janus.utils.io import load_pil_images # Specify the model path model_path = "deepseek-ai/Janus-1.3B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True) vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
Laden und Vorbereiten von Bildern für die Kodierung
Als nächstes laden Sie das Bild und konvertieren es in ein Format, das das Modell verstehen kann:
conversation = [
{
"role": "User",
"content": "<image_placeholder>\nDescribe this chart.",
"images": ["images/pie_chart.png"],
},
{"role": "Assistant", "content": ""},
]
# Load the image and prepare input
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
# Run the image encoder and obtain image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
</image_placeholder>
Generieren einer Antwort
Führen Sie abschließend das Modell aus, um eine Antwort zu generieren:
# Run the model and generate a response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
Beispielausgabe
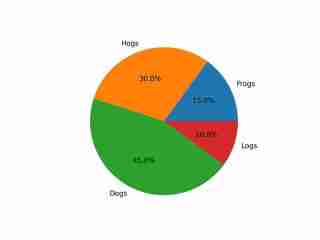
The image depicts a pie chart that illustrates the distribution of four different categories among four distinct groups. The chart is divided into four segments, each representing a category with a specific percentage. The categories and their corresponding percentages are as follows: 1. **Hogs**: This segment is colored in orange and represents 30.0% of the total. 2. **Frog**: This segment is colored in blue and represents 15.0% of the total. 3. **Logs**: This segment is colored in red and represents 10.0% of the total. 4. **Dogs**: This segment is colored in green and represents 45.0% of the total. The pie chart is visually divided into four segments, each with a different color and corresponding percentage. The segments are arranged in a clockwise manner starting from the top-left, moving clockwise. The percentages are clearly labeled next to each segment. The chart is a simple visual representation of data, where the size of each segment corresponds to the percentage of the total category it represents. This type of chart is commonly used to compare the proportions of different categories in a dataset. To summarize, the pie chart shows the following: - Hogs: 30.0% - Frog: 15.0% - Logs: 10.0% - Dogs: 45.0% This chart can be used to understand the relative proportions of each category in the given dataset.
Die Ausgabe zeigt ein angemessenes Verständnis des Bildes, einschließlich seiner Farben und seines Textes.
Aufgaben zur Bildgenerierung
Laden des Modells
Laden Sie das erforderliche Modell für Bildgenerierungsaufgaben mit dem folgenden Code:
import os import PIL.Image import torch import numpy as np from transformers import AutoModelForCausalLM from janus.models import MultiModalityCausalLM, VLChatProcessor # Specify the model path model_path = "deepseek-ai/Janus-1.3B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True) vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
Vorbereiten der Eingabeaufforderung
Als nächstes bereiten Sie die Eingabeaufforderung basierend auf der Anfrage des Benutzers vor:
# Set up the prompt
conversation = [
{
"role": "User",
"content": "cute japanese girl, wearing a bikini, in a beach",
},
{"role": "Assistant", "content": ""},
]
# Convert the prompt into the appropriate format
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
Das Bild erzeugen
Die folgende Funktion wird zum Generieren von Bildern verwendet. Standardmäßig werden 16 Bilder generiert:
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 16,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(
inputs_embeds=inputs_embeds,
use_cache=True,
past_key_values=outputs.past_key_values if i != 0 else None,
)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(
generated_tokens.to(dtype=torch.int),
shape=[parallel_size, 8, img_size // patch_size, img_size // patch_size],
)
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', f"img_{i}.jpg")
PIL.Image.fromarray(visual_img[i]).save(save_path)
# Run the image generation
generate(vl_gpt, vl_chat_processor, prompt)
Die generierten Bilder werden im Ordner „generated_samples“ gespeichert.
Beispiel generierter Ergebnisse
Unten finden Sie ein Beispiel für ein generiertes Bild:

- Hundesind relativ gut dargestellt.
- Gebäude behalten ihre Gesamtform bei, obwohl einige Details, wie z. B. Fenster, unrealistisch erscheinen können.
- Es ist jedoch schwierig, Menschen gut zu generieren, da sowohl im fotorealistischen als auch im animeähnlichen Stil erhebliche Verzerrungen auftreten.
Das obige ist der detaillierte Inhalt vonJanus B: Ein einheitliches Modell für multimodale Verständnis- und Generierungsaufgaben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Der Hauptzweck von Python: Flexibilität und BenutzerfreundlichkeitApr 17, 2025 am 12:14 AM
Der Hauptzweck von Python: Flexibilität und BenutzerfreundlichkeitApr 17, 2025 am 12:14 AMDie Flexibilität von Python spiegelt sich in Multi-Paradigm-Unterstützung und dynamischen Typsystemen wider, während eine einfache Syntax und eine reichhaltige Standardbibliothek stammt. 1. Flexibilität: Unterstützt objektorientierte, funktionale und prozedurale Programmierung und dynamische Typsysteme verbessern die Entwicklungseffizienz. 2. Benutzerfreundlichkeit: Die Grammatik liegt nahe an der natürlichen Sprache, die Standardbibliothek deckt eine breite Palette von Funktionen ab und vereinfacht den Entwicklungsprozess.
 Python: Die Kraft der vielseitigen ProgrammierungApr 17, 2025 am 12:09 AM
Python: Die Kraft der vielseitigen ProgrammierungApr 17, 2025 am 12:09 AMPython ist für seine Einfachheit und Kraft sehr beliebt, geeignet für alle Anforderungen von Anfängern bis hin zu fortgeschrittenen Entwicklern. Seine Vielseitigkeit spiegelt sich in: 1) leicht zu erlernen und benutzten, einfachen Syntax; 2) Reiche Bibliotheken und Frameworks wie Numpy, Pandas usw.; 3) plattformübergreifende Unterstützung, die auf einer Vielzahl von Betriebssystemen betrieben werden kann; 4) Geeignet für Skript- und Automatisierungsaufgaben zur Verbesserung der Arbeitseffizienz.
 Python in 2 Stunden am Tag lernen: Ein praktischer LeitfadenApr 17, 2025 am 12:05 AM
Python in 2 Stunden am Tag lernen: Ein praktischer LeitfadenApr 17, 2025 am 12:05 AMJa, lernen Sie Python in zwei Stunden am Tag. 1. Entwickeln Sie einen angemessenen Studienplan, 2. Wählen Sie die richtigen Lernressourcen aus, 3. Konsolidieren Sie das durch die Praxis erlernte Wissen. Diese Schritte können Ihnen helfen, Python in kurzer Zeit zu meistern.
 Python gegen C: Vor- und Nachteile für EntwicklerApr 17, 2025 am 12:04 AM
Python gegen C: Vor- und Nachteile für EntwicklerApr 17, 2025 am 12:04 AMPython eignet sich für eine schnelle Entwicklung und Datenverarbeitung, während C für hohe Leistung und zugrunde liegende Kontrolle geeignet ist. 1) Python ist einfach zu bedienen, mit prägnanter Syntax, und eignet sich für Datenwissenschaft und Webentwicklung. 2) C hat eine hohe Leistung und eine genaue Kontrolle und wird häufig bei der Programmierung von Spielen und Systemen verwendet.
 Python: zeitliches Engagement und LerntempoApr 17, 2025 am 12:03 AM
Python: zeitliches Engagement und LerntempoApr 17, 2025 am 12:03 AMDie Zeit, die zum Erlernen von Python erforderlich ist, variiert von Person zu Person, hauptsächlich von früheren Programmiererfahrungen, Lernmotivation, Lernressourcen und -methoden und Lernrhythmus. Setzen Sie realistische Lernziele und lernen Sie durch praktische Projekte am besten.
 Python: Automatisierung, Skript- und AufgabenverwaltungApr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und AufgabenverwaltungApr 16, 2025 am 12:14 AMPython zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python und Zeit: Machen Sie das Beste aus Ihrer StudienzeitApr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer StudienzeitApr 14, 2025 am 12:02 AMUm die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AMPython zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

