
Heim >Java >javaLernprogramm >Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel
Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-08-28 12:01:04635Durchsuche
In diesem Artikel untersuchen wir zwei Methoden zum Entfernen doppelter Elemente aus einem Stapel in Java. Wir vergleichen einen unkomplizierten Ansatz mit „verschachtelten Schleifen“ und eine effizientere Methode mit einem HashSet. Das Ziel besteht darin, zu zeigen, wie die Duplikatentfernung optimiert werden kann, und die Leistung jedes Ansatzes zu bewerten.
Problemstellung
Schreiben Sie ein Java-Programm, um das doppelte Element aus dem Stapel zu entfernen.
Eingabe
Stack<Integer> data = initData(10L);
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Naive Approach: 18200 nanoseconds
Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Optimized Approach: 34800 nanoseconds
Um Duplikate aus einem bestimmten Stapel zu entfernen, haben wir zwei Ansätze −
Naiver Ansatz: Erstellen Sie zwei
- verschachtelte Schleifen
- , um zu sehen, welche Elemente bereits vorhanden sind, und um zu verhindern, dass sie zur Ergebnisstapelrückgabe hinzugefügt werden. HashSet-Ansatz: Verwenden Sie ein Set, um eindeutige Elemente zu speichern, und nutzen Sie dessen O(1)-Komplexität
- , um zu überprüfen, ob ein Element vorhanden ist oder nicht. Zufällige Stapel generieren und klonen
Unten ist dargestellt, wie das Java-Programm zunächst einen zufälligen Stapel erstellt und dann ein Duplikat davon zur weiteren Verwendung erstellt −
private static Stack initData(Long size) {
Stack stack = new Stack < > ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack < Integer > manualCloneStack(Stack < Integer > stack) {
Stack < Integer > newStack = new Stack < > ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
hilft beim Erstellen eines Stapels mit einer bestimmten Größe und zufälligen Elementen im Bereich von 1 bis 100.initData
hilft beim Generieren von Daten, indem Daten von einem anderen Stapel kopiert und für den Leistungsvergleich zwischen den beiden Ideen verwendet werden.manualCloneStack
Entfernen Sie Duplikate aus einem bestimmten Stapel mit dem naiven Ansatz
Im Folgenden finden Sie die Schritte zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe des naiven Ansatzes −
Starten Sie den Timer.
- Erstellen Sie einen leeren Stapel, um einzigartige Elemente zu speichern.
- Iterieren Sie mit der while-Schleife und fahren Sie fort, bis der ursprüngliche Stapel leer ist. Öffnen Sie das oberste Element.
- Suchen Sie mit resultStack.contains(element)
- nach Duplikaten, um zu sehen, ob sich das Element bereits im Ergebnisstapel befindet. Wenn sich das Element nicht im Ergebnisstapel befindet, fügen Sie es dem Ergebnisstapel hinzu.
- Notieren Sie die Endzeit und berechnen Sie die insgesamt aufgewendete Zeit.
- Ergebnis zurückgeben
- Beispiel
Unten finden Sie das Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe des naiven Ansatzes −
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack < > ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
Für den naiven Ansatz verwenden wir
<code>while (!stack.isEmpty())</code>, um die erste Schleife zu verarbeiten, um alle Elemente im Stapel zu durchlaufen, und die zweite Schleife dient dazu,
zu prüfen, ob das Element bereits vorhanden ist.
Duplikate aus einem bestimmten Stapel mithilfe des optimierten Ansatzes (HashSet) entfernen
<pre class="brush:php;toolbar:false">resultStack.contains(element)</pre>
Im Folgenden finden Sie die Schritte zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe eines optimierten Ansatzes −
Starten Sie den Timer
- Erstellen Sie einen Satz, um gesehene Elemente zu verfolgen (für O(1)-Komplexitätsprüfungen).
- Erstellen Sie einen temporären Stapel, um einzigartige Elemente zu speichern.
- Iterieren Sie mit der while-Schleife
- und fahren Sie fort, bis der Stapel leer ist. Entfernen Sie das oberste Element vom Stapel.
- Um die Duplikate zu überprüfen, verwenden wir seen.contains(element)
- , um zu prüfen, ob das Element bereits im Set vorhanden ist. Wenn das Element nicht im Set enthalten ist, fügen Sie es sowohl zum sichtbaren als auch zum temporären Stapel hinzu.
- Notieren Sie die Endzeit und berechnen Sie die insgesamt aufgewendete Zeit.
- Geben Sie das Ergebnis zurück
- Beispiel
Unten finden Sie das Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe von HashSet −
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start));
return tempStack;
}
Für eine optimierte Vorgehensweise verwenden wir
Um eindeutige Elemente in einem Set zu speichern, nutzen Sie dieO(1)-Komplexität
beim Zugriff auf ein zufälliges Element, um den Berechnungsaufwand für die Prüfung, ob ein Element vorhanden ist oder nicht, zu reduzieren.Beide Ansätze zusammen nutzen
Im Folgenden finden Sie die Schritte zum Entfernen von Duplikaten aus einem bestimmten Stapel mit beiden oben genannten Ansätzen:
Daten initialisieren: Wir verwenden die Methode
- initData(Long size)
- , um einen Stapel mit zufälligen Ganzzahlen zu erstellen.
Klonen Sie den Stapel. Wir verwenden die Methode cloneStack(Stack stack) - , um eine exakte Kopie des ursprünglichen Stapels zu erstellen. Generieren Sie den ersten Stapel mit initData
- . Klonen Sie diesen Stapel mit cloneStack
- . Wenden Sie den naiven Ansatz
- an, um Duplikate aus dem Originalstapel zu entfernen. Wenden Sie den optimierten Ansatz
- an, um Duplikate aus dem geklonten Stapel zu entfernen. Zeigen Sie die für jede Methode benötigte Zeit und die einzigartigen Elemente an, die durch beide Ansätze erzeugt werden
Beispiel
Unten finden Sie das Java-Programm, das mit beiden oben genannten Ansätzen doppelte Elemente aus einem Stapel entfernt –
<code>Set<Integer> seen</code>Ausgabe
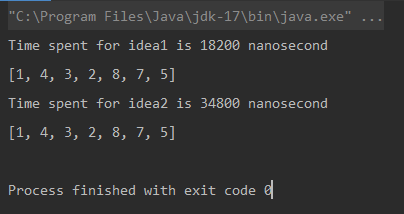
Vergleich
* Die Maßeinheit ist Nanosekunde.
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| Method | 100 elements | 1000 elements |
10000 elements |
100000 elements |
1000000 elements |
| Idea 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idea 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
As observed, the time running for Idea 2 is shorter than for Idea 1 because the complexity of Idea 1 is O(n²), while the complexity of Idea 2 is O(n). So, when the number of stacks increases, the time spent on calculations also increases based on it.
Das obige ist der detaillierte Inhalt vonJava-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Java-Implementierung zum Abrufen von Dateityp und -erweiterung
- 4 empfohlene Artikel über Kombinationsoperationen
- 10 empfohlene Artikel über endgültige Modifikatoren
- Detaillierte Einführung in den Heapspeicher
- Nachdem ich den Blog des Masters über die Veröffentlichung des Webprojekts von Alibaba Cloud gelesen hatte, stellte ich fest, dass es ein Problem mit der Stack-Bereitstellung gibt und ich es lösen muss.