
Heim >Java >javaLernprogramm >Etwas könnte die Entwicklungseffizienz von Java-Programmierern verdoppeln
Etwas könnte die Entwicklungseffizienz von Java-Programmierern verdoppeln

- 王林Original
- 2024-09-06 16:31:291030Durchsuche
Rechendilemma in der Anwendung
Entwicklung und Framework, welche sollten die höhere Priorität erhalten?
Java ist die am häufigsten verwendete Programmiersprache in der Anwendungsentwicklung. Aber Code zum Verarbeiten von Daten in Java zu schreiben ist nicht einfach. Unten finden Sie beispielsweise den Java-Code zum Durchführen der Gruppierung und Aggregation für zwei Felder:
Map<Integer, Map<String, Double>> summary = new HashMap<>();
for (Order order : orders) {
int year = order.orderDate.getYear();
String sellerId = order.sellerId;
double amount = order.amount;
Map<String, Double> salesMap = summary.get(year);
if (salesMap == null) {
salesMap = new HashMap<>();
summary.put(year, salesMap);
}
Double totalAmount = salesMap.get(sellerId);
if (totalAmount == null) {
totalAmount = 0.0;
}
salesMap.put(sellerId, totalAmount + amount);
}
for (Map.Entry<Integer, Map<String, Double>> entry : summary.entrySet()) {
int year = entry.getKey();
Map<String, Double> salesMap = entry.getValue();
System.out.println("Year: " + year);
for (Map.Entry<String, Double> salesEntry : salesMap.entrySet()) {
String sellerId = salesEntry.getKey();
double totalAmount = salesEntry.getValue();
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
}
}
Im Gegensatz dazu ist das SQL-Gegenstück viel einfacher. Eine GROUP BY-Klausel reicht aus, um die Berechnung abzuschließen.
SELECT Jahr (Bestelldatum), Verkäufer-ID, Summe (Betrag) AUS Bestellungen GRUPPE NACH Jahr (Bestelldatum), Verkäufer-ID
Tatsächlich arbeiteten frühe Anwendungen mit der Zusammenarbeit von Java und SQL. Der Geschäftsprozess wurde auf der Anwendungsseite in Java implementiert und die Daten wurden in SQL in der Backend-Datenbank verarbeitet. Aufgrund von Datenbankbeschränkungen war es schwierig, das Framework zu erweitern und zu migrieren. Dies war für die zeitgenössischen Anwendungen sehr unfreundlich. Darüber hinaus war SQL in vielen Fällen nicht verfügbar, wenn keine Datenbanken vorhanden waren oder datenbankübergreifende Berechnungen beteiligt waren.
Vor diesem Hintergrund begannen später viele Anwendungen, ein vollständig Java-basiertes Framework zu übernehmen, bei dem Datenbanken nur einfache Lese- und Schreibvorgänge ausführen und Geschäftsprozesse und Datenverarbeitung auf der Anwendungsseite in Java implementiert werden, insbesondere als Microservices aufkamen. Auf diese Weise wird die Anwendung von Datenbanken entkoppelt und erhält eine gute Skalierbarkeit und Migrationsfähigkeit, was dazu beiträgt, Framework-Vorteile zu erzielen, während gleichzeitig die zuvor erwähnte Java-Entwicklungskomplexität bewältigt werden muss.
Es scheint, dass wir uns nur auf einen Aspekt konzentrieren können – Entwicklung oder Framework. Um die Vorteile des Java-Frameworks nutzen zu können, muss man Entwicklungsschwierigkeiten ertragen; und um SQL zu verwenden, muss man Unzulänglichkeiten des Frameworks tolerieren. Dadurch entsteht ein Dilemma.
Was können wir dann tun?
Wie wäre es mit der Verbesserung der Datenverarbeitungsfunktionen von Java? Dadurch werden nicht nur SQL-Probleme vermieden, sondern auch Java-Mängel überwunden.
Eigentlich versuchen Java Stream/Kotlin/Scala alle, dies zu tun.
Streamen
Der in Java 8 eingeführte Stream fügte viele Datenverarbeitungsmethoden hinzu. Hier ist der Stream-Code zur Implementierung der obigen Berechnung:
Map<Integer, Map<String, Double>> summary = orders.stream()
.collect(Collectors.groupingBy(
order -> order.orderDate.getYear(),
Collectors.groupingBy(
order -> order.sellerId,
Collectors.summingDouble(order -> order.amount)
)
));
summary.forEach((year, salesMap) -> {
System.out.println("Year: " + year);
salesMap.forEach((sellerId, totalAmount) -> {
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
});
});
Stream vereinfacht den Code tatsächlich in gewissem Maße. Aber insgesamt ist es immer noch umständlich und weitaus weniger prägnant als SQL.
Kotlin
Kotlin, das behauptete, leistungsfähiger zu sein, verbesserte sich weiter:
val summary = orders
.groupBy { it.orderDate.year }
.mapValues { yearGroup ->
yearGroup.value
.groupBy { it.sellerId }
.mapValues { sellerGroup ->
sellerGroup.value.sumOf { it.amount }
}
}
summary.forEach { (year, salesMap) ->
println("Year: $year")
salesMap.forEach { (sellerId, totalAmount) ->
println(" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Der Kotlin-Code ist einfacher, aber die Verbesserung ist begrenzt. Im Vergleich zu SQL besteht immer noch eine große Lücke.
Scala
Dann war da noch Scala:
val summary = orders
.groupBy(order => order.orderDate.getYear)
.mapValues(yearGroup =>
yearGroup
.groupBy(_.sellerId)
.mapValues(sellerGroup => sellerGroup.map(_.amount).sum)
)
summary.foreach { case (year, salesMap) =>
println(s"Year: $year")
salesMap.foreach { case (sellerId, totalAmount) =>
println(s" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Scala ist etwas einfacher als Kotlin, aber dennoch nicht mit SQL zu vergleichen. Darüber hinaus ist Scala zu schwer und unpraktisch in der Anwendung.
Tatsächlich sind diese Technologien auf dem richtigen Weg, wenn auch nicht perfekt.
Kompilierte Sprachen sind nicht Hot-Swap-fähig
Darüber hinaus fehlt Java als kompilierte Sprache die Unterstützung für Hot-Swapping. Das Ändern von Code erfordert eine Neukompilierung und erneute Bereitstellung, was häufig einen Neustart des Dienstes erfordert. Dies führt zu einem suboptimalen Erlebnis bei häufigen Änderungen der Anforderungen. Im Gegensatz dazu hat SQL diesbezüglich kein Problem.

Die Java-Entwicklung ist kompliziert und das Framework weist auch Mängel auf. SQL hat Schwierigkeiten, die Anforderungen an das Framework zu erfüllen. Das Dilemma ist schwer zu lösen. Gibt es eine andere Möglichkeit?
Die ultimative Lösung – esProc SPL
esProc SPL ist eine rein in Java entwickelte Datenverarbeitungssprache. Es verfügt über eine einfache Entwicklung und ein flexibles Framework.
Präzise Syntax
Sehen wir uns die Java-Implementierungen für die obige Gruppierungs- und Aggregationsoperation an:

Im Vergleich zum Java-Code ist der SPL-Code viel prägnanter:
Orders.groups(year(orderdate),sellerid;sum(amount))
Es ist so einfach wie die SQL-Implementierung:
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
Tatsächlich ist SPL-Code oft einfacher als sein SQL-Gegenstück. Durch die Unterstützung auftragsbasierter und prozeduraler Berechnungen ist SPL besser in der Lage, komplexe Berechnungen durchzuführen. Betrachten Sie dieses Beispiel: Berechnen Sie die maximale Anzahl aufeinanderfolgender steigender Tage einer Aktie. SQL benötigt die folgende dreischichtige verschachtelte Anweisung, die schwer zu verstehen ist, ganz zu schweigen vom Schreiben.
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
SPL implementiert die Berechnung mit nur einer Codezeile. Dies ist sogar viel einfacher als SQL-Code, ganz zu schweigen vom Java-Code.
stock.sort(tradeDate).group@i(price<price[-1]).max(~.len())
Comprehensive, independent computing capability
SPL has table sequence – the specialized structured data object, and offers a rich computing class library based on table sequences to handle a variety of computations, including the commonly seen filtering, grouping, sorting, distinct and join, as shown below:
Orders.sort(Amount) // Sorting Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // Filtering Orders.groups(Client; sum(Amount)) // Grouping Orders.id(Client) // Distinct join(Orders:o,SellerId ; Employees:e,EId) // Join ……
More importantly, the SPL computing capability is independent of databases; it can function even without a database, which is unlike the ORM technology that requires translation into SQL for execution.
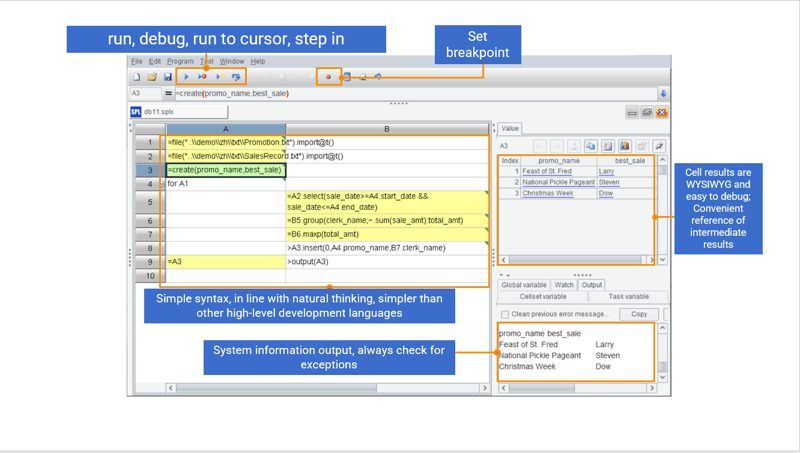
Efficient and easy to use IDE
Besides concise syntax, SPL also has a comprehensive development environment offering debugging functionalities, such as “Step over” and “Set breakpoint”, and very debugging-friendly WYSIWYG result viewing panel that lets users check result for each step in real time.
Support for large-scale data computing
SPL supports processing large-scale data that can or cannot fit into the memory.
In-memory computation:

External memory computation:

We can see that the SPL code of implementing an external memory computation and that of implementing an in-memory computation is basically the same, without extra computational load.
It is easy to implement parallelism in SPL. We just need to add @m option to the serial computing code. This is far simpler than the corresponding Java method.

Seamless integration into Java applications
SPL is developed in Java, so it can work by embedding its JARs in the Java application. And the application executes or invokes the SPL script via the standard JDBC. This makes SPL very lightweight, and it can even run on Android.
Call SPL code through JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call SplScript(?)");
st.setObject(1, "A");
st.execute();
ResultSet rs = st.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
As it is lightweight and integration-friendly, SPL can be seamlessly integrated into mainstream Java frameworks, especially suitable for serving as a computing engine within microservice architectures.
Highly open framework
SPL’s great openness enables it to directly connect to various types of data sources and perform real-time mixed computations, making it easy to handle computing scenarios where databases are unavailable or multiple/diverse databases are involved.

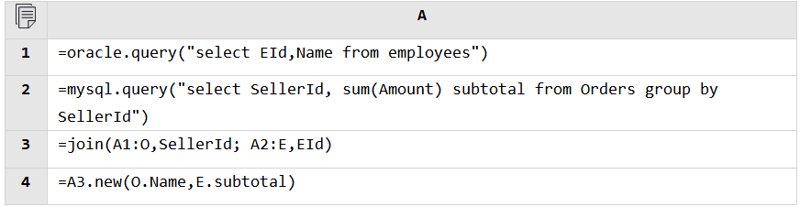
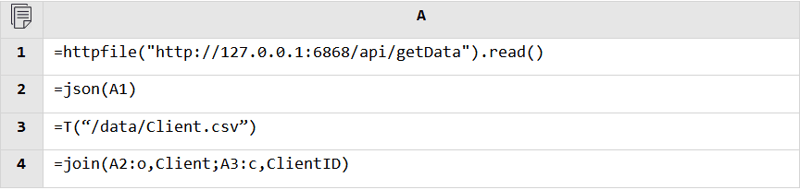
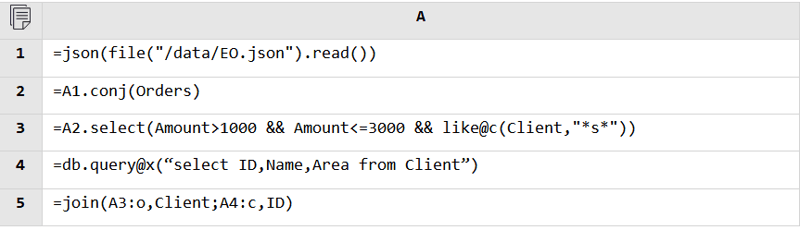
Regardless of the data source, SPL can read data from it and perform the mixed computation as long as it is accessible. Database and database, RESTful and file, JSON and database, anything is fine.
Databases:
RESTful and file:
JSON and database:
Interpreted execution and hot-swapping
SPL is an interpreted language that inherently supports hot swapping while power remains switched on. Modified code takes effect in real-time without requiring service restarts. This makes SPL well adapt to dynamic data processing requirements.

This hot—swapping capability enables independent computing modules with separate management, maintenance and operation, creating more flexible and convenient uses.
SPL can significantly increase Java programmers’ development efficiency while achieving framework advantages. It combines merits of both Java and SQL, and further simplifies code and elevates performance.
SPL open source address
Das obige ist der detaillierte Inhalt vonEtwas könnte die Entwicklungseffizienz von Java-Programmierern verdoppeln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!