
Heim >häufiges Problem >MLOps: So erstellen Sie ein Toolkit zur Steigerung der KI-Projektleistung
MLOps: So erstellen Sie ein Toolkit zur Steigerung der KI-Projektleistung

- 百草Original
- 2024-09-04 13:35:57705Durchsuche
Zahlreiche vielversprechend gestartete KI-Projekte scheitern. Dies liegt normalerweise nicht an der Qualität der Modelle für maschinelles Lernen (ML). Schlechte Implementierung und Systemintegration machen 90 % der Projekte zum Scheitern. Organisationen können ihre KI-Bemühungen retten. Sie sollten angemessene MLOps-Praktiken anwenden und die richtigen Tools auswählen. In diesem Artikel werden MLOps-Praktiken und -Tools besprochen, die sinkende KI-Projekte retten und robuste Projekte vorantreiben können, wodurch sich die Projektstartgeschwindigkeit potenziell verdoppeln lässt.

Zahlreiche KI-Projekte, die mit Versprechen gestartet wurden, scheitern Segel setzen. Dies liegt normalerweise nicht an der Qualität der Modelle für maschinelles Lernen (ML). Eine schlechte Implementierung und Systemintegration führt zu 90 % aller Projekte. Organisationen können ihre KI-Bemühungen retten. Sie sollten angemessene MLOps-Praktiken anwenden und die richtigen Tools auswählen. In diesem Artikel werden MLOps-Praktiken und -Tools besprochen, die sinkende KI-Projekte retten und robuste Projekte vorantreiben können, wodurch sich die Projektstartgeschwindigkeit potenziell verdoppeln lässt.
MLOps auf den Punkt gebracht
MLOps ist eine Mischung aus Anwendungsentwicklung für maschinelles Lernen ( Dev) und operative Aktivitäten (Ops). Dabei handelt es sich um eine Reihe von Vorgehensweisen, die dabei helfen, die Bereitstellung von ML-Modellen zu automatisieren und zu optimieren. Dadurch wird der gesamte ML-Lebenszyklus standardisiert.
MLOps ist komplex. Es erfordert Harmonie zwischen Datenmanagement, Modellentwicklung und Betrieb. Möglicherweise sind auch technologische und kulturelle Veränderungen innerhalb einer Organisation erforderlich. Bei reibungsloser Einführung ermöglicht MLOps Fachleuten, mühsame Aufgaben wie die Datenkennzeichnung zu automatisieren und Bereitstellungsprozesse transparent zu machen. Es trägt dazu bei, dass Projektdaten sicher sind und den Datenschutzgesetzen entsprechen.
Organisationen verbessern und skalieren ihre ML-Systeme durch MLOps-Praktiken. Dies macht die Zusammenarbeit zwischen Datenwissenschaftlern und Ingenieuren effektiver und fördert Innovationen.
KI-Projekte aus Herausforderungen verweben
MLOps-Experten verwandeln rohe geschäftliche Herausforderungen in optimierte, messbare Ziele des maschinellen Lernens. Sie entwerfen und verwalten ML-Pipelines und sorgen für gründliche Tests und Verantwortlichkeit während des gesamten Lebenszyklus eines KI-Projekts.
In der Anfangsphase eines KI-Projekts namens „Use Case Discovery“ arbeiten Datenwissenschaftler mit Unternehmen zusammen, um das Problem zu definieren. Sie übersetzen es in eine ML-Problembeschreibung und legen klare Ziele und KPIs fest.
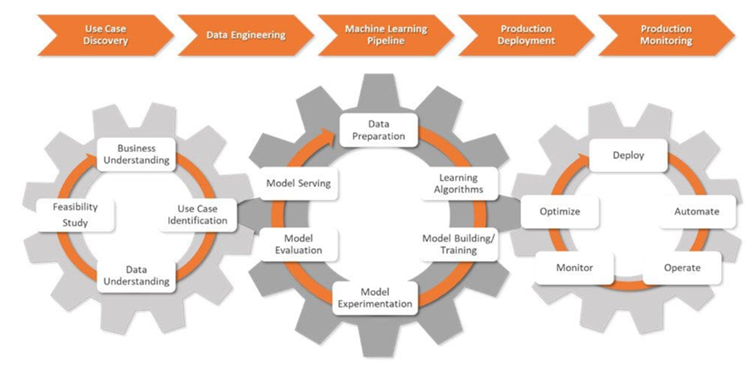
Als nächstes arbeiten Datenwissenschaftler mit Dateningenieuren zusammen. Sie sammeln Daten aus verschiedenen Quellen und bereinigen, verarbeiten und validieren diese Daten.
Wenn die Daten für die Modellierung bereit sind, entwerfen und implementieren Datenwissenschaftler robuste ML-Pipelines, die in CI/CD-Prozesse integriert sind. Diese Pipelines unterstützen Tests und Experimente und helfen dabei, Daten, Modellherkunft und zugehörige KPIs über alle Experimente hinweg zu verfolgen.
In der Produktionsbereitstellungsphase werden ML-Modelle in der gewählten Umgebung bereitgestellt: Cloud, lokal oder hybrid .
Datenwissenschaftler überwachen die Modelle und die Infrastruktur und verwenden wichtige Kennzahlen, um Änderungen in den Daten oder der Modellleistung zu erkennen. Wenn sie Änderungen erkennen, aktualisieren sie die Algorithmen, Daten und Hyperparameter und erstellen so neue Versionen der ML-Pipelines. Sie verwalten auch Speicher- und Rechenressourcen, um die Skalierbarkeit und den reibungslosen Betrieb der Modelle sicherzustellen.
MLOps-Tools treffen auf KI-Projekte
Stellen Sie sich einen Datenwissenschaftler vor, der eine KI-Anwendung entwickelt, um den Produktdesignprozess eines Kunden zu verbessern. Diese Lösung wird die Prototyping-Phase beschleunigen, indem sie KI-generierte Designalternativen basierend auf festgelegten Parametern bereitstellt.
Datenwissenschaftler bewältigen vielfältige Aufgaben, vom Entwurf des Frameworks bis zur Überwachung des KI-Modells in Echtzeit. Sie benötigen die richtigen Werkzeuge und ein Verständnis dafür, wie man sie bei jedem Schritt verwendet.
Bessere LLM-Leistung, intelligentere KI-Apps
Das Herzstück einer genauen und anpassungsfähigen KI-Lösung sind Vektordatenbanken und diese wichtigen Tools zur Steigerung der LLM-Leistung:
Guardrails ist ein Open-Source-Python-Paket, das Datenwissenschaftlern hilft, Struktur-, Typ- und Qualitätsprüfungen zu LLM-Ausgaben hinzuzufügen. Es behandelt automatisch Fehler und ergreift Maßnahmen, wie z. B. eine erneute Abfrage des LLM, wenn die Validierung fehlschlägt. Außerdem werden Garantien für Ausgabestrukturen und -typen wie JSON erzwungen.
Datenwissenschaftler benötigen ein Tool für die effiziente Indizierung, Suche und Analyse großer Datensätze. Hier kommt LlamaIndex ins Spiel. Das Framework bietet leistungsstarke Funktionen zum Verwalten und Extrahieren von Erkenntnissen aus umfangreichen Informationsspeichern.
Das DUST-Framework ermöglicht die Erstellung und Bereitstellung von LLM-basierten Anwendungen ohne Ausführungscode . Es hilft bei der Selbstprüfung der Modellausgaben, unterstützt iterative Designverbesserungen und verfolgt verschiedene Lösungsversionen.
Experimente verfolgen und Modellmetadaten verwalten
Datenwissenschaftler experimentieren, um ML-Modelle im Laufe der Zeit besser zu verstehen und zu verbessern. Sie benötigen Werkzeuge, um ein System einzurichten, das die Modellgenauigkeit und -effizienz auf der Grundlage realer Ergebnisse verbessert.
MLflow ist ein Open-Source-Kraftpaket, das sich zur Überwachung des gesamten ML-Lebenszyklus eignet. Es bietet Funktionen wie Experimentverfolgung, Modellversionierung und Bereitstellungsfunktionen. Mit dieser Suite können Datenwissenschaftler Experimente protokollieren und vergleichen, Metriken überwachen und ML-Modelle und Artefakte organisieren.
Comet ML ist eine Plattform zum Verfolgen, Vergleichen, Erklären und Optimieren von ML-Modellen und Experimente. Datenwissenschaftler können Comet ML mit Scikit-learn, PyTorch, TensorFlow oder HuggingFace verwenden – es liefert Erkenntnisse zur Verbesserung von ML-Modellen.
Amazon SageMaker deckt den gesamten Lebenszyklus des maschinellen Lernens ab. Es hilft dabei, Daten zu kennzeichnen und vorzubereiten sowie komplexe ML-Modelle zu erstellen, zu trainieren und bereitzustellen. Mit diesem Tool können Datenwissenschaftler Modelle schnell in verschiedenen Umgebungen bereitstellen und skalieren.
Microsoft Azure ML ist eine cloudbasierte Plattform, die dabei hilft, Arbeitsabläufe für maschinelles Lernen zu optimieren. Es unterstützt Frameworks wie TensorFlow und PyTorch und kann auch in andere Azure-Dienste integriert werden. Dieses Tool hilft Datenwissenschaftlern bei der Verfolgung von Experimenten, der Modellverwaltung und der Bereitstellung.
DVC (Datenversionskontrolle) ist ein Open-Source-Tool für die Verarbeitung großer Datensätze und Experimente zum maschinellen Lernen. Dieses Tool macht Data-Science-Workflows agiler, reproduzierbarer und kollaborativer. DVC arbeitet mit vorhandenen Versionskontrollsystemen wie Git zusammen und vereinfacht die Art und Weise, wie Datenwissenschaftler Änderungen verfolgen und Fortschritte bei komplexen KI-Projekten teilen.
ML-Workflows optimieren und verwalten
Datenwissenschaftler benötigen optimierte Arbeitsabläufe, um reibungslosere und effektivere Prozesse bei KI-Projekten zu erreichen. Die folgenden Tools können dabei helfen:
Prefect ist ein modernes Open-Source-Tool, mit dem Datenwissenschaftler Arbeitsabläufe überwachen und orchestrieren. Es ist leicht und flexibel und verfügt über Optionen zur Verwaltung von ML-Pipelines (Prefect Orion UI und Prefect Cloud).
Metaflow ist ein leistungsstarkes Tool zur Verwaltung von Arbeitsabläufen. Es ist für Datenwissenschaft und maschinelles Lernen gedacht. Es erleichtert die Konzentration auf die Modellentwicklung ohne den Aufwand der MLOps-Komplexität.
Kedro ist ein Python-basiertes Tool, das Datenwissenschaftlern dabei hilft, ein Projekt reproduzierbar, modular und leicht zu warten zu halten. Es wendet wichtige Prinzipien der Softwareentwicklung auf maschinelles Lernen an (Modularität, Trennung von Belangen und Versionierung). Dies hilft Datenwissenschaftlern beim Aufbau effizienter, skalierbarer Projekte.
Daten verwalten und Pipeline-Versionen steuern
ML-Workflows erfordern präzises Datenmanagement und Pipeline-Integrität. Mit den richtigen Tools behalten Datenwissenschaftler den Überblick über ihre Aufgaben und bewältigen selbst die komplexesten Datenherausforderungen souverän.
Pachyderm hilft Datenwissenschaftlern bei der Automatisierung der Datentransformation und bietet robuste Funktionen für Datenversionierung, Herkunft und End-to-End-Pipelines. Diese Funktionen können nahtlos auf Kubernetes ausgeführt werden. Pachyderm unterstützt die Integration mit verschiedenen Datentypen: Bilder, Protokolle, Videos, CSVs und mehrere Sprachen (Python, R, SQL und C/C). Es lässt sich skalieren, um Petabytes an Daten und Tausende von Jobs zu verarbeiten.
LakeFS ist ein Open-Source-Tool, das auf Skalierbarkeit ausgelegt ist. Es fügt der Objektspeicherung eine Git-ähnliche Versionskontrolle hinzu und unterstützt die Datenversionskontrolle im Exabyte-Bereich. Dieses Tool ist ideal für den Umgang mit umfangreichen Data Lakes. Datenwissenschaftler verwenden dieses Tool, um Data Lakes genauso einfach zu verwalten, wie sie mit Code umgehen.
ML-Modelle auf Qualität und Fairness testen
Datenwissenschaftler konzentrieren sich auf die Entwicklung zuverlässigerer Modelle und faire ML-Lösungen. Sie testen Modelle, um Verzerrungen zu minimieren. Die richtigen Tools helfen ihnen dabei, wichtige Kennzahlen wie Genauigkeit und AUC zu bewerten, Fehleranalysen und Versionsvergleiche zu unterstützen, Prozesse zu dokumentieren und sich nahtlos in ML-Pipelines zu integrieren.
Deepchecks ist ein Python-Paket, das dabei hilft mit ML-Modellen und Datenvalidierung. Es vereinfacht auch Modellleistungsprüfungen, Datenintegrität und Verteilungskonflikte.
Truera ist eine moderne Model-Intelligence-Plattform, die Datenwissenschaftlern dabei hilft, das Vertrauen und die Transparenz in ML-Modellen zu erhöhen. Mit diesem Tool können sie das Modellverhalten verstehen, Probleme identifizieren und Vorurteile reduzieren. Truera bietet Funktionen für Modell-Debugging, Erklärbarkeit und Fairnessbewertung.
Kolena ist eine Plattform, die die Teamausrichtung und das Vertrauen durch strenge Tests und Debugging verbessert. Es bietet eine Online-Umgebung zur Protokollierung von Ergebnissen und Erkenntnissen. Der Schwerpunkt liegt auf dem Testen und Validieren von ML-Einheiten im großen Maßstab, was der Schlüssel zu einer konsistenten Modellleistung in verschiedenen Szenarien ist.
Modelle zum Leben erwecken
Datenwissenschaftler benötigen zuverlässige Tools um ML-Modelle effizient einzusetzen und Vorhersagen zuverlässig zu liefern. Die folgenden Tools helfen ihnen dabei, reibungslose und skalierbare ML-Vorgänge zu erreichen:
BentoML ist eine offene Plattform, die Datenwissenschaftler bei der Abwicklung von ML-Vorgängen in der Produktion unterstützt. Es trägt dazu bei, die Modellverpackung zu optimieren und die Arbeitslast für die Bereitstellung effizienter zu gestalten. Es hilft auch bei der schnelleren Einrichtung, Bereitstellung und Überwachung von Vorhersagediensten.
Kubeflow vereinfacht die Bereitstellung von ML-Modellen auf Kubernetes (lokal, lokal oder in der Cloud). Mit diesem Tool wird der gesamte Prozess unkompliziert, portabel und skalierbar. Es unterstützt alles von der Datenvorbereitung bis zur Vorhersagebereitstellung.
Vereinfachen Sie den ML-Lebenszyklus mit End-to-End-MLOps-Plattformen
End-to-End-MLOps-Plattformen sind für die Optimierung des maschinellen Lernlebenszyklus unerlässlich und bieten einen optimierten Ansatz zur effektiven Entwicklung, Bereitstellung und Verwaltung von ML-Modellen. Hier sind einige führende Plattformen in diesem Bereich:
Amazon SageMaker bietet eine umfassende Schnittstelle, die Datenwissenschaftlern bei der Bewältigung des gesamten ML-Lebenszyklus hilft. Es rationalisiert die Datenvorverarbeitung, das Modelltraining und das Experimentieren und verbessert die Zusammenarbeit zwischen Datenwissenschaftlern. Mit Funktionen wie integrierten Algorithmen, automatisierter Modelloptimierung und enger Integration mit AWS-Diensten ist SageMaker die erste Wahl für die Entwicklung und Bereitstellung skalierbarer Lösungen für maschinelles Lernen.
Microsoft Azure ML Platform erstellt eine kollaborative Umgebung, die verschiedene Programmiersprachen und Frameworks unterstützt. Es ermöglicht Datenwissenschaftlern, vorgefertigte Modelle zu verwenden, ML-Aufgaben zu automatisieren und sich nahtlos in andere Azure-Dienste zu integrieren, was es zu einer effizienten und skalierbaren Wahl für cloudbasierte ML-Projekte macht.
Google Cloud Vertex AI bietet eine nahtlose Umgebung sowohl für die automatisierte Modellentwicklung mit AutoML als auch für das benutzerdefinierte Modelltraining mit gängigen Frameworks. Integrierte Tools und einfacher Zugriff auf Google Cloud-Dienste machen Vertex AI ideal für die Vereinfachung des ML-Prozesses und helfen Data-Science-Teams, Modelle mühelos und in großem Maßstab zu erstellen und bereitzustellen.
Abmelden
MLOps ist nicht nur ein weiterer Hype. Es handelt sich um einen wichtigen Bereich, der Fachleuten hilft, große Datenmengen schneller, genauer und einfacher zu trainieren und zu analysieren. Wir können uns nur vorstellen, wie sich dies in den nächsten zehn Jahren entwickeln wird, aber es ist klar, dass KI, Big Data und Automatisierung gerade erst an Fahrt gewinnen.
Das obige ist der detaillierte Inhalt vonMLOps: So erstellen Sie ein Toolkit zur Steigerung der KI-Projektleistung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- PHP-Schulungseinrichtungen vermitteln verschiedene Frameworks
- Welche Ausbildungsstätten für PHP-Softwareentwickler gibt es?
- Microsoft veröffentlicht ein neues, leichtes, verifiziertes Windows 11-Betriebssystem, das bei Ihnen möglicherweise nicht funktioniert
- Win7-Bilddatei Download-Adresse des offiziellen Microsoft-Website-Systems
- Die Apple Watch Series 9 und Ultra 2 erhöhen den Speicherplatz deutlich um das Zweifache